







 本文总结了小样本目标检测的基础,包括定义、训练过程、迁移学习和元学习两种经典范式,探讨了域偏移、数据偏差等挑战,并提出了注意力机制、图卷积神经网络等研究方向。
本文总结了小样本目标检测的基础,包括定义、训练过程、迁移学习和元学习两种经典范式,探讨了域偏移、数据偏差等挑战,并提出了注意力机制、图卷积神经网络等研究方向。
少样本目标检测基础总结
文章目录
1.定义和训练过程
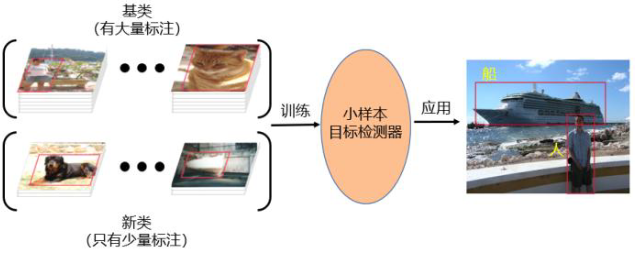
小样本目标检测(Few-shot Object Detection,FSOD)相对于通用目标检测最大的不同,是其数据输入的不同,FSOD 将数据集分为基类数据集 D 𝑏 D_𝑏 Db 和新类数据集 D n D_n Dn 。基类数据集 D 𝑏 D_𝑏 Db 由拥有大量标注图像的基类 𝐶 𝑏 𝐶_𝑏 Cb 组成,新类数据集𝐷𝑛 由只有少量标注图像的新类 𝐶 n 𝐶_n Cn 组成,其中,基类类别和新类类别不存在交集,即 𝐶 𝑏 𝐶_𝑏 Cb ∩ 𝐶 n 𝐶_n Cn= ϕ \phi ϕ。其目标是通过在基类和新类数据集上训练得到一个模型,期待该模型可以检测出任意给定测试图像中的新类和基类对象。
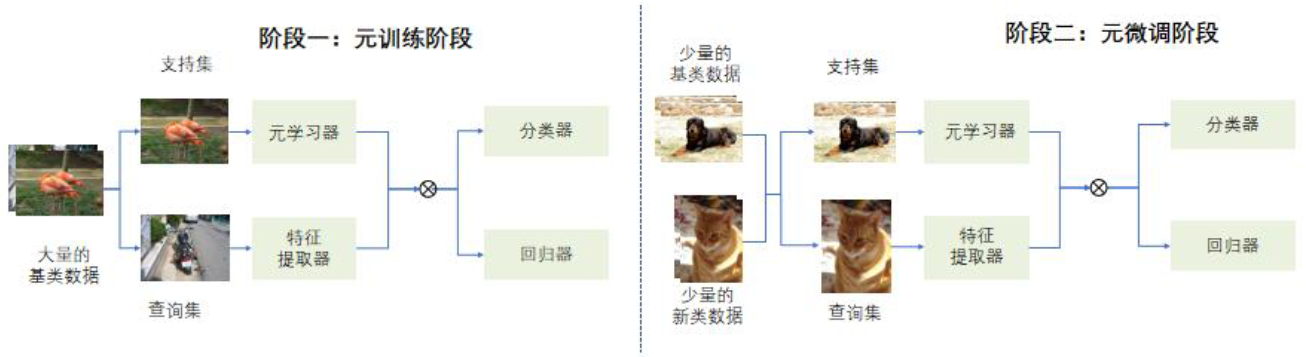
其定义如图1所示
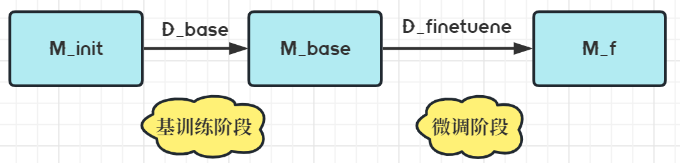
- 第一阶段使用大量的基类数据 𝐷 b a s e 𝐷_{base} Dbase进行模型的训练,从初始化模型 𝑀 𝑖 𝑛 𝑖 𝑡 𝑀_{𝑖𝑛𝑖𝑡} Minit得到基模型 𝑀 b a s e 𝑀_{base} Mbase,称之为基训练阶段;
- 第二阶段使用由少量的基类数据 𝐷 b a s e 𝐷_{base} Dbase和新类数据 𝐷 𝑛 𝑜 𝑣 𝑒 𝑙 𝐷_{𝑛𝑜𝑣𝑒𝑙} Dnovel组成的平衡数据集 𝐷 𝑓 𝑖 𝑛 𝑒 𝑡 𝑢 𝑛 𝑒 𝐷_{𝑓𝑖𝑛𝑒𝑡𝑢𝑛𝑒} Dfinetune对基模型 𝑀 𝑏 𝑎 𝑠 𝑒 𝑀_{𝑏𝑎𝑠𝑒} Mbase进行模型微调,得到最终模型 𝑀 f 𝑀_{f} Mf,称之为微调阶段
其训练过程如图2所示
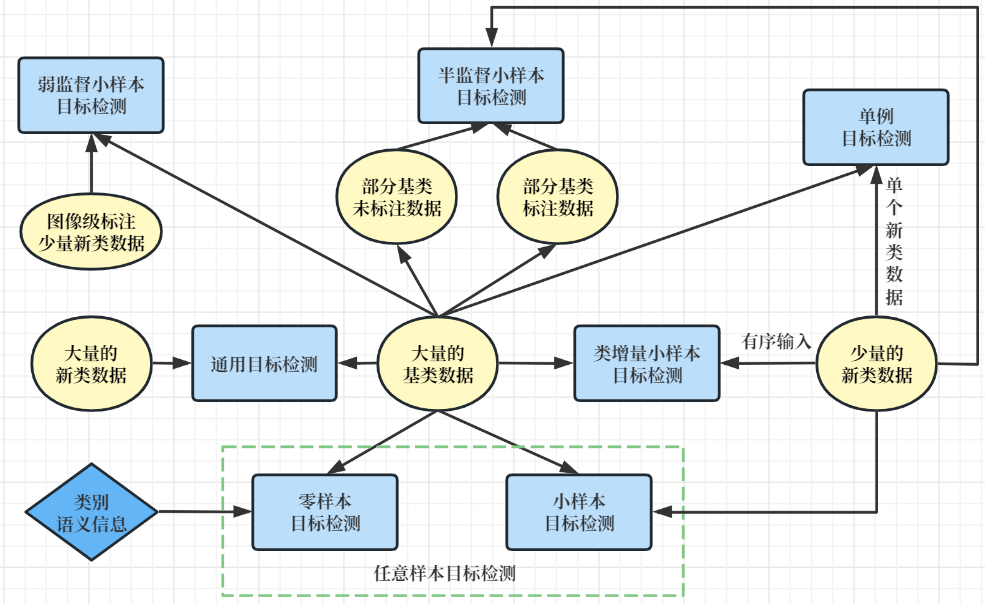
2.相关研究
- 弱监督
- 半监督
- 类增量
- 零样本
- 单例
3.两类经典范式
3.1 基于迁移学习
定义:基于迁移学习的范式是将从已知类中学习到的知识迁移到未知类的检测任务中。
Baseline:两阶段微调方法(Two-stage Fine-tuning Approach,TFA)是迁移学习范式的基线方法,基于Faster R-CNN算法进行改进。
Wang, Xin, et al. “Frustratingly simple few-shot object detection.” arXiv preprint arXiv:2003.06957 (2020).
思路:Faster R-CNN 主干网络是类无关的,特征信息可以很自然的从基类迁移到新类上,仅仅只需要微调检测器的最后一层(包含类别分类和边界框回归),就可以达到远远超过之前方法的性能表现。
实现:整个方法分为基训练和微调两个阶段
- 在基训练阶段,整个模型在有着大量标注的基类上训练;
- 在微调阶段,冻结网络前期的参数权重,由基类和新类组成的平衡子集对顶层的分类器和回归器进行微调
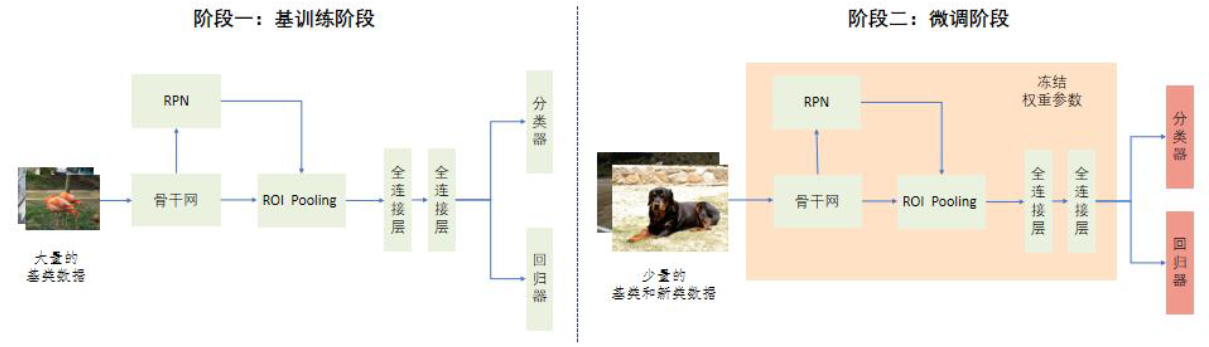
Attention:
- TFA 在微调阶段的分类器上采用余弦相似性测量候选框和真实类别边界框之间的相似性;
- 由于小样本中每个新类别的样本量非常少,其高方差可能会导致检测结果的不可靠,TFA 通过抽样多组训练样本进行评估,并且在不同组进行多次实验得到平均值
3.2 基于元学习
定义:基于元学习的范式是利用元学习器从不同的任务中学习元知识,然后对包含有新类的任务通过元知识的调整完成对新类的检测。
一张图像中可能存在多个感兴趣对象,在小样本模型训练中只需要标注支持集中基类的边界框即可。
元学习范式有两种标注方法:
- 将支持集裁剪为只包含目标实例的图像;
- 在表示图像的RGB三通道外,再添加一个掩码通道组成四通道,第四通道使用数字1标注出感兴趣对象的边界框,其他位置用0填充
Baseline:Few-shot object detection via feature reweighting(FSRW)
Kang, Bingyi, et al. “Few-shot object detection via feature reweighting.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
实现:基于一阶段网络YOLOv2改进。具体来说,在一阶段网络中新增了元特征学习器和元学习器模块。
- 元特征学习器以查询图像为输入,使用YOLOv2的骨干实现,从有充足样本的基类图像中提取具有泛化性的元特征,用于之后检测新类;
- 元学习器模块以支持集为输入,将新类的某一类别实例转换为一个全局向量,该向量用来检测特定类别的对象实例
网络的训练过程同样分两阶段完成,首先使用基类数据训练连同元学习器模块在内的整个网络模型,然后由少量标注的新类和基类组成的平衡数据集微调模型以适应新类。
3.3 两种范式对比
相同点
- 数据集都分为有大量标注的基类数据和只有少量标注的新类数据;
- 训练过程都分为两阶段进行,分别是基训练阶段和微调阶段,算法模型在基训练阶段学习到基类数据具有泛化性的知识,然后在新类数据上对模型进行微调,达到检测新类的目的;
- 评价指标相同
不同点
- 数据的输入方式不同,元学习范式是以任务(episode) 为输入单元,每个任务由支持集图像和查询集图像组成,目的是找到查询集图像中属于支持集类别的目标对象,而迁移学习范式通常不需要分为支持集和查询集两部分;
- 元学习范式除了通用目标检测模型外,还有一个需要获得类别级元知识的元学习器,而迁移学习范式只需要在通用目标检测模型上改进即可;
- 元学习范式随着支持集中类别数量的增加,内存利用率会降低,而迁移学习范式不会随着类别数量的增加而使内存利用率降低
4.存在的问题
4.1 域偏移
很多FSOD方法利用大规模数据集来学习generic notions(通用知识),然后通过迁移/微调以满足新任务需求。但在某些情况下,源域和目标域之间共享的跨域知识很少,即存在较大的域偏移,从源域学习到的“通用”知识对目标任务仅产生微弱的影响甚至负面影响。
e.g.很多paper认为RPN是一种可以为所有前景类生成高质量RoIs的理想的proposal algorithm,但是前景类是特定于任务的,而其他类则被定义为负类。因此,这种class-agnostic(类不可知) 的RPN无法为新类提供像基类那样好的RoIs,特别是在有较大域偏移的情况下。
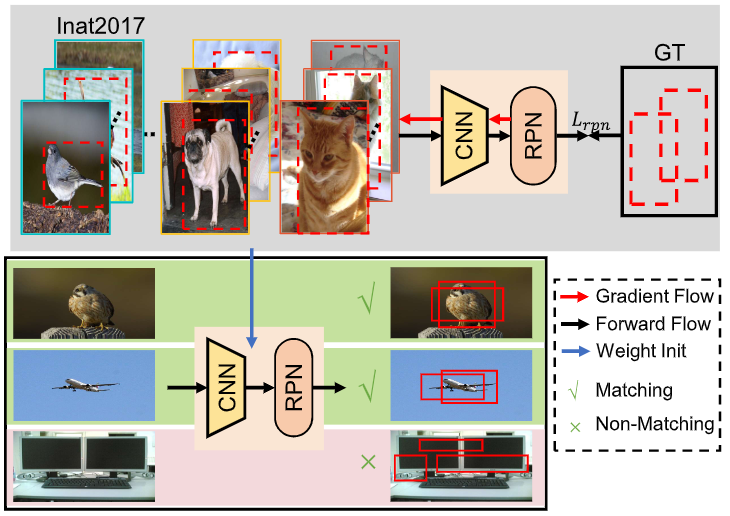
图6展示了较大和较小域偏移下RPN的性能。Backbone和RPN都是在仅有动物和植物类别的inat2017数据集上进行了预训练。
- 鸟是inat中的一个类,故RPN生成了较好的建议框;
- 虽然飞机不是inat中的类,但其和鸟具有类似的视觉特征,故RPN也生成了较好的建议框;
- TV和inat2017数据集具有较大的域差异,故RPN生成了较差的建议框
4.2 数据偏差
数据集的本质:特定分布的观察样本的集合
现实中,会存在一种现象,即较大的类内偏差
⇒
\Rightarrow
⇒ 决策边界模糊。不同于大规模数据集,小规模数据集不可能覆盖所有情况,故其在尺度,上下文,类内多样性等方面具有更大的数据偏差。
基于神经网络的算法易受到噪声/偏差的影响,而导致使用非鲁棒知识来做决策,即过拟合。特别是,基于度量学习的方法需要利用训练集来学习一组鲁棒的类别原型作为特定任务的参数。当训练集有很多异常值(如遮挡)时,难以建立鲁棒的类别原型。
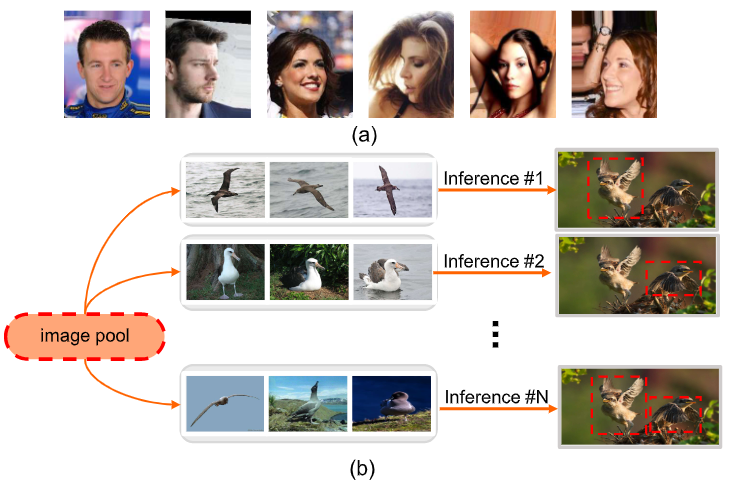
图7中(a)列出了数据偏差的几个例子,e.g.存在噪声背景和姿势变化;(b)说明了数据偏差的不利影响,从图像池中采样的训练图像的质量会严重影响最终的检测性能。
4.5 不完整标注
问题:在
𝐷
b
a
s
e
𝐷_{base}
Dbase上训练时,模型可能会将新类目标视为负样本,并学习抑制这些目标,这其实对于检测新类目标是有害的。
对策:可以将问题视为一个半监督问题。
Li, Yiting, et al. “Few-shot object detection via classification refinement and distractor retreatment.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
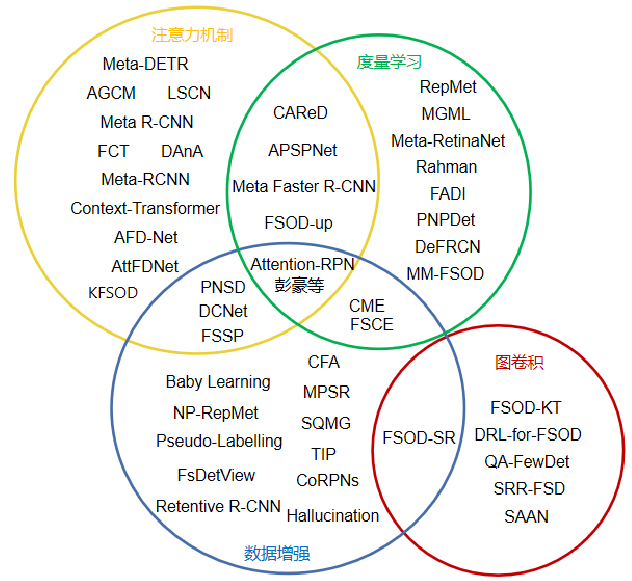
5.研究(改进)方向

















 134
134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









