







You Only Segment Once: Towards Real-Time Panoptic Segmentation
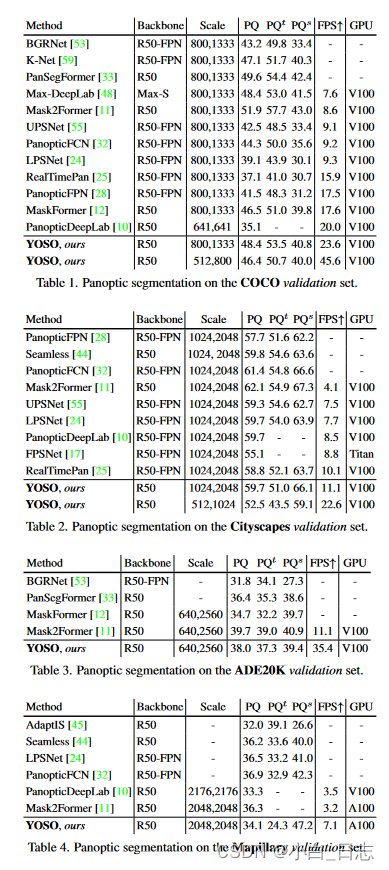
摘要: 在这篇论文中,提出了YOSO,一个实时的全景分割框架。YOSO通过全景内核与图像特征图之间的动态卷积来预测掩码,只需要一次分割就可以同时完成实例分割和语义分割任务。为了降低计算开销,设计了一个特征金字塔聚合器来提取特征图,以及一个用于全景核生成的可分离动态解码器。聚合器以卷积为主的方式重新参数化了插值优先模块,这显著加速了管道的速度,而没有额外的成本。解码器通过可分离动态卷积执行多头交叉注意力,以提高效率和准确性。YOSO是第一个实时全景分割框架,与最先进的模型相比,它能够提供竞争性的性能。具体来说,YOSO在COCO上实现了46.4的PQ,45.6的FPS;在Cityscapes上实现了52.5的PQ,22.6的FPS;在ADE20K上实现了38.0的PQ,35.4的FPS;在Mapillary Vistas上实现了34.1的PQ,7.1的FPS。
引言:
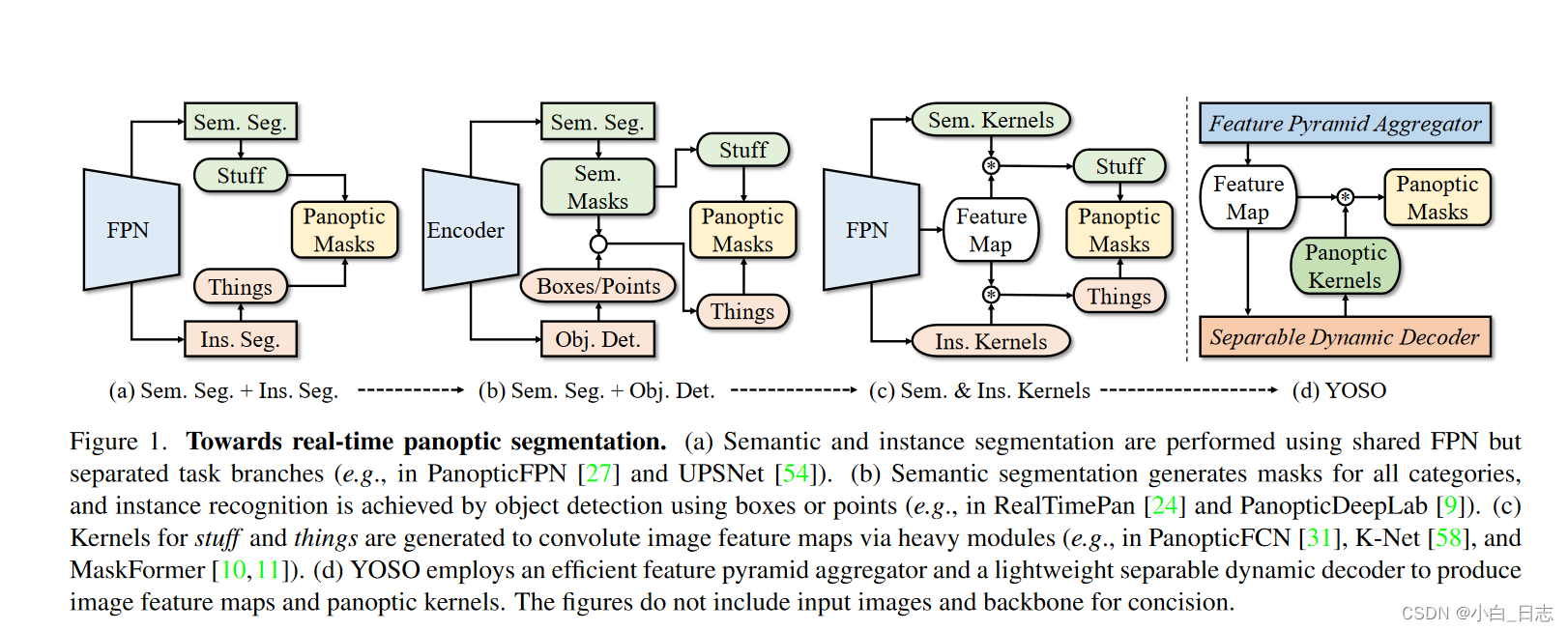
1、实现实时全景分割的主要挑战之一是需要单独的计算密集型分支来分别执行语义和实例分割。通常,实例分割使用框或点来区分不同的事物,而语义分割则预测事物语义类别上的分布图。
2、YOSO只需要对背景和前景事物的掩码进行一次分割。
3、设计了一个高效的用于提取特征的特征金字塔聚合器以及一个用于生成全景内核的可分离动态解码器。
4、在聚合器中,使用卷积优先聚合 (CFA) 来重新参数化插值优先聚合 (IFA),从而在不影响性能的情况下将 GPU 延迟加速约 2.6 倍。
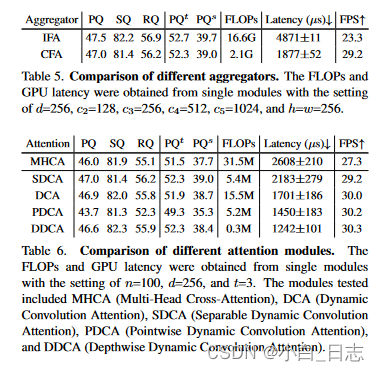
5、在解码器中,使用可分离动态卷积注意(SDCA)以权重共享的方式执行多头交叉注意。与传统的多头交叉注意力相比,SDCA 实现了更好的精度(+1.0 PQ)和更高的效率(GPU 延迟快约 1.2 倍)。
6、YOSO具有三个显着的优势。(1)CFA 减少了计算负担,而无需重新训练模型或影响性能。 CFA 可以适用于任何使用双线性插值和 1×1 卷积运算组合的任务。(2)SDCA 以更好的精度和效率执行多头交叉注意力。(3)与最先进的全景分割模型相比,YOSO 运行速度更快,并且具有具有竞争力的准确性,并且其泛化能力在四个流行数据集上得到了验证:COCO(46.4 PQ,45.6 FPS)、Cityscapes(52.5 PQ,22.6 FPS)、 ADE20K(38.0 PQ,35.4 FPS)和Mapillary Vistas(34.1 PQ,7.1 FPS)。
方法:
1、Task Formulation
统一全景分割(Unified Panoptic Segmentation)。全景分割将图像的每个像素映射到语义类和实例标识。提出了一种统一的方法,将前景类和背景类的集合视为单个实体。为了实现这一目标,对输入图像预测 n 个二值掩码 M ∈ Bn×h×w,其类概率为 L ∈ Rn×l,其中 (h, w) 表示掩码分辨率,l 是类别总数。在训练期间,使用预测损失集将预测与相应的地面真实标签进行匹配。在测试时,分割结果根据前景(即,事物)和背景(即,东西)类进行合并。具体来说,通过并集操作将同一背景类对应的掩模进行合并;具有前景类的掩码被视为独立实例;如果一个像素属于多个类,则将概率最高的类分配给该像素。
YOSO框架(YOSO Framework)。YOSO是一个专为实时全景分割而设计的紧凑框架,由特征金字塔聚合器和可分离的动态解码器组成。主干网络,例如 ResNet ,从输入图像中提取多级特征图。特征金字塔聚合器将多级特征图压缩并聚合为单级。然后,可分离动态解码器生成带有单级特征图的全景内核,用于掩模预测和分类。
2、特征金字塔聚合器(Feature Pyramid Aggregator,FPA)
可变形特征金字塔(Deformable Feature Pyramid)。给定主干提取的多级特征图 C2、C3、C4、C5,利用可变形特征金字塔网络来增强不同尺度的特征图。首先应用 1×1 卷积层来压缩多级特征图的通道。然后,从 C3 到 C5 的特征图被输入可变形卷积网络(DCN)并逐级上采样,产生金字塔特征图 P 2 ∈ Rc2×h×w,P 3 ∈ Rc3×h/2×w /2、P 4 ∈ Rc4×h/4×w/4、P 5 ∈ Rc5×h/8×w/8,其中c2、c3、c4、c5表示通道维度,h、w表示输入图像的 1/4 比例。获得金字塔特征图后,我们探索了两种聚合方法,即插值优先聚合(IFA)和卷积优先聚合(CFA)来合并多级特征图。
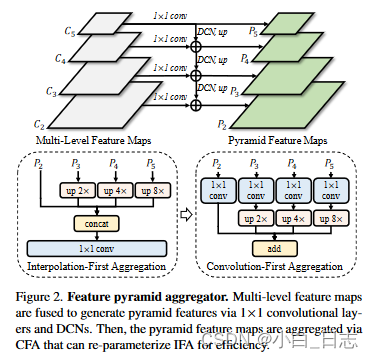
插值/卷积优先聚合(Interpolation/Convolution-First Aggregation,CFA / IFA)。在 IFA 中,金字塔特征图首先通过双线性插值上采样到 h × w 的尺度。然后,使用 1×1 卷积层连接和融合特征图。在 CFA 中,金字塔特征图首先被馈送到不同的 1×1 卷积层。然后,将特征图双线性插值到 h × w 的尺度并求和。
Observation I :当使用无偏差的 1×1 卷积时,IFA 的输出与 CFA 的输出完全相等。
Observation II::CFA 所需的浮点运算 (FLOP) 明显少于 IFA。
综上两个观察,本文在提出的特征金字塔聚合器中采用了CFA。值得注意的是,IFA中1×1卷积层的学习权重可以轻松地通过将权重分为四个1×1卷积层来重新参数化为CFA,这可以加速管道而不产生任何额外的成本。
3、可分离动态解码器
相比于之前的研究,本文提出了一种可分离动态解码器的轻量级内核生成器,它可以加快内核生成速度,同时保持高精度。其由三个模块组成:预注意模块、可分离动态卷积模块和后注意模块。具体来说,可分离动态卷积有效地执行多头交叉注意力并获得更好的精度。
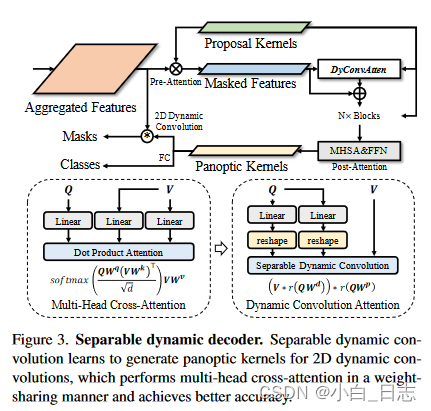
预注意力模块有选择地从聚合特征图中提取关键信息,以使提案内核多样化。
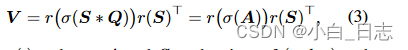
增加模型容量可以提高性能,但也会导致较高的计算负担。(具体方式见论文)可分离动态卷积公式
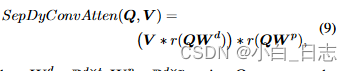
后注意力。在后注意模块中,我们使用多头自注意层和前馈网络来生成全景内核。随后,我们通过 2D 卷积生成掩模,并使用附加前馈网络预测相关类别。本文利用全景内核迭代更新提案内核以提高准确性。
实验见论文
















 3331
3331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









