






样本不均匀
在很多真实场景下,数据集往往是不平衡的。也就是说,在数据集中,有一类含有的数据要远远多于其他类的数据(类别分布不平衡)。在贷款场景下,我们主要介绍二分类中的类别不平衡问题。
常识告诉我们一家信用正常客户的数据要远远多于欺诈客户的。
考虑一个简单的例子,10万正样本(正常客户标签为0)与1000个负样本(欺诈客户标签为1),正负样本比列为100:1,如果直接带入模型中去学习,每一次梯度下降如果使用全量样本,负样本的权重只有不到1/100,即使完全不学习负样本的信息,准确率也有超过99%,所以显然我们绝不能以准确率来衡量模型的效果。但是实践下面,我们其实也知道,即使用KS或者AUC来度量模型的表现,依然没法保证模型能将负样本很好的学习。而我们实际上需要得到一个分类器,既能对于正例有很高的准确率,同时又不会影响到负例的准确率。
类似于上面例子中的数据集,由于整个数据空间中,正例和负例的数据就是不平衡的。因此,这样的不平衡数据集的产生往往是内在的。同时,也有很多其他的因素会造成数据的不平衡,例如,时间,存储等。由于这些原因产生不平衡的数据集往往被称为外在的。除了数据集的内在和外在,我们可能还要注意到数据集的相对不平衡以及绝对不平衡。假设上述例子中的数据集有100000条数据,负例和正例的比例为100:1,只包含1000个正例。明显的,我们不能说1000个数据就是绝对小的,只不过相对于负例来说,它的数量相对较少。因此,这样的数据集被认为是相对不平衡的。
解决方法
- 下探
- 半监督学习
- 标签分裂
- 代价敏感
- 采样算法
下探
最直接解决风控场景样本不均衡的方法。
所谓下探,就是对评分较低被拒绝的人进行放款,牺牲一部分收益,来积累坏样本,供后续模型学习。
这也是所有方法中最直接有效的。但是不是每一家公司都愿意承担这部分坏账。
此外我们之前提到过,随着业务开展,后续模型迭代的时候,使用的样本是有偏的,下探同样可以解决这个问题。
半监督学习
将被拒绝客户的数据通过半监督的方法逐渐生成标签,然后带入模型中进行训练。比较典型分方法有拒绝演绎、暴力半监督等等。
1)拒绝演绎
拒绝演绎或者叫拒绝推断,是一种根据经验对低分客户进行百分比采样的方法。
比如最低分的客群百分之五十视为坏人,其次百分之四十等等。
效果没有下探好。但不用额外有任何开销。
参考资料:群内预习资料中的《信用风险评分卡研究》第十三章。
2)暴力半监督
比较粗暴的做法是将样本的每一种标签方式进行穷举,带入模型看对模型是否有帮助,效率较低,容易过拟合。
3)模型筛选
用训练过的其他模型对无标签样本打标签,然后模型进行训练。很多公司会用当前模型在上面做预测,然后带入模型继续训练。很不推荐这样做,效果一般是很差的。可以考虑无监督算法或者用很旧的样本做训练然后做预测。
标签分裂
我们有时候会不止使用传统的逾期或者rollrate来定义好坏。而是通过一些聚类手段对数据进行切分,然后分别在自己的样本空间内单独学习。基于模型的比如kmeans,分层聚类等等。基于经验的比如将失联客户、欺诈客户拆开,单独建模。
为什么要这样做呢?我们看一个例子。
小明生了慢粒白血病,她的失散多年的哥哥找到有2家比较好的医院,医院A和医院B供小明选择就医。
小明的哥哥多方打听,搜集了这两家医院的统计数据,它们是这样的:
医院A最近接收的1000个病人里,有900个活着,100个死了。
医院B最近接收的1000个病人里,有800个活着,200个死了。
作为对统计学懵懵懂懂的普通人来说,看起来最明智的选择应该是医院A对吧,病人存活率很高有90%啊!总不可能选医院B吧,存活率只有80%啊。
呵呵,如果小明的选择是医院A,那么她就中计了。
就这么说吧,如果医院A最近接收的1000个病人里,有100个病人病情很严重,900个病人病情并不严重。
在这100个病情严重的病人里,有30个活下来了,其他70人死了。所以病重的病人在医院A的存活率是30%。
而在病情不严重的900个病人里,870个活着,30个人死了。所以病情不严重的病人在医院A的存活率是96.7%。
在医院B最近接收的1000个病人里,有400个病情很严重,其中210个人存活,因此病重的病人在医院B的存活率是52.5%。
有600个病人病情不严重,590个人存活,所以病情不严重的病人在医院B的存活率是98.3%。
画成表格,就是这样的——
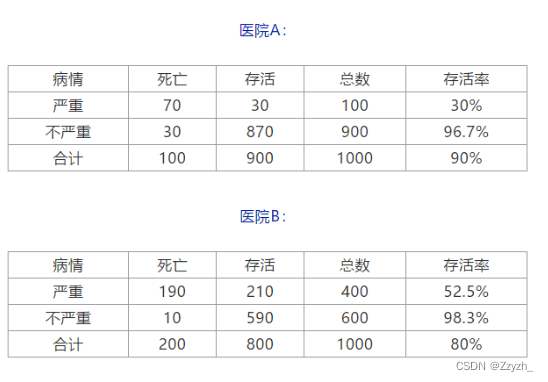
你可以看到,在区分了病情严重和不严重的病人后,不管怎么看,最好的选择都是医院B。但是只看整体的存活率,医院A反而是更好的选择了。所谓远看是汪峰,近看白岩松,就是这个道理。
实际上,我们刚刚看到的例子,就是统计学中著名的黑魔法之一——辛普森悖论(Simpson’s paradox)。辛普森悖论就是当你把数据拆开细看的时候,细节和整体趋势完全不同的现象。
代价敏感学习
代价敏感学习则是利用不同类别的样本被误分类而产生不同的代价,使用这种方法解决数据不平衡问题。而且有很多研究表明,代价敏感学习和样本不平衡问题有很强的联系,并且使用代价敏感学习的方法解决不平衡学习问题要优于使用随机采样的方法。
- 把误分类代价作为数据集的权重,然后采用 Bootstrap 采样方法选择具有最好的数据分布的数据集;
- 以集成学习的模式来实现代价最小化的技术,这种方法可以选择很多标准的学习算法作为集成学习中的弱分类器;
- 把代价敏感函数或者特征直接合并到分类器的参数中,这样可以更好的拟合代价敏感函数。由于这类技术往往都具有特定的参数,因此这类方法没有统一的框架;
采样算法
今天我们涉及的主要是过采样方法
- 朴素随机过采样
- SMOTE
朴素随机过采样
from sklearn.datasets import make_classification
from collections import Counter
X, y = make_classification(n_samples=5000, n_features=2, n_informative=2,
n_redundant=0, n_repeated=0, n_classes=2,
n_clusters_per_class=1,
weights=[0.01, 0.99],
class_sep=0.8, random_state=0)
Counter(y)
Counter({1: 4923, 0: 77})
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=0)
X_resampled, y_resampled = ros.fit_sample(X, y)
sorted(Counter(y_resampled).items())
[(0, 4923), (1, 4923)]
SMOTE
SMOTE: 对于少数类样本a, 随机选择一个最近邻的样本b, 然后从a与b的连线上随机选取一个点c作为新的少数类样本;
但是,SMOTE容易出现过泛化和高方差的问题,而且,容易制造出重叠的数据。
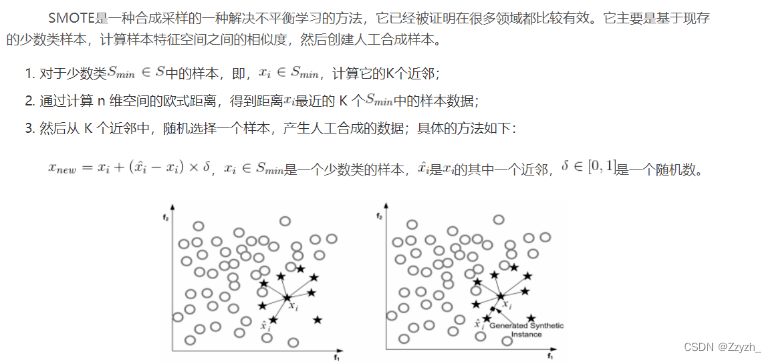
为了克服SMOTE的缺点,Adaptive Synthetic Sampling方法被提出,主要包括:Borderline-SMOTE和Adaptive Synthetic Sampling(ADA-SYN)算法。
Borderline-SMOTE:对靠近边界的minority样本创造新数据。其与SMOTE的不同是:SMOTE是对每一个minority样本产生综合新样本,而Borderline-SMOTE仅对靠近边界的minority样本创造新数据。如下图,只对A中的部分数据进行操作:

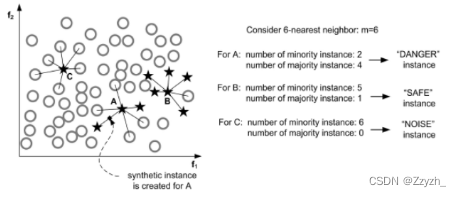
这个图中展示了该方法的实现过程,我们可以发现和SMOTE方法的不同之处:
SMOTE对于每一个少数类样本都会产生合成样本,但是Borderline-SMOTE只会对邻近边界的少数类样本生成合成数据。















 1829
1829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









