







写在前面:
本文主要是将LRP方法和LSTM相结合,实现可解释性。学习LSTM可看这篇文章LSTM,学习LRP
1 摘要
在深度学习技术快速发展的推动下,深度神经网络最近被用于设计知识追踪 (KT) 模型,以实现更好的预测性能。然而,这些模型缺乏可解释性严重阻碍了它们的实际应用,因为它们的输出和工作机制受到不透明的决策过程和复杂的内部结构的影响。因此,我们建议采用事后方法来解决基于深度学习的知识追踪(DLKT)模型的可解释性问题。具体来说,我们专注于应用逐层相关性传播 (LRP) 方法通过将相关性从模型的输出层反向传播到其输入层来解释基于 RNN 的 DLKT 模型。实验结果表明使用 LRP 方法解释 DLKT 模型的预测是可行的,并部分验证了计算的相关性分数。我们相信这可能是朝着充分解释 DLKT 模型并促进其实际应用迈出的坚实一步。
2 KT的可解释性
许多 DLKT 模型,例如 DKT [12],采用 LSTM 或类似架构(例如 GRU)来完成 KT 任务。作为典型的 RNN 架构,该模型将输入序列向量
x
0
,
…
,
x
t
−
1
,
x
t
,
…
{x_0,\dots,x_{t-1},x_t,\dots}
x0,…,xt−1,xt,… 映射到输出序列向量
y
0
,
…
,
t
t
−
1
,
y
t
,
…
{y_0,\dots,t_{t-1},y_t,\dots}
y0,…,tt−1,yt,…,其中
x
t
x_t
xt表示学习者和练习之间的交互,
y
t
y_t
yt表示掌握概念时的预测概率向量。标准 LSTM 单元通常在 DLKT 模型中实现如下:
f
t
=
σ
(
W
f
h
h
t
−
1
+
W
f
x
x
t
+
b
f
)
(1)
f_t=\sigma(W_{fh}h_{t-1}+W_{fx}x_t+b_f) \tag{1}
ft=σ(Wfhht−1+Wfxxt+bf)(1)
i t = σ ( W i h h t − 1 + W i x x t + b i ) (2) i_t=\sigma(W_{ih}h_{t-1}+W_{ix}x_t+b_i) \tag{2} it=σ(Wihht−1+Wixxt+bi)(2)
C t ~ = t a n h ( W c h h t − 1 + W c x x t + n c ) (3) \tilde{C_t}=tanh(W_{ch}h_{t-1}+W_{cx}x_t+n_c) \tag{3} Ct~=tanh(Wchht−1+Wcxxt+nc)(3)
C t = f t ⊙ C t − 1 + i t ⊙ C t ~ (4) C_t=f_t\odot C_{t-1}+i_t\odot \tilde{C_t}\tag{4} Ct=ft⊙Ct−1+it⊙Ct~(4)
o t = σ ( W o h h t − 1 + W o x x t + b o ) (5) o_t =\sigma(W_{oh}h_{t-1}+W_{ox}x_t+b_o)\tag{5} ot=σ(Wohht−1+Woxxt+bo)(5)
h t = o t ⊙ t a n h ( C t ) (6) h_t = o_t\odot tanh(C_t)\tag{6} ht=ot⊙tanh(Ct)(6)
在得到 LSTM 输出 ht 后,DLKT 模型通常会进一步采用额外的层来输出最终的预测结果 yt,如下所示:
y
t
=
σ
(
W
y
h
h
t
+
b
y
)
(7)
y_t=\sigma (W_{yh}h_t+b_y)\tag{7}
yt=σ(Wyhht+by)(7)
我们看到基于 RNN 的 DLKT 模型通常由两种类型的连接组成:加权线性连接,即 (1),(2),(3),(5),(7)和乘法连接,即 (4) 和 (6)。 LRP 会以不同的方式解释这两种类型。
考虑方程(1)到(7)中给出的基于RNN的DLKT模型和LRP方法,可以通过计算相关性来完成解释,如下所示:

其中
R
y
t
d
R_{yt}^d
Rytd是预测输出 yt 的第 d 维的值,项 ε ∗ sign() 是一个稳定器。最后,计算的输入 xt 的相关性值
R
x
t
R_{xt}
Rxt 可以导出为
R
x
t
=
W
c
x
x
t
W
c
h
h
t
−
1
+
W
c
x
x
t
+
b
c
+
ε
∗
s
i
g
n
(
W
c
h
h
)
t
−
1
+
W
c
x
x
t
+
b
c
R_{x_t}=\frac{W_{cx}x_t}{W_{ch}h_{t-1}+W_{cx}x_t+b_c+\varepsilon*sign(W_{ch}h){t-1}+W_{cx}x_t+b_c}
Rxt=Wchht−1+Wcxxt+bc+ε∗sign(Wchh)t−1+Wcxxt+bcWcxxt
3 评估
数据集:ASSISTment 2009-2010
模型:构建的DLKT模型采用隐藏维数为256的LSTM单元,mini-batch size 和 dropout 分别设置为 20 和 0.5
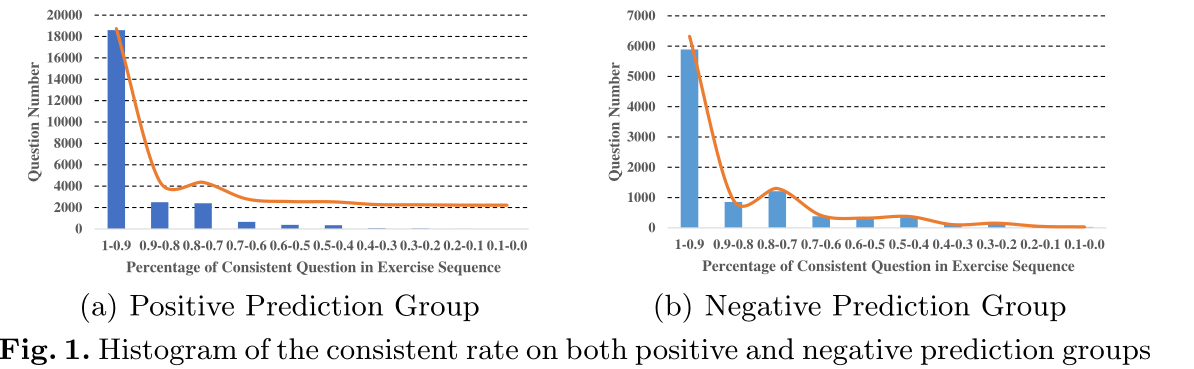
我们通过实验来了解 LRP 解释结果和模型预测结果之间的关系。具体来说,我们选择了 48,673 个长度为 15 的练习序列,即每个序列由 15 个单独的问题组成,作为口译任务的测试数据集。对于每个序列,我们将其前 14 个问题作为构建的 DLKT 模型的输入,最后一个问题用于验证模型对第 15 个问题的预测。结果,DKLT 模型正确预测了 34,311 个序列的最后一个问题,其中正面和负面结果分别为 25,005 和 9,306。基于正确预测的序列,我们采用 LRP 方法计算前 14 个问题的相关值,然后调查相关值的符号是否与学习者答案的正确性一致。
具体来说,我们将之前练习题中的一致性问题定义为“具有正相关值的正确回答的问题”或“具有负相关值的错误回答的问题”。因此,我们计算每个序列中此类一致问题的百分比,并将其命名为一致率。直观地说,高一致率反映了大多数正确回答的问题对给定概念的预测掌握概率有积极贡献,而大多数错误回答的问题对给定概念的预测掌握概率有消极贡献。
图 1 显示了两组正预测(即掌握概率高于 50%)和负预测(即掌握概率低于 50%)的一致率直方图。显然,我们看到大部分练习序列都达到了 90%(或更高)的一致率,这部分验证了使用 LRP 方法解释 DLKT 模型的预测结果的问题级可行性。
4 结论
我们在 KT 领域引入了一种事后可解释性方法,适用于一般的基于 RNN 的 DLKT 模型。我们通过使用其 LRP 方法来解释 DLKT 模型证明了这种方法的前景。我们进行了初步实验以验证所提出的方法。















 772
772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









