






1. CPU:
Intel 第三代 Xeon 可扩展处理器平台“Whitley”
第三代 Intel® 可扩展处理器平台(代号为“Whitley”)采用 Ice Lake-SP,面向 2P 服务器。该架构支持每插槽 64 个 PCI Express® Gen 4 通道,可实现更高的每核 I/O 带宽,并在 8 个通道、2DPC(每通道 2 个 DIMM)配置下支持频率高达 3200MT/秒的 DDR4 内存。这是 Intel 首款采用 10 纳米晶圆技术打造的服务器处理器,性能较前几代大幅提升。
概览
Xeon® SP 3rd Generation (Ice Lake)
- 每处理器支持多达 6TB(太字节)内存
- 支持 DDR4 带寄存器的 DIMM 和降载 DIMM,速度高达 3200MT/秒,相当于每个模组 25.6GB/秒的传输速度
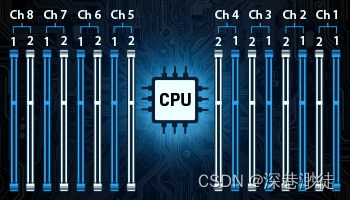
内存架构
- 内存架构基于每个处理器以 2 个 bank 排列的 8 个通道。每个处理器可以配置 8 或 16 个模组,具体取决于主板布局,以实现最大的总内存带宽。(4800MT/s*64位/8=38.4GB/s)
- 每个处理器 8 个内存通道(总内存带宽25.6GB/s*8=204.8GB/s)
- 每个通道最多 2 个 DIMM
- 每个处理器最多 16 个 DIMM
- 每个 2P 服务器最多 32 个 DIMM 插槽
Intel 第 4 代 Xeon 可扩展处理器平台“Eagle Stream”
采用 Sapphire Rapids-SP、名为“Eagle Stream”的第 4 代 Intel® 可扩展处理器平台面向 1P、2P、4P 和 8P 服务器。Intel 的第一个 DDR5 服务器平台支持每个处理器八个内存通道,内存速度高达 4800MT/s,它采用增强的 SuperFin 技术,基于 Intel 7 处理器而构建。采用下一代行业标准技术(如 PCIe 5.0 和 Compute Express Link 1.1)以及 Intel 的 Advanced Matrix Extensions (AMX),扩展内置的 AI 加速功能。从边缘到云端,采用 Sapphire Rapids-SP 的 Eagle Stream 使目前及未来数据中心的计算能力实现了巨大的飞跃。
概览
Xeon® SP 第 4 代 (Sapphire Rapids-SP)
- 每处理器支持多达 6TB(太字节)内存
- 支持高达 4800MT/s 的 DDR5 寄存器 DIMM,相当于每模块 38.4GB/s 的传输速度 (4800MT/s*64位/8=38.4GB/s)
内存架构
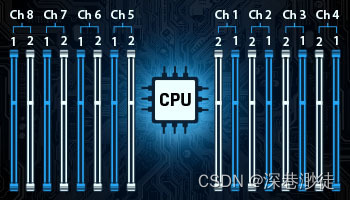
内存架构基于每个处理器以 2 个 bank 排列的 8 个通道。每个处理器可以配置 8 或 16 个模块,具体取决于主板布局,以实现最大的总内存带宽。
- 每个处理器 8 个内存通道(总内存带宽38.4GB/s*8=307.2GB/s)
- 每个通道最多 2 个 DIMM
- 每个处理器最多 16 个 DIMM
2. 内存
从内存控制器到内存颗粒内部逻辑,笼统上讲从大到小为:channel>DIMM>rank>chip>bank>row/column。
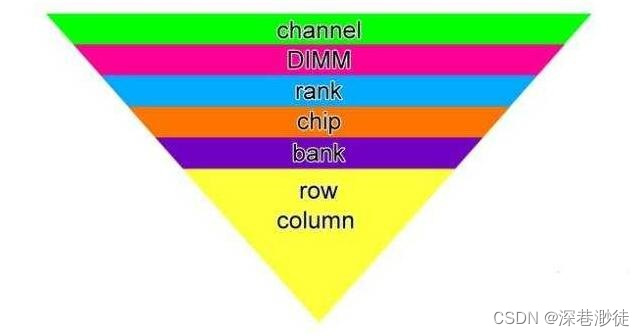
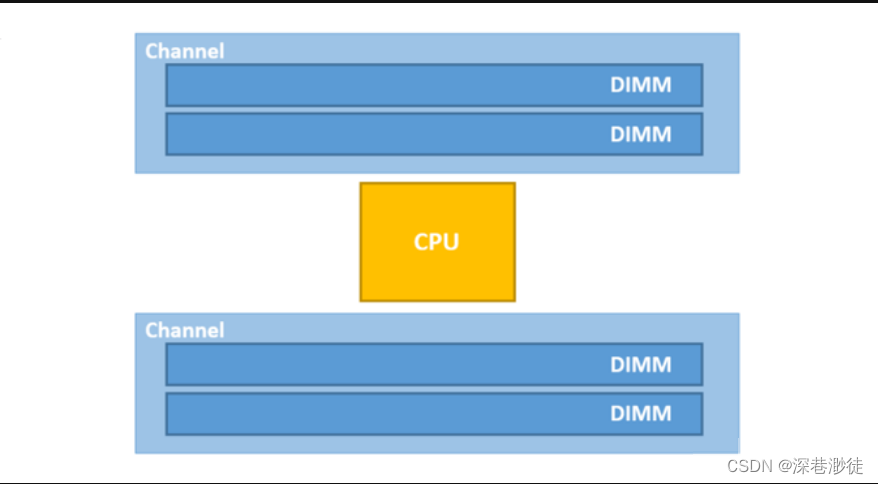
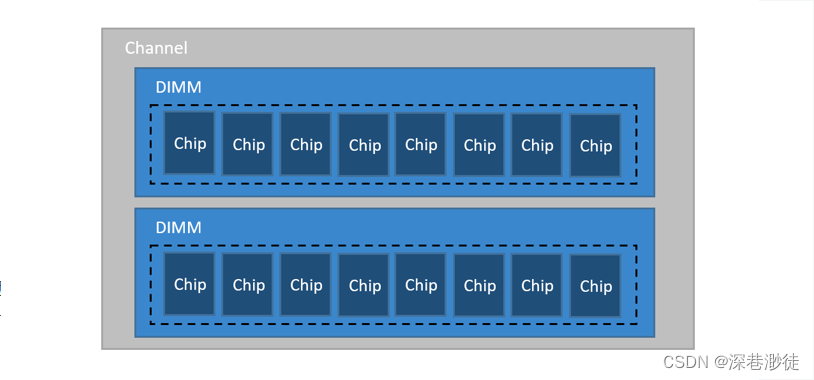
Channel
Channel即我们常说的内存通道数,比如像Intel whitely和Eagle stream都有8个内存通道,每个内存通道都有一个内存控制器,负责管理内存的读写操作。
Rank
Rank 指的是连接到同 一个CS(Chip Select)的chip,内存控制器能对同 一 rank 的 chip 进行读写操作。CPU、Rank与内存之间的接口位宽是64bit,也就意味着CPU在一个时钟周期内会向内存发送或从内存读取64bit的数据。那么就会有一个疑问,如果是2R x8 (2 rank * 8bit)的内存,那么速率就翻倍了吗?显然不是,单Rank配置的宽度为 64 位,而双Rank模组的宽度为128 位。然而,由于内存通道只有 64 位宽(与单Rank模组相同),内存控制器一次只能寻址一个Rank。正如你所料,这应该会使双Rank内存比传统的单Rank模组更慢,即使它们更密集。但实际上,单通道和双通道模块的延迟之间的差异几乎无法察觉。所以对于一个通道上,CPU每次只能访问一个rank,所以即使支持2DPS(每个通道2个DIMM)或者内存支持2R,也并不能使单个通道速率翻倍提升。
速率
DDR=Double Data Rate双倍速率,DDR SDRAM=双倍速率同步动态随机存储器,人们习惯称为DDR,其中,SDRAM 是Synchronous Dynamic Random Access Memory的缩写,即同步动态随机存取存储器。而DDR SDRAM是Double Data Rate SDRAM的缩写,是双倍速率同步动态随机存储器的意思。
为什么会是双倍速率?DDR是一个时钟周期内可传输两次数据,也就是在时钟的上升期和下降期各传输一次数据,所以其数据传输速度为系统时钟频率的两倍。
内存带宽计算公式:带宽 = 内存核心频率 × 倍增系数 × 内存总线位数 / 8 。
通常内存标签上会写标称频率(即内存核心频率 x 倍增系数),以DDR4为例,如标称的2933Y即为标称频率(2933MHZ或2933MT/s),所以2933MT/s的带宽=2933MT/s x 64bit/8bit=23.464GB/s。

3. NVMe SSD:
通过以上对CPU和内存的了解,如果考虑到SSD 多盘性能的时候,相信大家在打满磁盘性能测试的时候,是会考虑到内存及内存通道是会成性能瓶颈因素的,比如我有24片Gen 3的NVMe SSD产品,不考虑其他因素的话,那么内存及内存通道该如何配置呢?
可能我们会想一片SSD的顺序读性能为3.2GB/s,那么24片所需的带宽为3.2GB/s x 24 = 76.8GB/s,使用的内存为2933MT/s的话,那么单通道仅有23.464GB/s,那么为了满足多盘性能达到最优,那么至少需要配置4个通道的内存。
上面所说的情况仅是单纯考虑带宽,但是实际上内存通道和存储设备并不是这么简单的关系,如果涉及多盘对一个通道的情况,那么就要考虑资源的分配及负载均衡,那么必然会产生切换产生的延时等,比如我一个在得瑞领新做技术支持的哥们,在Gen4的平台上用DERA D7000的NVMe SSD做过以下的验证。
server1:
cpu:5318Y
内存:4x64G 2933MT/s 256G
进行多盘顺序读实验:在同时进行顺序读的盘片变为4pcs时,此时已经可以全部达到最大性能
| nvme0 | 3501 | 3953 | 4395 | 5037 | 6876 | 7377 | 7455 | 7461 |
| nvme1 | 3468 | 3784 | 4521 | 5072 | 6863 | 7365 | 7454 | 7460 |
| nvme2 | 2086 | 2211 | 2293 | 2476 | 3093 | 4406 | 6795 | 7457 |
| nvme3 | 2062 | 2164 | 2273 | 2452 | 3056 | 4393 | 6765 | 7457 |
| nvme4 | 2089 | 2218 | 2344 | 2471 | 3082 | 4393 | 6793 | 7457 |
| nvme5 | 2063 | 2206 | 2340 | 2466 | 3040 | 4300 | 6766 |
|
| nvme6 | 2034 | 2879 | 3808 | 6154 | 7451 | 7459 |
|
|
| nvme7 | 2017 | 2937 | 3771 | 6153 | 7452 |
|
|
|
| nvme8 | 2031 | 2882 | 3804 | 6076 |
|
|
|
|
| nvme9 | 2041 | 2844 | 3763 |
|
|
|
|
|
| nvme10 | 2318 | 3248 |
|
|
|
|
|
|
| nvme11 | 2310 |
|
|
|
|
|
|
|
| 总带宽 | 28020 | 31326 | 33312 | 38357 | 40913 | 39693 | 42028 | 37292 |
server2:
CPU:6330
内存:16x32G 512G
进行多盘顺序读实验:可以全部达到最大性能
| nvme0 | 7372 |
| nvme1 | 7401 |
| nvme2 | 7377 |
| nvme3 | 7367 |
| nvme4 | 7391 |
| nvme5 | 7370 |
| nvme6 | 7457 |
| nvme7 | 7457 |
| nvme8 | 7457 |
| nvme9 | 7457 |
| nvme10 | 7456 |
| nvme11 | 7457 |
| 总带宽 | 89019 |
另外通过对比二者的内存all read性能:
server1:allread 81593.9
server2:allread 315209.0
结合通道数及cpu主频,一个通道约有20G 的读带宽。
同时试验了8x32G 的情况,12pcs盘同样出现下降,但幅度相较4根内存的情况下降趋势得到明显改善
虽8x32 内存的allread的总带宽为160G左右,总的能覆盖12pcs D7000全读的带宽,但如果内存通道数少于ssd数量应是存在争抢。导致部分盘出现下降
结论:在Gen4时代做多盘顺序读写,如想达到满性能,需尽量保证服务器的可用内存通道数大于测试盘片数。

















 2965
2965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









