






论文题目:基于深度强化学习的室内场景目标驱动导航

目前存在的问题
深度强化学习缺乏对新目标的泛化能力。一般的深度强化学习算法只依赖于当前状态的策略,并且target goal隐含的嵌入到了模型参数中。在面对新的目标时,就需要学习新的模型参数。
数据效率低,例如模型需要几次(通常代价高昂)的试错才能收敛,这使得它不适用于现实世界的场景
本文方法
1. 为了解决第一个问题,我们设计了一个基于actor-critic架构的模型,有更好的泛化性、适应性和灵活性。
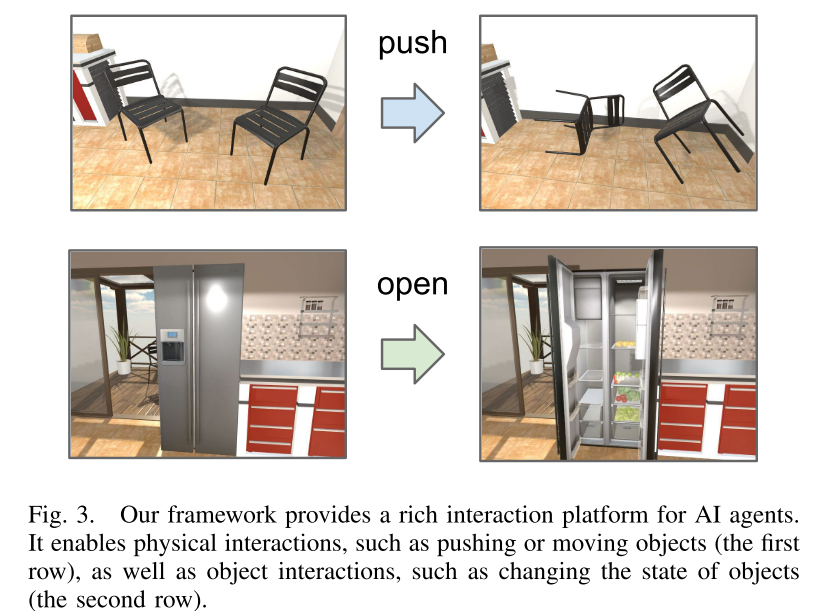
2. 为了解决第二个问题,提出了AI2-THOR框架,它提供了一个具有高质量三维场景和物理引擎的环境。 我们的框架使智能体能够采取行动并与对象交互。 因此,我们可以有效地收集大量的训练样本。
任务定义
在一个空间中仅使用视觉输入来找到一个给定的目标。为了实现更高的适应性和灵活性,我们引入了目标驱动模型。 我们的模型将视觉任务目标作为输入,因此我们可以避免对每一个新的目标进行重新训练。 我们的模型学习一个目标和当前状态的策略的联合嵌入。 从本质上说,一个智能体学会根据它的当前状态和目标采取下一个行动,而不仅仅是它的当前状态。 因此,没有必要为新的目标重新训练模型。 我们依赖的一个关键直觉是,不同的训练集共享信息。 例如,智能体在训练阶段探索共同的路线,同时接受寻找不同目标的训练。 各种场景也共享可概括的方面(例如,冰箱通常靠近微波炉)。 简而言之,我们利用了这样一个事实,即新目标的学习将更容易与其他目标训练过的模型。
模型细节
AI2-THOR框架
AI2-THOR框架通过物理引擎(Unity3D)和深度学习框架(Tensorflow)集成而设计的。其总体思路是将物理引擎的渲染图像流式传输到深度学习框架,深度学习框架基于视觉输入发布控制命令,并将其发回物理引擎中的Agent。
AI2-THOR目前有32个场景,分为4个类型:厨房、客厅、卧室和浴室。平均每个场景包含68个对象实实例。并且提供Pyhton APIs,使得AI智能体可以与3D场景交互。
目标驱动的导航模型
问题描述
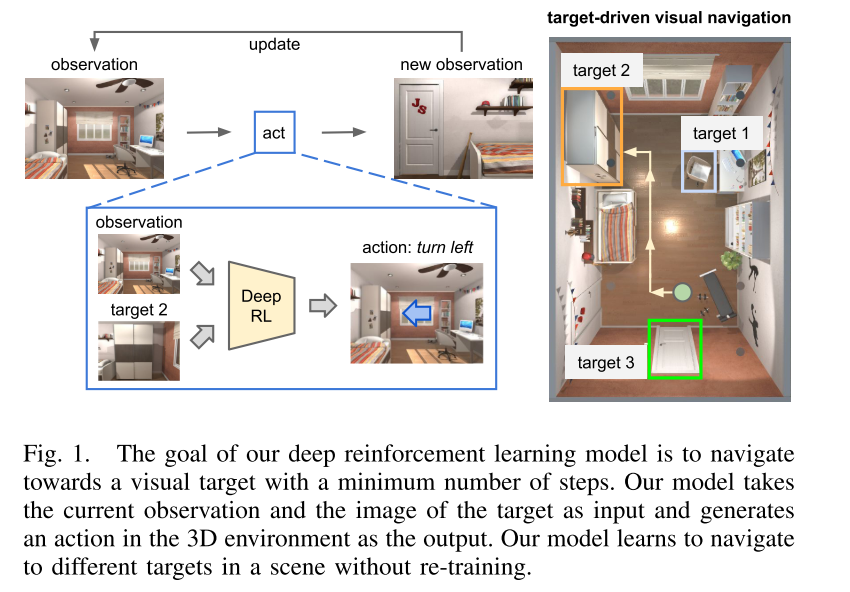
本文的目标是找到将Agent从其当前位置移动到由RGB图像指定的目标的最小长度的动作序列。 作者开发了一个深度强化学习模型,该模型以当前观测的RGB图像和目标的RGB图像作为输入。 模型的输出是3D中的一个动作,如向前移动或右转。 注意,模型学习从2D图像到3D空间中的动作的映射。
为了训练一个单一的导航模型,它可以学习导航到新的目标,但是却不需要重新训练。本文指定任务目标(即导航目的地)作为模型的输入,而不是把目标植入到模型的参数中。并将该任务成为目标驱动的导航模型。
从形式上讲,目标驱动模型的学习目标是学习一个随机策略函数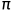 ,它有两个输入,一个是代表当前状态的函数St和一个目标的表示g,并在动作空间
,它有两个输入,一个是代表当前状态的函数St和一个目标的表示g,并在动作空间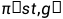 上产生一个概率分布。为了进行测试,移动机器人不断采取从策略分布中提取的动作,直到到达目的地。这样,动作就以状态和目标为条件。因此,不需要对新目标进行重新训练。
上产生一个概率分布。为了进行测试,移动机器人不断采取从策略分布中提取的动作,直到到达目的地。这样,动作就以状态和目标为条件。因此,不需要对新目标进行重新训练。
学习设置
动作空间
前进、后退、左转、右转,其中步长恒定为0.5米,转向为90度,将场景空间离散成网格世界表示。为了模拟真实世界系统动力学中的不确定性,我们在步骤N(0,0.01)和每个位置的转向N(0,1.0)中添加一个高斯噪声。
观测和目标
观察和目标都是由智能体的RGB摄像机在其第一人称视图中拍摄的图像。 使用图像作为目标描述的好处是可以灵活地指定新的目标。给定目标图像,任务目标是导航到拍摄目标图像的位置和视点。
奖励设计
本文关注的是最小化对导航目标的轨迹长度。因此,仅在任务完成后提供达成目标的奖励 (10.0)。为了鼓励更短的轨迹,我们添加了一个小的时间惩罚 (-0.01) 作为即时奖励。
模型细节
模型
本文设计了一个深度神经网络,作为的非线性函数逼近器,其中在时刻t的动作a可以描述为: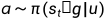 。
。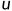 指的是模型的参数,
指的是模型的参数,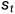 表示当前观测的图像,
表示当前观测的图像,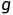 指的是导航目标的图像。
指的是导航目标的图像。
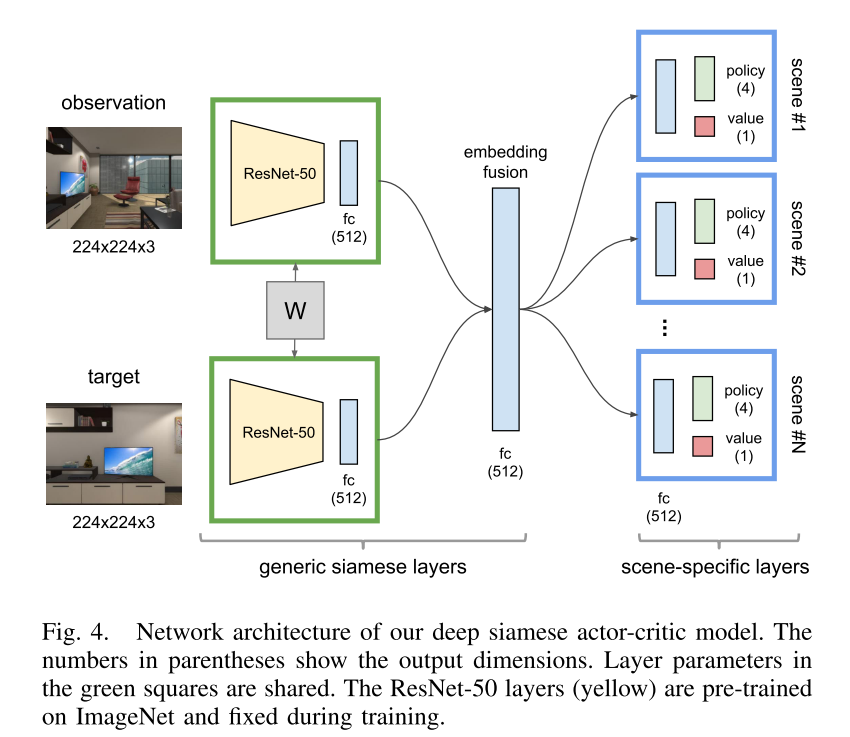
导航决策需要了解当前位置和目标位置之间的相对空间位置,以及对场景布局的整体感觉。 本文开发了一个新的Deep Siamese Actor-Critic网络来捕捉这样的直觉。
模型输入为代表智能体当前观测和目标的两幅RGB图像。我们推理当前位置和目标之间的空间排列的方法是将它们投影到相同的嵌入空间中,在那里它们的几何关系保持不变。Deep Siamese网络是一种用于鉴别嵌入学习的双流神经网络模型。 我们使用两个权重共享的Siamese层流将当前状态和目标转换到同一个嵌入空间。来自两个嵌入的信息被融合以形成联合表示。 这个联合表示通过场景特定的层传递。 具有场景特定层的意图是捕捉场景的特殊特征(例如,房间布局和对象布置),这些特征对导航任务至关重要。 最后,该模型生成与A2C模型类似的策略和值输出。 在该模型中,所有场景中的目标共享相同的通用Siamese层,场景中的所有目标共享相同的场景特定层。 这使得模型能够更好地进行跨目标、跨场景的泛化。
该框架输入为当前agent图像和目标图像,分别通过ResNet-50得到224*224*3=2048维特征,训练过程中冻结了参数,使用历史的4帧图像特征作为输入,共8192维,以解释agent过去的动作,然后通过全连接层FC映射到512维特征,并且上下两个网络为siamese孪生网络,共享权重参数w,级联为表示当前state和target的1024维特征,通过FC映射为512维统一表示的特征,即将两个权重共享的siames层转换到相同的embedding space。通过A3C最终输出4个的动作概率输出和单个值函数输出。使用RMSProp优化器,学习率为7e-4。
对于loss函数的设定,siamese network的初衷是计算两个输入的相似度。左右两个神经网络分别将输入转换成一个"向量",在新的空间中,通过判断cosine距离就能得到相似度了。Cosine是一个选择,exp function也是一种选择,欧式距离什么的都可以,训练的目标是让两个相似的输入距离尽可能的小,两个不同类别的输入距离尽可能的大。
通过对两幅输入图像的比较,得出当前state想要到达target需要执行什么动作,前提是在同一个场景下,并且是已经被训练好的场景,也比较适合AI2-THOR仿真环境的特点,即单个场景。
训练策略
A3C是一种强化学习模型,它通过并行运行多个训练线程副本来学习,并以异步方式更新一组共享的模型参数。 已经证明,这些并行的训练线程相互稳定,在视频游戏领域实现了最先进的性能。 我们使用与A3C类似的训练协议。
实验结果
比现有的SOTA深度强化学习算法收敛的更快;
跨目标和跨场景的泛化力;
即便模型是在仿真中训练的,但是只需要少量的Fine-Tuning就可以泛化到真实的机器人场景中;
端到端可训练


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









