








在前几篇文章中,我们共同探索了 ADK 的核心理念、架构以及如何构建具备高级认知能力的 AI 代理。随着我们对 ADK 的理解日益深入,是时候将目光投向更宏大、更复杂的应用场景了——企业级应用集成。
在当今数据驱动的商业环境中,AI 代理如果不能与企业现有的系统和数据源深度融合,其价值将大打折扣。本篇文章将带您深入探讨如何利用 ADK 构建能够连接企业数据孤岛、理解企业内部文档、并遵循企业安全规范的智能代理。我们将重点解析企业数据源连接、文档检索与 RAG (检索增强生成) 架构并通过一个构建企业知识库问答系统的实例,展示 ADK 在企业集成中的强大威力。
🔗 连接企业数据源:打破信息壁垒
企业数据往往散落在各个独立的系统中:数据库、CRM、ERP、内部 API 等。要让 AI 代理真正赋能企业,首先必须打通这些数据连接。
挑战与机遇:
- 数据孤岛:不同系统间数据格式各异,访问方式不一。
- 实时性要求:许多业务场景需要代理访问最新的数据。
- 安全性与合规性:企业数据访问必须严格遵守安全策略和合规要求。
ADK 的角色:
ADK 灵活的工具机制为连接企业数据源提供了坚实基础:
FunctionTool:这是最直接的方式。开发者可以将访问特定数据库、调用内部 API 或处理特定数据格式的 Python 函数封装为FunctionTool。例如,一个FunctionTool可以实现查询 SQL 数据库、请求内部 REST API、或者解析特定的文件格式。
APIHubToolset与 OpenAPI:如果企业的 API 通过 Apigee API Hub 管理并遵循 OpenAPI 规范,APIHubToolset可以自动生成 ADK 工具,极大简化集成工作 。
MCPToolset(模型上下文协议):对于遵循 MCP 标准暴露其能力的企业服务,MCPToolset能够实现“即插即用”式的集成,提供标准化的交互方式 。
集成策略:
- 直接连接:在工具内部实现数据库连接、API 调用等逻辑。此时务必考虑连接池、超时处理和凭证安全。
- API 网关:通过企业统一的 API 网关访问内部服务,有助于集中管理安全、监控和流控。
- 数据虚拟化/中间层:构建一个中间服务层,封装对底层复杂数据源的访问,为 ADK 代理提供更简洁、统一的数据接口。
🧠 文档检索与 RAG 架构:赋予代理企业“记忆”
企业内部蕴藏着海量的知识,如政策文档、技术手册、项目报告、历史邮件等。让 AI 代理能够理解并利用这些知识,是提升其智能水平的关键。检索增强生成 (Retrieval Augmented Generation, RAG) 架构正是为此而生。
RAG 的核心思想:
RAG 结合了检索系统(从知识库中查找相关信息)和大型语言模型(LLM,利用检索到的信息生成回答)的优势。它能有效减少 LLM 的“幻觉”现象,确保回答基于事实,并能动态更新知识。
RAG 系统的核心组件:
- 知识库 (Knowledge Base):存储企业文档的地方。通常会对文档进行预处理(清洗、切块),然后使用嵌入模型 (Embedding Models) 将文本块转换为向量,存入向量数据库 (Vector Database)(如 Pinecone, FAISS, Vertex AI Vector Search)以便进行高效的相似性搜索。
- 检索器 (Retriever):接收用户查询,将其转换为向量,然后在向量数据库中搜索最相关的文档片段。
- 大型语言模型 (LLM - Generator):ADK 代理的核心,如 Gemini。它接收原始查询和检索器返回的相关文档片段,然后综合这些信息生成最终答案。
在 ADK 中实现 RAG:
我们可以通过 FunctionTool 在 ADK 中集成 RAG 的检索能力:
- 创建
knowledge_retrieval_tool:
- 这个工具接收用户的查询字符串。
- 内部逻辑负责:
- 使用与知识库一致的嵌入模型将查询文本转换为向量。
- 查询向量数据库,获取最相关的文档片段(chunks)。
- 返回这些文档片段作为工具的输出。
- 配置 ADK 代理 (
LlmAgent):
- 将
knowledge_retrieval_tool添加到代理的tools列表中 。 - 精心设计代理的
instruction(提示) 。这个提示至关重要,需要引导 LLM: - 理解何时应该使用
knowledge_retrieval_tool(例如,当用户问题涉及内部知识时)。 - 如何利用工具返回的文档片段来回答问题。
- 强调回答必须严格基于检索到的信息,避免编造。
- 如果未找到相关信息,应如实告知用户。
🚀 实例:构建企业知识库问答系统
现在,我们将综合运用上述概念,勾勒出一个基于 ADK 的企业知识库问答系统的实现蓝图。
场景:一家公司希望构建一个 AI 助手,能够回答员工关于公司政策、IT 支持、产品信息等基于内部文档的问题。
高层架构:
- 文档预处理与索引(离线):
- 收集企业内部文档(PDF、Word、Confluence 页面等)。
- 对文档进行清洗、分块 (chunking)。
- 使用嵌入模型(如 Google 的
text-embedding-004)将文本块转换为向量。
- 将向量及其对应的文本内容存储到向量数据库中(如 Vertex AI Vector Search)。
- ADK 问答代理(在线):
- 用户通过前端界面与 ADK 代理交互。
- 代理使用 RAG 模式:调用
knowledge_retrieval_tool从向量数据库检索相关信息,然后由 LLM 生成答案。
源代码如下
__init__.py文件
from . import agent.env文件
# 不同LLM提供商的API密钥
# 将此文件重命名为.env并根据需要添加你的密钥
# Google API密钥,用于Gemini模型
GOOGLE_GENAI_USE_VERTEXAI="False"
GOOGLE_API_KEY=**********
QWEN_API_KEY = "sk-f22763*******8d77c"agent.py文件
import os
import sys
import importlib.util
from google.adk.agents import Agent, LlmAgent
from google.adk.tools import FunctionTool
from google.adk.models.lite_llm import LiteLlm
from typing import Dict, Any
# 定义动态导入函数
def import_module_from_path(module_name, file_path):
"""动态导入模块"""
spec = importlib.util.spec_from_file_location(module_name, file_path)
module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(module)
return module
# 确定当前目录
current_dir = os.path.dirname(os.path.abspath(__file__))
try:
# 尝试普通导入
from knowledge_tool import knowledge_retrieval_tool, initialize_knowledge_base_with_examples
except ImportError:
# 如果失败,尝试动态导入
knowledge_tool_module = import_module_from_path(
"knowledge_tool", os.path.join(current_dir, "knowledge_tool.py")
)
knowledge_retrieval_tool = knowledge_tool_module.knowledge_retrieval_tool
initialize_knowledge_base_with_examples = knowledge_tool_module.initialize_knowledge_base_with_examples
# 将Python函数封装为ADK工具
knowledge_tool_instance = FunctionTool(knowledge_retrieval_tool)
# API密钥设置
DEFAULT_DASHSCOPE_API_KEY = "sk-f227634bb5614dd8b4eb29a95f38d77c" # 请替换为您的实际密钥
DASHSCOPE_API_KEY = os.environ.get("DASHSCOPE_API_KEY", DEFAULT_DASHSCOPE_API_KEY)
# 企业知识库问答代理
enterprise_qna_agent = LlmAgent(
name="EnterpriseKnowledgeAssistant",
model=LiteLlm(
model="openai/qwen-turbo",
api_key=DASHSCOPE_API_KEY,
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
),
tools=[knowledge_tool_instance],
instruction="""
你是一个企业内部知识问答助手。你的任务是根据用户的问题,利用 knowledge_retrieval_tool 从公司知识库中查找相关信息,并基于这些信息清晰、准确地回答用户。
请遵循以下步骤:
1. 分析用户的问题,理解其意图。
2. 如果问题适合从知识库中查找答案,请立即调用 knowledge_retrieval_tool,并将用户的完整问题作为查询参数。
3. 工具会返回相关的文档片段。仔细阅读这些片段。
4. 严格根据检索到的文档片段内容来组织你的回答。不要添加外部知识或个人猜测。
5. 如果检索到的文档片段包含答案,请清晰地呈现。你可以引用关键信息或总结要点。
6. 如果工具返回 'status: "not_found"' 或检索到的文档与问题不相关,请明确告知用户你在公司知识库中没有找到直接答案,不要尝试编造。
7. 保持回答专业、简洁、有帮助。
示例:
用户:"我们公司的年假政策是什么?"
你的行动:[调用 knowledge_retrieval_tool(query="我们公司的年假政策是什么?")]
(假设工具返回了相关政策片段)
你的回答:[基于返回的片段进行回答,例如:"根据公司政策文档,员工每年享有XX天年假..."]
用户:"如何配置新的开发环境?"
你的行动:[调用 knowledge_retrieval_tool(query="如何配置新的开发环境?")]
(假设工具返回了相关设置指南)
你的回答:[基于返回的片段进行回答,例如:"配置新的开发环境,请参照以下步骤..."]
""",
output_key="qna_response"
)
# 为兼容 ADK 的要求,将智能体公开为 root_agent
root_agent = enterprise_qna_agent
# 在导入模块时初始化知识库
try:
initialize_knowledge_base_with_examples()
except Exception as e:
print(f"初始化知识库时出错: {e}")
print("请确保已安装必要的依赖: pip install pymilvus 'pymilvus[model]'")embedding.py文件
from typing import List, Union
import os
import sys
import numpy as np
# 设置本地模型路径
LOCAL_MODEL_PATH = r"D:\module\BAAI-bge-large-zh-v1.5"
class EmbeddingModel:
"""Text embedding model using local BGE model or fallback to random embeddings."""
def __init__(self, model_path: str = LOCAL_MODEL_PATH):
"""
Initialize the embedding model.
Args:
model_path: Path to the local embedding model
"""
self.model_path = model_path
self.dim = 1024 # BGE-large 模型的向量维度
self._model_loaded = False
self.model = None
self.tokenizer = None
# 尝试加载模型
try:
# 加载必要的库
from transformers import AutoModel, AutoTokenizer
import torch
print(f"尝试从本地路径加载模型: {model_path}")
# 加载模型和分词器
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
self.model = AutoModel.from_pretrained(model_path)
# 如果有GPU,将模型移至GPU
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.model.to(self.device)
self.model.eval() # 设置为评估模式
self._model_loaded = True
print(f"成功加载模型: {model_path}")
except Exception as e:
print(f"警告: 无法加载嵌入模型: {str(e)}")
print("将使用随机向量作为演示用途。")
self._model_loaded = False
def _get_embeddings(self, text_batch):
"""使用BGE模型获取文本的嵌入向量"""
import torch
# 对文本进行编码
encoded_input = self.tokenizer(
text_batch,
padding=True,
truncation=True,
max_length=512,
return_tensors='pt'
).to(self.device)
# 推理
with torch.no_grad():
outputs = self.model(**encoded_input)
# 使用最后一层的隐藏状态的平均值作为嵌入
embeddings = self._mean_pooling(outputs.last_hidden_state, encoded_input['attention_mask'])
# 标准化
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
return embeddings.cpu().numpy()
def _mean_pooling(self, token_embeddings, attention_mask):
"""对token嵌入进行平均池化"""
import torch
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
def embed(self, text: Union[str, List[str]]) -> List[List[float]]:
"""
Convert text to vector embeddings.
Args:
text: Single string or list of strings to embed
Returns:
List of vector embeddings
"""
# 确保输入格式一致,单个字符串转为列表
if isinstance(text, str):
texts = [text]
else:
texts = text
# 如果模型加载失败,返回随机向量
if not self._model_loaded:
import random
return [[random.uniform(-1, 1) for _ in range(self.dim)] for _ in texts]
# 使用模型生成嵌入
try:
embeddings = self._get_embeddings(texts)
return embeddings.tolist()
except Exception as e:
print(f"生成嵌入时出错: {str(e)}")
print("返回随机向量作为后备方案")
import random
return [[random.uniform(-1, 1) for _ in range(self.dim)] for _ in texts] knowledge_tool.py
from typing import Dict, Any, List, Optional
import os
import sys
import importlib.util
# 定义动态导入函数
def import_module_from_path(module_name, file_path):
"""动态导入模块"""
spec = importlib.util.spec_from_file_location(module_name, file_path)
module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(module)
return module
# 确定当前目录
current_dir = os.path.dirname(os.path.abspath(__file__))
# 尝试导入简单向量数据库
try:
from simple_vector_db import SimpleVectorDB, get_vector_db
except ImportError:
# 如果失败,尝试动态导入
vector_db_module = import_module_from_path(
"simple_vector_db", os.path.join(current_dir, "simple_vector_db.py")
)
SimpleVectorDB = vector_db_module.SimpleVectorDB
get_vector_db = vector_db_module.get_vector_db
# 导入嵌入模型
try:
from embedding import EmbeddingModel
except ImportError:
# 如果失败,尝试动态导入
embedding_module = import_module_from_path(
"embedding", os.path.join(current_dir, "embedding.py")
)
EmbeddingModel = embedding_module.EmbeddingModel
# Initialize the vector database and embedding model as module-level singletons
# This ensures we only create one instance even if the tool is called multiple times
_vector_db = None
_embedding_model = None
def get_embedding_model() -> EmbeddingModel:
"""Get or create the embedding model singleton."""
global _embedding_model
if _embedding_model is None:
_embedding_model = EmbeddingModel()
return _embedding_model
def knowledge_retrieval_tool(query: str, tool_context=None) -> Dict[str, Any]:
"""
从企业知识库中检索与用户查询相关的文档片段。
Args:
query: 用户提出的问题或查询。
tool_context: ADK 工具上下文,可用于访问会话状态或认证信息。
Returns:
一个包含检索到的文档片段列表的字典,
例如: {"status": "success", "documents": ["文档片段1...", "文档片段2..."]}
{"status": "not_found", "message": "未找到相关文档。"}
"""
print(f"--- 工具:knowledge_retrieval_tool 被调用,查询={query} ---")
try:
# 获取向量数据库和嵌入模型实例
vector_db = get_vector_db()
embedding_model = get_embedding_model()
# 将用户查询转换为向量表示
query_embedding = embedding_model.embed(query)
# 在向量数据库中搜索相似文档
search_results = vector_db.search(
query_vectors=query_embedding,
limit=3 # 返回前3个最相关的结果
)
# 检查是否有结果
if not search_results:
return {
"status": "not_found",
"message": "在企业知识库中未找到与您查询直接相关的文档。"
}
# 提取文档文本并返回
documents = [result["text"] for result in search_results]
return {
"status": "success",
"documents": documents
}
except Exception as e:
print(f"知识检索工具出错: {e}")
return {
"status": "error",
"error_message": f"检索文档时发生错误: {str(e)}"
}
def initialize_knowledge_base_with_examples() -> None:
"""用示例数据初始化知识库,仅用于演示目的。"""
vector_db = get_vector_db()
embedding_model = get_embedding_model()
# 示例文档
documents = [
{
"text": "HR政策文档摘录1:公司年假政策规定每位员工每年可享有20天带薪假期。新员工需要工作满3个月后方可申请休假。休假申请需提前至少一周提交给直属经理审批。",
"metadata": {"source": "HR政策手册", "category": "假期政策", "updated": "2023-09-01"}
},
{
"text": "HR政策文档摘录2:病假规定超过3天需要提供医生证明。病假期间,员工薪资将按照公司规定的比例发放。紧急情况下,请通过电话或短信及时通知您的直属经理。",
"metadata": {"source": "HR政策手册", "category": "假期政策", "updated": "2023-09-01"}
},
{
"text": "技术设置指南摘录1:配置公司VPN,请按照以下步骤操作:1.从内部门户下载VPN客户端 2.使用您的公司邮箱和密码登录 3.选择最近的服务器位置 4.连接后,您将可以访问内部资源。",
"metadata": {"source": "IT设置指南", "category": "网络配置", "updated": "2023-10-15"}
},
{
"text": "技术设置指南摘录2:安装新软件前,请确保您的操作系统已更新到最新版本。所有软件安装必须通过公司软件中心进行,不得自行下载安装未经批准的软件。",
"metadata": {"source": "IT设置指南", "category": "软件安装", "updated": "2023-10-15"}
},
{
"text": "新员工入职指南:您的第一天将安排参观办公室,了解公司文化,并与您的团队成员见面。请携带您的身份证件和银行账户信息,以便HR部门完成入职手续。",
"metadata": {"source": "入职手册", "category": "新员工", "updated": "2023-08-10"}
},
{
"text": "远程工作政策:公司允许员工每周远程工作不超过2天。远程工作期间,员工需要保持在线状态并参加所有必要的会议。每周必须在办公室工作至少3天。",
"metadata": {"source": "工作场所政策", "category": "工作安排", "updated": "2023-11-05"}
}
]
# 为每个文档生成向量嵌入
document_texts = [doc["text"] for doc in documents]
embeddings = embedding_model.embed(document_texts)
# 准备要插入的数据
data_to_insert = []
for i, (doc, embedding) in enumerate(zip(documents, embeddings)):
data_to_insert.append({
"id": i,
"vector": embedding,
"text": doc["text"],
"metadata": doc["metadata"]
})
# 删除现有集合并创建新的
vector_db.drop_collection()
# 插入文档
vector_db.add_documents(data_to_insert)
print(f"成功初始化知识库,添加了 {len(data_to_insert)} 个文档。") simple_vector_db.py
"""
基于内存的简单向量数据库
这个模块提供了一个简单的基于内存的向量数据库实现,用于替代Milvus Lite
主要用于测试和演示,不需要额外的依赖
"""
import os
import numpy as np
from typing import List, Dict, Any, Optional
class SimpleVectorDB:
"""基于内存的简单向量数据库,用于存储和检索文档"""
def __init__(self, collection_name: str = "documents", vector_dim: int = 1024):
"""
初始化简单向量数据库
Args:
collection_name: 集合名称
vector_dim: 向量维度
"""
self.collection_name = collection_name
self.vector_dim = vector_dim
self.documents = [] # 存储文档和向量
self.next_id = 0 # 用于生成唯一ID
def add_documents(self, documents: List[Dict[str, Any]]) -> List[int]:
"""
添加文档到向量数据库
Args:
documents: 文档列表,每个文档包含'id', 'vector', 'text'和'metadata'
Returns:
添加的文档ID列表
"""
added_ids = []
for doc in documents:
# 使用提供的ID或生成新ID
doc_id = doc.get('id', self.next_id)
self.next_id = max(self.next_id, doc_id + 1)
# 添加文档
self.documents.append({
'id': doc_id,
'vector': np.array(doc['vector']), # 转换为numpy数组以便计算
'text': doc['text'],
'metadata': doc.get('metadata', {})
})
added_ids.append(doc_id)
print(f"添加了{len(documents)}个文档到向量数据库")
return added_ids
def search(self, query_vectors: List[List[float]], limit: int = 3,
filter_expr: Optional[str] = None) -> List[Dict[str, Any]]:
"""
在向量数据库中搜索相似文档
Args:
query_vectors: 查询向量列表
limit: 返回结果的最大数量
filter_expr: 过滤表达式(此简单实现暂不支持复杂过滤)
Returns:
搜索结果列表
"""
if not self.documents:
print("警告: 向量数据库为空")
return []
# 我们只处理第一个查询向量
query_vector = np.array(query_vectors[0])
# 计算余弦相似度
results = []
for doc in self.documents:
# 计算余弦相似度
similarity = self._cosine_similarity(query_vector, doc['vector'])
# 如果有过滤表达式,这里应该进行过滤
# 目前仅支持简单的元数据字段匹配
if filter_expr and not self._simple_filter(doc['metadata'], filter_expr):
continue
results.append({
'id': doc['id'],
'distance': 1 - similarity, # 转换相似度为距离
'text': doc['text'],
'metadata': doc['metadata']
})
# 按相似度排序(距离越小越相似)
results.sort(key=lambda x: x['distance'])
# 限制结果数量
return results[:limit]
def _cosine_similarity(self, vec1: np.ndarray, vec2: np.ndarray) -> float:
"""计算两个向量的余弦相似度"""
dot_product = np.dot(vec1, vec2)
norm_a = np.linalg.norm(vec1)
norm_b = np.linalg.norm(vec2)
# 避免除以零
if norm_a == 0 or norm_b == 0:
return 0
return dot_product / (norm_a * norm_b)
def _simple_filter(self, metadata: Dict[str, Any], filter_expr: str) -> bool:
"""
简单的元数据过滤器
Args:
metadata: 文档元数据
filter_expr: 简单的过滤表达式,格式为"field=value"
Returns:
是否通过过滤器
"""
try:
if '=' not in filter_expr:
return True
field, value = filter_expr.split('=', 1)
field = field.strip()
value = value.strip().strip('"\'') # 移除可能的引号
# 检查元数据字段是否匹配
return str(metadata.get(field)) == value
except:
# 过滤表达式错误,默认通过
return True
def delete_documents(self, ids: List[int] = None) -> List[int]:
"""
从向量数据库中删除文档
Args:
ids: 要删除的文档ID列表
Returns:
已删除的文档ID列表
"""
if not ids:
return []
deleted_ids = []
remaining_docs = []
for doc in self.documents:
if doc['id'] in ids:
deleted_ids.append(doc['id'])
else:
remaining_docs.append(doc)
self.documents = remaining_docs
return deleted_ids
def drop_collection(self) -> None:
"""删除整个集合"""
self.documents = []
print(f"集合 {self.collection_name} 已清空")
# 全局实例,用于替代Milvus客户端
_simple_vector_db = None
def get_vector_db(db_path: str = None, collection_name: str = "documents", vector_dim: int = 1024):
"""获取向量数据库单例"""
global _simple_vector_db
if _simple_vector_db is None:
_simple_vector_db = SimpleVectorDB(collection_name, vector_dim)
return _simple_vector_db 工作流程:
- 员工向问答系统提问(例如:“公司的报销流程是怎样的?”)。
- ADK
enterprise_qna_agent接收到问题。
- 根据其
instruction,LLM 决定调用knowledge_retrieval_tool,并将问题作为查询参数。
knowledge_retrieval_tool将查询转换为向量,在企业向量数据库中搜索相关文档块,并(如果需要)根据用户权限过滤结果。
- 检索到的文档块作为上下文返回给
enterprise_qna_agent的 LLM。
- LLM 结合原始问题和检索到的上下文,生成一个基于企业知识的回答,并通过前端界面展示给员工。
需要注意的内容:
1、向量模型采用的是放在本地的 D:\module\BAAI-bge-large-zh-v1.5 模型
2、向量库暂时采用的是内存存储
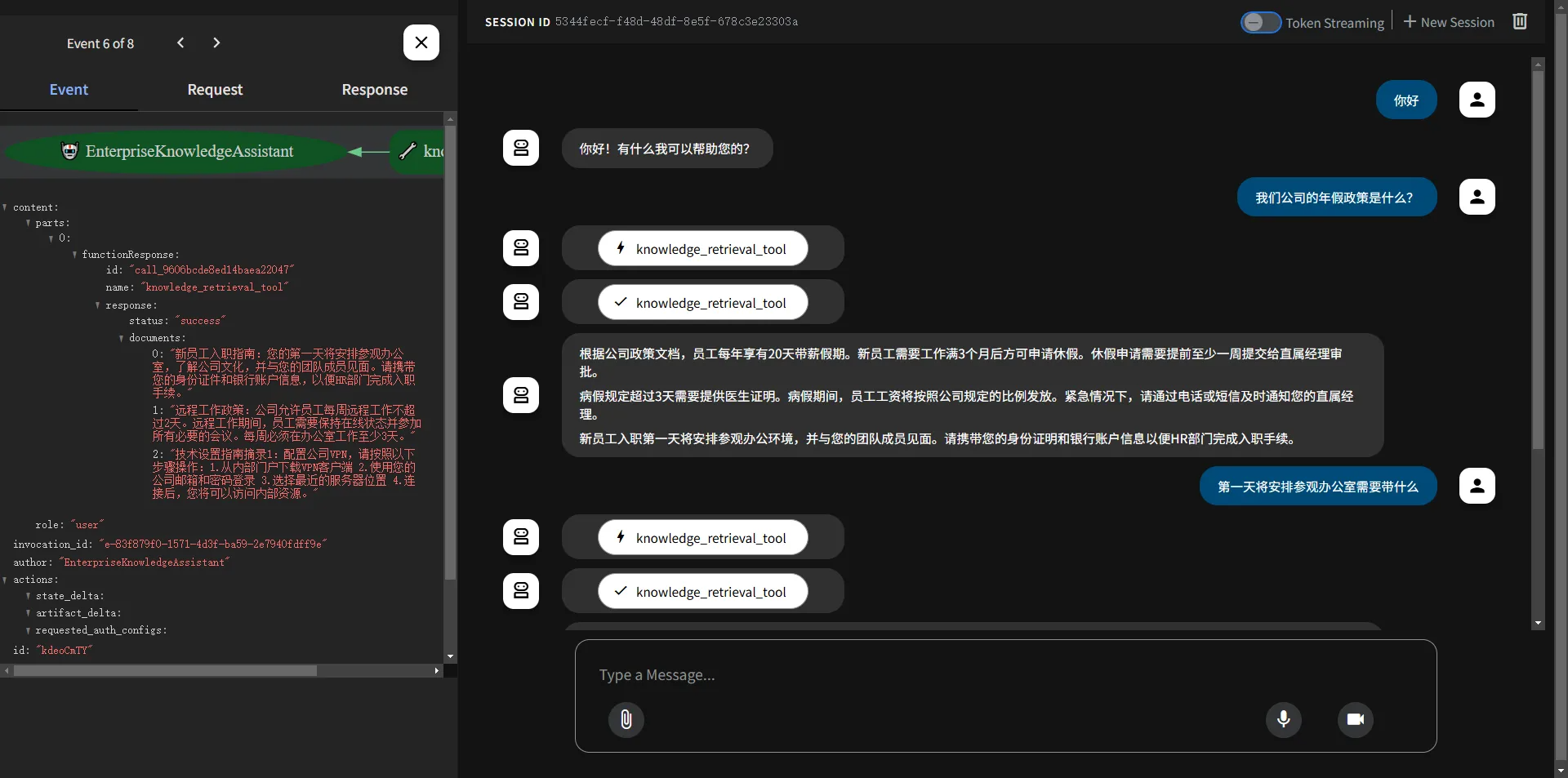
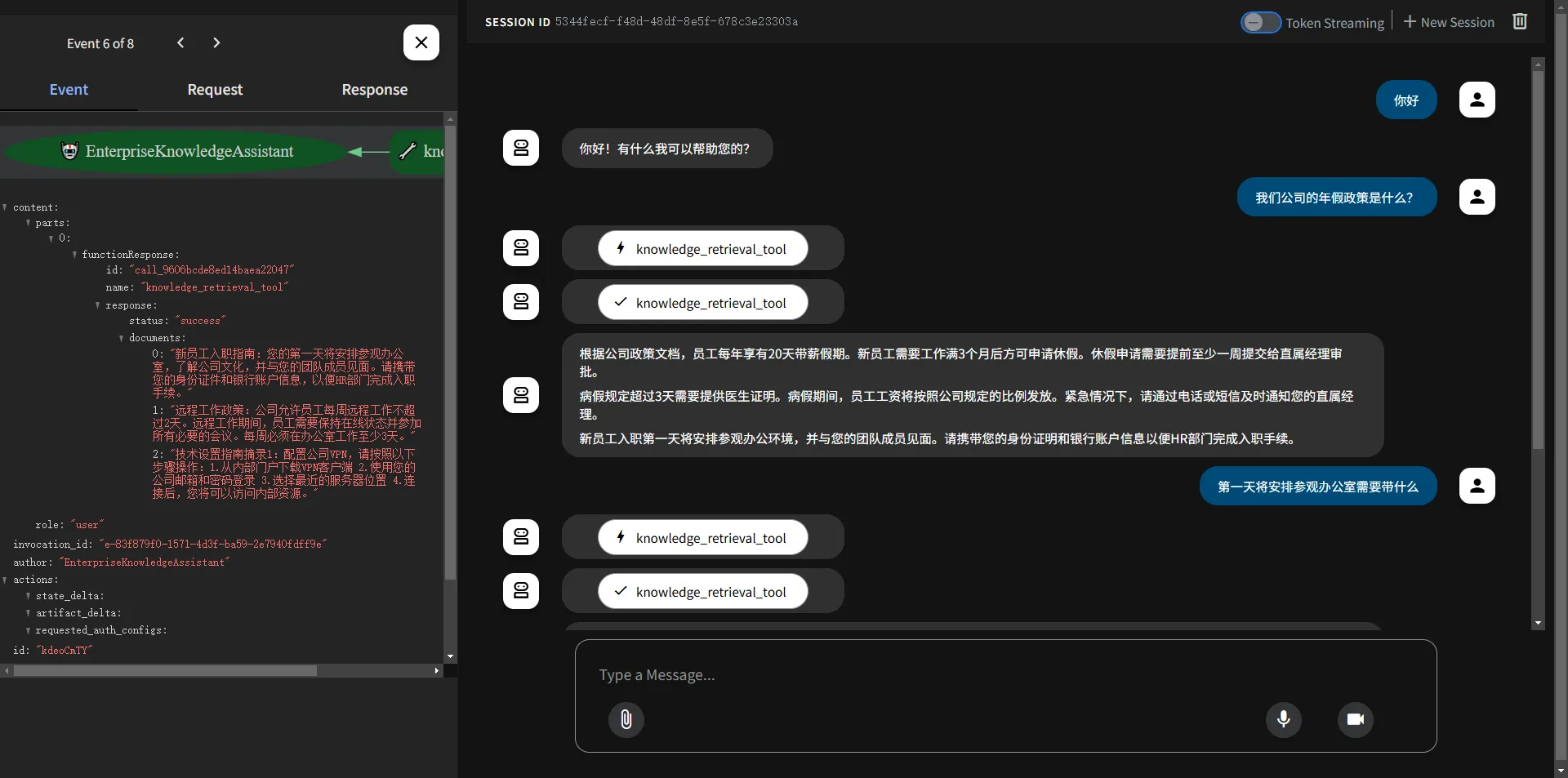
运行展示如下:输入知识库中的问答则可以调用知识库工具
总结与展望
通过将 ADK 与企业数据源、RAG 架构以及健全的安全机制相结合,我们可以构建出真正能够解决企业实际问题、提升运营效率的智能代理。从连接已有的数据库和 API,到赋予代理理解海量内部文档的能力,再到确保每一次交互都安全合规,ADK 提供了灵活而强大的工具集来应对这些挑战。
我们今天构建的企业知识库问答系统仅仅是一个开始。想象一下,这样的代理还可以扩展到自动化复杂业务流程、提供个性化客户支持、辅助进行数据分析与决策等更多高级场景。
在下一篇文章中,我们将继续探索 ADK 的更多高级特性与应用场景。敬请期待!

















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









