









Limited Data Rolling Bearing Fault Diagnosis With Few-Shot Learning
基于小样本学习的有限数据滚动轴承故障诊断

摘要
这一篇文章主要研究有限训练数据下的轴承故障诊断问题。故障诊断中的一个主要挑战是,在所有工作条件下,无法为每种故障类型获取足够的训练样本。近年来,基于深度学习的故障诊断方法取得了可喜的成果。然而,这些方法大多需要大量的训练数据。在这项研究中,我们提出了一种基于深度神经网络的小样本学习方法,用于有限数据的滚动轴承故障诊断。我们的模型基于孪生神经网络,通过利用相同或不同类别的样本对进行学习。在带有故障诊断基准数据集CWRU上的实验结果表明,在数据可用性有限的情况下,我们的小样本学习方法在故障诊断中更有效。当在不同的噪声环境下以最少的训练数据进行测试时,我们的少镜头学习模型的性能超过了具有合理噪声水平的基线模型。当使用新的故障类型或新的工作条件对测试集进行评估时,小样本模型比使用所有故障类型进行的基线训练工作得更好。
模型和数据集下载:链接: link.
背景
故障诊断广泛运用于我们日常生活中的各个方面,比如制造业、航天航空、汽车等等。今年来由于基于深度学习的智能故障诊断摆脱了耗时且不可信赖的人工分析的依赖,同时提高了故障诊断的效率而逐渐引起了人们的关注。然而传统的深度学习的方法,要求大量的训练数据,但在现实世界中相同故障的信号由于工作条件的不同存在着较大的差异,这就导致无法为每一类故障获取足够多的样本以保证故障分类的鲁棒性。(1)工业系统不允许在故障情况下运行;(2)大多数机电故障发生缓慢,并遵循退化路径,因此系统的故障退化可能需要数月甚至数年的时间,这使得收集相关数据集变得困难;(3)机械系统的工作条件非常复杂,并且经常根据生产要求随时发生变化。收集和标记足够多的训练样本是不现实的;(4)特别是在实际应用中,故障类别和工作条件通常是不平衡的。因此,在不同的工作条件下,很难为每种故障类型收集足够的样本。
如今深度学习已经被广泛运用到了故障诊断领域,并取得了最先进的结果,常见的方法如:自动编码(AE)、受限玻尔兹曼机(RBM)、卷积神经网络(CNN)、循环神经网络、基于神经网络的迁移学习和生成性对抗网络(GAN)等。
近来基于深度神经网络的小样本学习在解决故障诊断领域数据稀缺方面取得了巨大的进步。
小样本学习的一般性策略

小样本学习的一般策略如上图所示。首先,使用一组具有相同和不相同类别的样本对来进行模型训练,其中输入是含有相同和不同类的样本对(x_1i,x_2i ),其中i是第i个minibatch,输出是两个输入样本相同的概率p(x_1i,x_2i)。在测试过程中,将测试样本与一个N-shot K-way的支持集进行比较,找出相似概率最大的类,从而实现测试样本分类。
论文创新点(贡献)
(1) 提出了一种有限数据条件下进行故障诊断的学习方法,其基于首层宽卷积深度神经网络(WDCNN)的孪生神经网络模型(SNN);(关于WDCNN的相关概念可以查看此链接https://zhuanlan.zhihu.com/p/448901398)
(2) 首次证明了基于少量镜头学习的诊断模型可以充分利用相同或不同的类样本对,并从只有单个或少量样本的类中识别测试样本,从而提高故障诊断的性能;
(3) 随着训练样本数量的增加,当测试数据集与训练数据集存在显著差异时,测试性能不会单调增加。
方法(算法)论述
就整体结构而言,本文所提的方法由三个部分构成:数据准备、模型训练和模型测试,整体结构流程图如下:

上述流程图中,轴承故障诊断的小样本学习模型结构如下图所示:

在该网络模型中,两个相同的WDCNN网络采用相同的网络结构和共享权重。首层宽卷积深度神经网络(WDCNN)首先使用宽核来提取特征,然后使用小核来获得更好的特征表示。这样设计是基于一个模型全是小核的不现实性和第一层是小核容易受到工业环境中常见的高频噪声干扰的现实决定的。并利用WDCNN从原始的振动信号中提取特征,紧接着将孪生网络提取出来的特征取二范数d_f^2 (x_1i,x_2i )=‖f(x_1^i )-f(x_2i)‖进行距离度量,在此基础上计算两个输入样本的相似概率P(x_1i,x_2^i )=sigm(FC(d_f^2 (x_1i,x_2i ))),其中sigm为sigmoid函数,FC为一个稠密全连接层。
损失函数:正则化的交叉熵损失,损失函数如下:
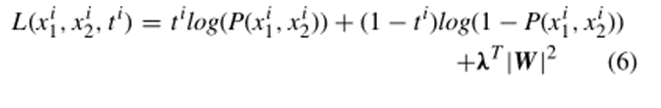
优化器:Adam优化器(为每个参数计算各自的学习率),参数更新过程如下:

训练
输入是含有相同和不同类的样本对(x_1i,x_2i ),其中i是第i个minibatch,输出是两个输入样本相同的概率p(x_1i,x_2i),紧接着计算正则化的交叉商损失函数,最后通过Adam优化器优化并更新参数。
测试
使用多次one-shot K-way测试模拟N-shot K-way测试,得到N个概率向量以后,通过以下公式计算最大概率和:
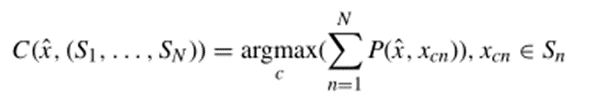
实验数据集
数据集选用西储大学轴承数据集中的12k驱动端轴承故障数据,其包含4个类型的轴承故障位置:正常,球故障,内圈故障和外圈故障。每一个故障包含三种尺寸类型:0.007英寸,0.014英寸和0.021英寸,因此总共有10种故障类型标签,每个故障标签包含1、2和3 hp的三种类型负载(电机转速分别为1772、1750和1730 RPM)。具体数据集如下表所示:

实验结果
首先,我们比较了深度学习算法和传统机器学习算法SVM的性能,使用不同数量的训练样本对提出的小样本(一个样本和五个样本)学习的诊断结果与WDCNN进行了比较。其结果如下图:

结论
本文提出了一种用于有限数据条件下滚动轴承故障诊断的小样本学习方法。该算法解决了有限数据故障诊断中的一个主要挑战:在数据驱动的故障诊断中难以获得足够数量的样本。我们的小样本故障诊断模型基于孪生神经网络进行单样本学习。它的工作原理是利用相同或不同类别的样本对,测量两个WDCNN输出的孪生特征向量的“距离”,即它们的输出是否被认为非常相似或不同。
该方法在CWRU数据集上通过与基础(流行的WDCNN故障诊断模型)的性能比较进行了大量实验验证。实验结果表明,无论是在有限的数据还是足够的数据条件下,小样本学习都能有效地进行故障诊断。通过比较不同噪声环境下的测试结果,我们发现训练集和测试集之间的巨大差异可能会导致测试性能不会随着训练样本数的增加而单调增加。当测试集出现新的故障类型或在新的工作条件下时,小样本模型在所有故障类型中比它基线训练模型工作的更好。















 340
340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









