







前言
之前学信号和DSP的时候,除了常见的离散傅里叶变换之外,还看过诸如离散余弦变换(DCT),短时傅里叶变换(STFT),小波变换等等,这些变换看似繁多且杂乱无章,但其实其背后的思想都是变换域的思想,引入某种变换,通常是正交变换,将时间相关的信号序列变换到另一个域上来进行分析。其实我觉得理解了这个思想之后,不需要太关注公式的推导,大致了解思想简单推导一下即可,毕竟有很多的包和函数都是集成化的。特此在这里做一个思路和代码的总结,由于小波变换相对没有那么常用,此处总结DCT,STFT和K-L变换。
一、从DFT到DCT
DCT全名为离散余弦变换,当然与之相对应的有离散正弦变换。事实上,DCT变换族中有16个成员,包括8种DST和8种DCT,具体对其进行划分的方式则是根据原始序列做对称的方式的不同来进行划分。例如:对称点两侧的序列是对称还是反对称,是轴对称还是中心对称,对称点是在离散序列的采样点上还是不在……总之,不同的对称形式决定了不同的DCT形式,这个公式具体的推导可以去参考一下比较经典的数字信号处理的教材,其公式推导的核心思想也就是运用了DFT中旋转因子的对称性。但是在本篇博客中主要关注的还是对思想的理解,以及结果代码的实现。
我们先来回顾一下经典的DFT公式的表达形式,其中:
W
N
k
n
=
e
−
j
2
π
N
k
n
W_N^{kn}=e^{-j\frac{2π}{N}kn}
WNkn=e−jN2πkn
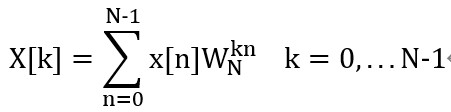
其对应的展开形式如下:
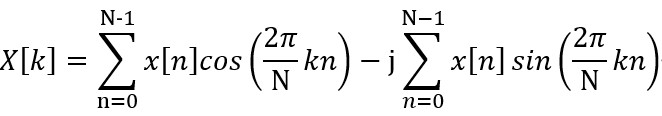
而在各种DCT和DST中,最常见的是2型DCT,因为其具有较好的能量压缩性质。因此接下来主要讨论2型的DCT,其公式如下:

这也属于一种正交变换,其本质原因是因为DCT的正交基还是没有脱离三角函数系,其采用的是余弦正交基,而余弦,正弦和复指数基本身就具有正交性。
我们可以比较一下DCT和DFT的展开形式,很容易发现:DCT中全为实数,没有复数,且只有余弦项,这降低了数值计算的复杂度,仔细分析就会发现,其实DCT中之所以只有实数,恰恰是因为利用了离散序列的对称性,类似于
e
j
w
n
+
e
−
j
w
n
e^{jwn}+e^{-jwn}
ejwn+e−jwn的形式得到的就是实数序列。
// 一维DCT函数代码如下,输入一个向量,得到一个向量,因此就不专门写主函数了
function output = dct(input)
%The One-dimensional DCT,input is a vector
N = length(input);
for i = 0:N-1
if i==0
a = sqrt(1/N);
else
a = sqrt(2/N);
end
sum = 0;
for j = 0:N-1
sum = sum+input(j+1)*cos(pi*(j+0.5)*i/N);
end
output(i+1) = a * sum;
end
end
仿真结果部分,这里参考了一位同学汇报的PPT,下图是原信号的时域离散波形:

而下图则为该信号进行了DFT和DCT之后的结果:

我们可以看到,有限长序列的2型DCT的系数通常比使用DFT得到对应的系数,更多集中在较低序号(对应较低频率)的部分(这个个人觉得可以从另一个角度去理解,做FFT时,高频部分一定会存在有低频部分的镜像分量,如上图“DFT实部和虚部“”的结果所示,但DCT可以避免这个问题),且我们发现在一般情况下,往往剩余部分的系数趋近于0,如上图的“DCT结果”部分所示,因此,说明DCT往往比DFT具有更好的能量压缩性质,因此,二维的DCT往往用于图像的压缩,例如我们熟悉的 图像JPEG标准。
接下来,我们从一维DCT过度到二维DCT,二维DCT的公式如下:
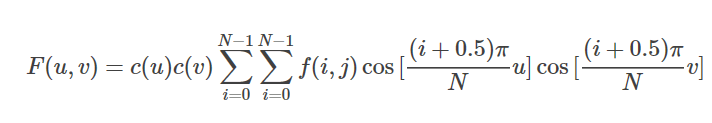
类比一维DCT,将上式写成矩阵形式,其中
c
(
i
)
c(i)
c(i)的取值同一维情况:
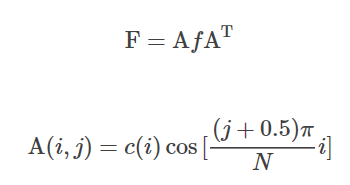
同样给出二维DCT的函数:
function output= dct2(input)
% Two-Dimensional DCT,input is a matrix
[height,width] = size(input);
if height==width %满足方阵的条件
N = height;
A = zeros(N);
for i=0:N-1
if i==0
c = sqrt(1/N);
else
c = sqrt(2/N);
end
for j=0:N-1
A(i+1,j+1) = c*cos(pi*(j+0.5)*i/N);
end
end
output= A*input*A';
else
disp('Error:input must be a square matrix !');
output=0;
end
二、从CTFT到STFT
我们熟悉的傅里叶变换只能反映出信号在频域的特性,无法在时域内对信号进行分析。为了将时域和频域相联系,短时傅里叶变换(short-time Fourier transform,简称为STFT)便应运而生,其实质是加窗的傅里叶变换。可以去看看参考资料中一篇关于STFT的博客(链接在最后)。
我拜读之后,简单做了总结,并加了一些理解和补充说明。信号x(t)的短时傅里叶变换定义如下,对比普通的连续傅里叶变换(CTFT),STFT在做傅里叶变换之前对
x
(
τ
)
x(\tau)
x(τ)先进行加窗,其窗函数的为有限长的
h
(
τ
)
h(\tau)
h(τ),当
h
(
τ
)
h(\tau)
h(τ)变为
h
(
τ
−
t
)
h(\tau-t)
h(τ−t)时,即相当于对窗函数进行了平移,即可以形象的认为是取出信号在分析时间点 t 附近的一个切片:
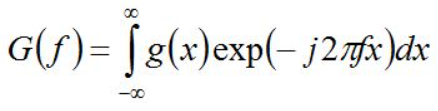

但是,以上的公式针对的都是连续信号,得到的
f
f
f在频域的取值也是无穷多个,然而在MATLAB仿真的过程中,只能进行数字信号处理,先给出代码,再进行说明。代码如下:
clc,clear;
%% 产生信号
fs = 1000; % 采样频率1KHz
N=1024;%对应傅里叶变换的点数
t = 0:1/fs:(N-1)/fs;
f1=20;
f2=60;
f3=150;
x=3*cos(2*pi*f1*t)+2*cos(2*pi*f2*t)+5*cos(2*pi*f3*t);%三个正弦信号的叠加
%% 短时傅里叶变换
window_length=500;%设置窗口长度,窗口越长时间分辨率越差。
step=1;%每次平移的步长,最小为1,步长越小时间精度越好。
h=hamming(window_length);%设置海明窗的窗长
%wlen-hop代表每次重叠的部分的点数
%F代表频率向量,F的取值为N/2+1;T代表时间向量,step为1时,T的取值为N-wlen+1
[B, F, T, P] = spectrogram(x,h,window_length-step,N,fs); % B是F行T列的频率峰值,P是对应的能量谱密度
figure;
imagesc(T,F,P);%画图函数
set(gca,'YDir','normal')%让Y轴刻度顺序设置为正常
colorbar;
xlabel('时间 t/s');
ylabel('频率 f/Hz');
title('短时傅里叶时频图');
接下来分析以上代码,调用这个函数之后,返回的向量F代表频率轴,而返回的向量T代表时间轴,而矩阵P则代表了相应的幅度(功率值),P的
s
i
z
e
size
size由向量F和T决定。那么F和T的
s
i
z
e
size
size又是多少呢?我们先看T,由于系统需要满足因果性,我们假定时刻t从0开始,那么一开始窗函数的区间就是从
0
0
0-window_length,假设step为1,即每次向右平移1个,那些就有
N
−
w
l
e
n
+
1
N-wlen+1
N−wlen+1个时间。再看F,如刚才所说,F的区间是连续的,如何将其离散化,那么需要确定频率分辨率以及频率的分布区间。首先根据奈奎斯特采样定理,采样率
f
s
fs
fs一定的时候,如果我们不想使其发生混叠,信号的频率不会超过
0.5
f
s
0.5fs
0.5fs,因此这即为我们考虑的区间上限(下限为0),同时频率分辨率为
f
s
N
\frac{fs}{N}
Nfs,即采样率和变换点数一定的时候,频率分辨率就已经确定了,因此,F的size即为
N
2
+
1
\frac{N}{2}+1
2N+1,对应
N
2
\frac{N}{2}
2N个间隔。(也可以这么理解,N点序列作傅里叶变换后得到N点序列,而后面的N/2个点就是前面N/2个点的镜像分量,没有必要考虑)
三、K-L变换与降维思想
在machine learning中,我们经常需要防止数据的维度过高,而这就需要用到降维的思想。常见的降维有:直接降维,线性降维和非线性降维,而线性降维中常见的方法则是PCA(主成分分析,也称为K-L变换,以下统称用PCA)。
PCA的核心思想即为将一组线性相关的变量,通过正交变换,变换成一组线性无关的变量,从信号空间理论的角度可以理解为对原始特征空间的重构。在PCA中,有最大投影方差和最小重构距离两种主流思路,最终可推导出相同的结果。事实上,也可以从概率的角度对PCA进行展开,限于篇幅,只给出最终结论,具体请参考AI圣经:PRML。
对于一组数据集{
x
n
x_n
xn},其中的每个
x
n
x_n
xn都在一个
D
D
D维空间中,即研究如何将数据投影到
M
<
D
M<D
M<D的
M
M
M维空间中。具体方法如下:定义
x
n
x_n
xn为样本集合的均值,即
x
ˉ
=
∑
n
=
1
N
x
n
\bar{x}=\sum_{n=1}^Nx_n
xˉ=∑n=1Nxn,而定义数据的协方差矩阵(covariance matrix):
S
=
1
N
⋅
∑
n
=
1
N
(
x
n
−
x
ˉ
)
(
x
n
−
x
ˉ
)
T
S=\frac{1}{N} \cdot \sum_{n=1}^N (x_n-\bar{x})(x_n-\bar{x})^T
S=N1⋅∑n=1N(xn−xˉ)(xn−xˉ)T.对矩阵
S
S
S进行特征值分解,对于降维到
M
M
M维空间的情况,则选出
M
M
M个最大的特征值对应的特征向量,即可得到新的
M
M
M维空间中的一组基。
以上就是PCA的理论部分,但是当涉及到具体实现的时候,我们就会发现,往往原有的空间维数
D
D
D是远远高于样本数量
N
N
N的,就拿我们最常见的图像为例,可能一个图像有100万个像素点,但是样本个数只有大概100个。这样的话,如果直接运行PCA就变的行不通了,因为会遇到
D
⋅
D
D \cdot D
D⋅D 超大矩阵求逆的世界难题,同时,我们会发现这样得到的特征值至少有
D
−
N
+
1
D-N+1
D−N+1个为0,因为N个数据点的线性子空间的维数最多为
N
−
1
N-1
N−1,因此,我们需要采样如下的方法,具体推导可以参考PRML的高维PCA部分,这里给出最终结论:
1.定义
X
X
X为
D
⋅
N
D\cdot N
D⋅N维中心数据矩阵,它的第
n
n
n列即为
(
x
n
−
x
ˉ
)
(x_n-\bar{x})
(xn−xˉ)。
2.求解
S
1
=
X
T
⋅
X
S_1=X^T \cdot X
S1=XT⋅X,此时
S
1
S1
S1的维度为
N
⋅
N
N \cdot N
N⋅N,对其进行奇异值分解,得到特征值
λ
i
\lambda_{i}
λi的集合和特征向量
v
i
v_{i}
vi的集合,每一个
v
i
v_{i}
vi都为
N
N
N维向量。
3.
u
i
=
1
λ
i
⋅
X
⋅
v
i
,
i
=
0
,
1
,
2
,
⋯
,
p
u_i=\frac{1}{\sqrt{\lambda_{i}}}\cdot X \cdot v_{i}, i=0,1,2, \cdots, p
ui=λi1⋅X⋅vi,i=0,1,2,⋯,p,此时每一个
u
i
u_{i}
ui都为
D
D
D维向量,即为
p
p
p个
D
D
D维向量构成了高维空间的线性子空间的一组基。
K-L变换的具体应用请看下一节的人脸识别实例。
四、K-L变换实例:人脸识别(含代码和详细注释)
%% 两组图像数据的读取
clear,clc;
train_files = dir('F1');%返回目录中的文件()
all_train = [];%样本矩阵
first_number=3;
last_number=102;
image_number = last_number-first_number+1;%图片总共的数目
for i = first_number : last_number
train_file_name = train_files(i).name;%读图片名
train_file_name=strcat('F1','\',train_file_name);%字符拼接函数
sample_figure= imread(train_file_name);%从指定的文件读取一幅图像
[row,col]=size(sample_figure);
pixel_number=row*col;%图片像素点数目
temp=reshape(sample_figure,pixel_number,1);%返回一个m*1的矩阵temp,将二维图像数据变成一维列向量
all_train=[all_train,temp];%将所有图片数据变成一个样本矩阵,一个列向量对应一个高维空间
end
test_files = dir('F2');%返回目录中的文件()
all_test = [];%测试矩阵
for i = first_number : last_number
test_file_name = test_files(i).name;
test_file_name=strcat('F2','\',test_file_name);
test = imread(test_file_name);
[row,col]=size(test);
test_temp=reshape(test,row*col,1);%返回一个m*1的矩阵temp,将二维图像数据变成一维列向量
all_test=[all_test,test_temp];%将所有图片数据变成一个样本矩阵
end
%% 主成分分析(PCA)
average_train= mean(all_train,2); %返回行的平均值,即100个图片的平均值
%计算每个图像与均值的差
for i=1:image_number
A(:,i)=double(all_train(:,i))-average_train;%需要先将allsample转化为双精度(double)类型
end
%计算协方差矩阵的特征矢量和特征值
L =(A'*A); %由SVD理论构造矩阵L=A'*A用于计算特征值和特征向量
%本来是A*A',由于复杂度过高,提出改进算法
[V,D] = eig(L);%计算矩阵A的特征值D和特征向量矩阵V,特征向量得到的是归一化特征向量
d1=diag(D);%会自动按升序排序
% 按特征值大小以降序排列
d_sort = flipud(d1);%实现上下翻转
v_sort = fliplr(V);%实现左右翻转,实现特征值和特征向量矩阵的对应
%以下选择80%的能量
d_sum = sum(d_sort);%将数组中元素进行求和
d_sum_temp = 0;
main_number = 0;%特征值主分量个数
while( d_sum_temp/d_sum < 0.8)
main_number = main_number + 1;
d_sum_temp = sum(d_sort(1:main_number));
end
%计算新空间中的基
for i=1:main_number
U(:,i)=(d_sort(i)^(-1/2))*A*v_sort(:,i); %PRML公式12.30,此处没有N是因为之前SVD的时候没有带N
end
%U即为新空间中的一组基,每一个列向量代表一个基,main_number个基张成高维空间的线性子空间
%% 对测试集中的人脸进行识别
for i=1:image_number
test_A(:,i)=double(all_test(:,i))-average_train;%此处应该是减去average_train,因为需要相同的映射规则
end
%计算训练集中人脸在特征空间中的投影表示,每一列代表一个图片在新空间中的坐标
train_projection=U'*A; %可理解为做内积
%计算测试集中人脸在特征空间中的投影表示,每一列代表一个图片在新空间中的坐标
test_projection=U'*test_A;
%测试集中人脸和训练集中人脸相似性进行匹配
projection_match=zeros(main_number,image_number);
success_number=0;%sum1为匹配成功的数目
position=zeros(image_number,1);
temp_vector=zeros(main_number,image_number);
diffrence_vector=zeros(image_number,1);%用于存储一个特定的测试数据坐标和之前每一个训练数据坐标的距离
for i=1:image_number %测试集中的第i个图片数据
for j=1:image_number
temp_vector(:,j)=test_projection(:,i)-train_projection(:,j);
diffrence_vector(j)=norm(temp_vector(:,j), 2);
end
[~,position(i)]=min(diffrence_vector);%找到最小距离对应训练集中的位置,存在position(i)中
if(i==position(i))
success_number=success_number+1;
end
end
accuracy_rate=(success_number/image_number);
display(accuracy_rate);%输出准确率
%% 随机抽取5个图形做代表显示匹配效果
%两组图片的相同编号,对应同一个人两张不同的图
for i=1:5
ri=(round(100*rand(1,1)));
figure(i);
subplot(121);
r=all_train(:,ri);
imshow(reshape(r,142,120));
title(train_files(ri).name,'FontWeight','bold','Fontsize',15,'color','red');
subplot(122);
k=position(ri);
imshow(reshape(all_test(:,k),142,120));
title(test_files(k).name,'FontWeight','bold','Fontsize',15,'color','red');
end















 2809
2809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









