







数据的描述性统计
Sim_Jackson | 2023
- 经常出现的数据描述性统计表格,在研究论文中多出现在<数据与变量>章节,描述所获得的数据。
实证类论文
-
[1] 付志刚,沈慧娟,王伟,傅国彬,周路军.机构投资者调研行为动机:推高股价,抑或拉升业绩?[J].投资研究,2021,40(10):88-102.
描述:
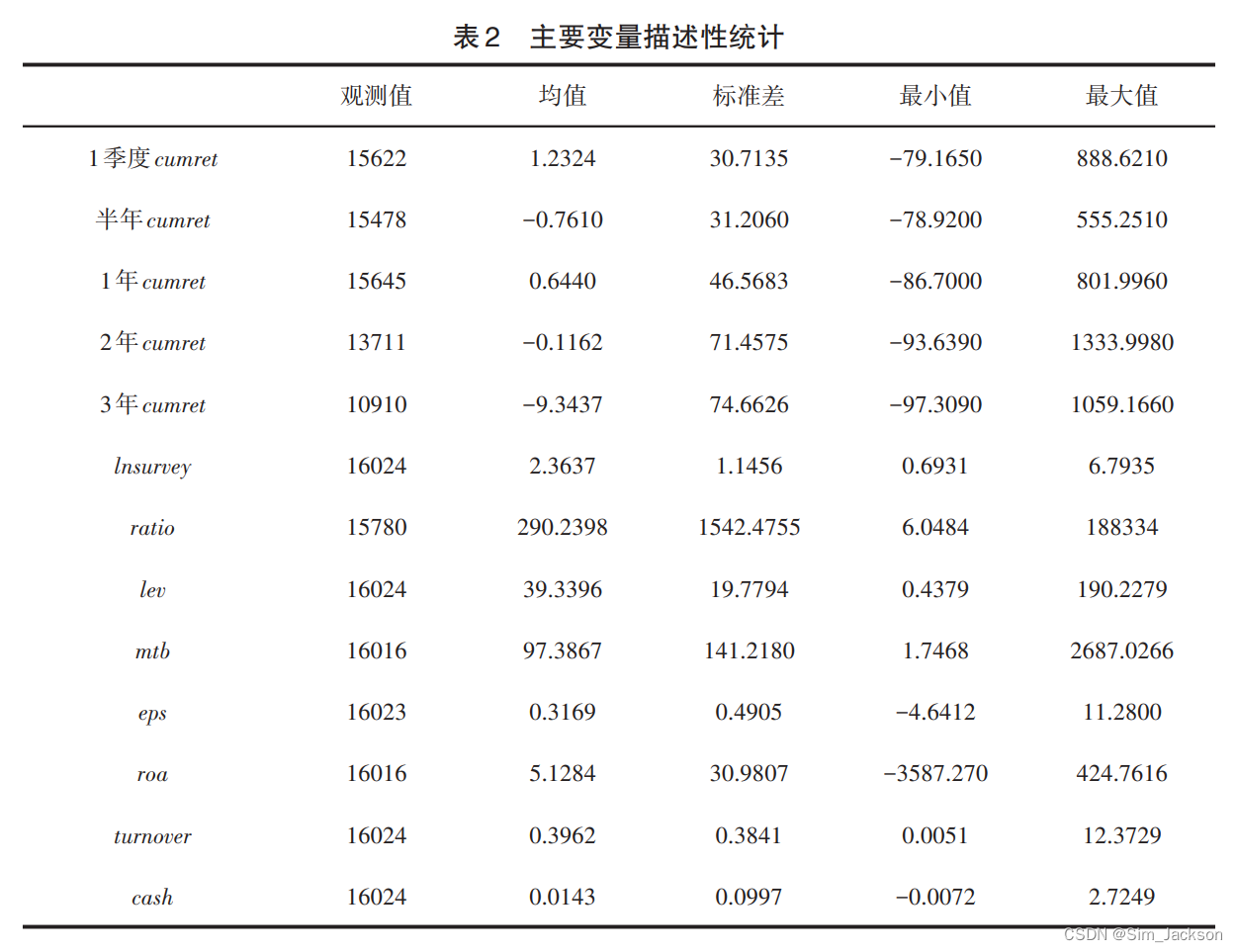
“运用python软件对数据进行整理,并得到上述变量的描述性统计如表2所示。在整个样本时内,不同时间段的累积收益率出现较大的差异,其中机构投资者调研1季度后,股价平均上涨1.2324,半年后,股价平均上涨-0.7610,说明呈现下降,1年后股价平均上涨 0.6440,而 2年后至 3年后股价又呈现下跌的趋势。这说明机构投资者调研后,股价仍先上升后下跌、再上升再下跌的波动特征。”
“ 机构投资者调研平均每季达到 2.3637 次,对应标准差为 1.1456,其中最小达到 0.6931,最大达到6.7935。 说明机构投资者对不同股票的关注度存在差异,其中某些股票可能正处于当时热点板块,则关注度较高;有些股票虽然业绩较好,可能并不是热点,关注度可能会比较小。”
时间序列分析类论文
- [2] 范丽伟,董欢欢,渐令.基于滚动时间窗的碳市场价格分解集成预测研究[J/OL].中国管理科学:1-14[2023-01-17].

# 导入需要的第三方库
import pandas as pd
import os
import warnings
warnings.filterwarnings('ignore')
dir_ = r'D:\科研论文\Python\数据分析'
os.chdir(dir_)
files = os.listdir(dir_) # 将该地址下的文件都列出来
files # finaldata为填补完缺失值之后的数据
['data.xlsx', 'finaldata.csv', 'google.csv', 'reaseach_data.xlsx']
# 数据读取
df = pd.read_csv(files[1]) # 1即为第2个,'finaldata.csv'
df
| time | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2020-01-02 | 6985.47 | 3257.85 | 1527.100000 | 96.81 | 61.18 | 12.47 | 2.13 | 4 | 49 | 72 |
| 1 | 2020-01-03 | 7344.88 | 3234.85 | 1548.750000 | 96.91 | 63.04 | 14.02 | 2.11 | 8 | 47 | 65 |
| 2 | 2020-01-06 | 7769.22 | 3246.28 | 1573.100000 | 96.62 | 62.83 | 13.85 | 2.15 | 7 | 46 | 14 |
| 3 | 2020-01-07 | 8163.69 | 3237.18 | 1567.850000 | 96.96 | 62.69 | 13.79 | 2.16 | 7 | 35 | 17 |
| 4 | 2020-01-08 | 8079.86 | 3253.05 | 1571.950000 | 97.34 | 59.98 | 13.45 | 2.15 | 10 | 53 | 57 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 752 | 2022-12-23 | 16796.95 | 3844.82 | 1789.400408 | 104.32 | 79.35 | 20.87 | 5.12 | 44 | 65 | 12 |
| 753 | 2022-12-27 | 16717.17 | 3829.25 | 1789.400408 | 104.20 | 79.87 | 21.65 | 5.21 | 47 | 58 | 0 |
| 754 | 2022-12-28 | 16552.57 | 3783.22 | 1803.350000 | 104.53 | 78.86 | 22.14 | 4.71 | 50 | 40 | 18 |
| 755 | 2022-12-29 | 16642.34 | 3849.28 | 1813.750000 | 103.97 | 78.71 | 21.44 | 4.56 | 51 | 67 | 44 |
| 756 | 2022-12-30 | 16602.59 | 3839.50 | 1789.400408 | 103.49 | 80.51 | 21.67 | 4.43 | 42 | 53 | 25 |
757 rows × 11 columns
df.describe()
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 757.000000 | 757.000000 | 757.000000 | 757.000000 | 757.000000 | 757.000000 | 757.000000 | 757.000000 | 757.000000 | 757.000000 |
| mean | 28911.789841 | 3861.127292 | 1789.400408 | 97.445548 | 67.226354 | 24.850159 | 4.122411 | 53.768824 | 48.177015 | 28.348745 |
| std | 17146.077185 | 551.471131 | 100.947388 | 6.094840 | 24.565988 | 8.753701 | 2.136611 | 27.310592 | 20.301897 | 23.541417 |
| min | 4970.790000 | 2237.400000 | 1474.250000 | 89.410000 | 12.930000 | 12.100000 | 1.440000 | 4.000000 | 10.000000 | 0.000000 |
| 25% | 11601.470000 | 3401.200000 | 1733.550000 | 92.710000 | 45.520000 | 19.370000 | 2.480000 | 28.000000 | 31.000000 | 11.000000 |
| 50% | 23336.000000 | 3915.590000 | 1790.450000 | 96.080000 | 68.220000 | 23.140000 | 3.620000 | 63.000000 | 47.000000 | 23.000000 |
| 75% | 43160.930000 | 4319.940000 | 1857.350000 | 100.350000 | 85.030000 | 27.990000 | 5.600000 | 75.000000 | 62.000000 | 43.000000 |
| max | 67566.830000 | 4796.560000 | 2067.150000 | 114.150000 | 124.770000 | 82.690000 | 9.760000 | 100.000000 | 100.000000 | 100.000000 |
释义:
count:样本量
mean:平均值
std:标准差
min:最小值
25%:1/4分位数
50%:中位数
df1 = df.drop(columns = 'time')
collst=df1.columns
collst
Index(['X1', 'X2', 'X3', 'X4', 'X5', 'X6', 'X7', 'X8', 'X9', 'X10'], dtype='object')
# 偏度
print("偏度统计结果为:")
for col in collst:
print(col,round(df1[col].skew(),2))
偏度统计结果为:
X1 0.36
X2 -0.47
X3 -0.36
X4 0.87
X5 0.07
X6 2.55
X7 0.77
X8 -0.53
X9 0.41
X10 0.82
# 峰度
print("峰度统计结果为:")
for col in collst:
print(col,round(df1[col].kurt(),2))
峰度统计结果为:
X1 -1.17
X2 -0.5
X3 0.2
X4 -0.18
X5 -0.75
X6 10.53
X7 -0.48
X8 -1.06
X9 -0.52
X10 0.19


















 3416
3416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









