






TEXT2SEG: REMOTE SENSING IMAGE SEMANTIC SEGMENTATION VIA TEXT-GUIDED VISUAL FOUNDATION MODELS
机构:University of Georgia Athens, Georgia;University of Virginia Charlottesville, Virginia
代码:https://github.com/Douglas2Code/Text2Seg
TEXT2SEG使用用现有的、通用的、比较好的视觉基础模型,生成SAM中的prompt,再来指导SAM更好理解图像语义特征。
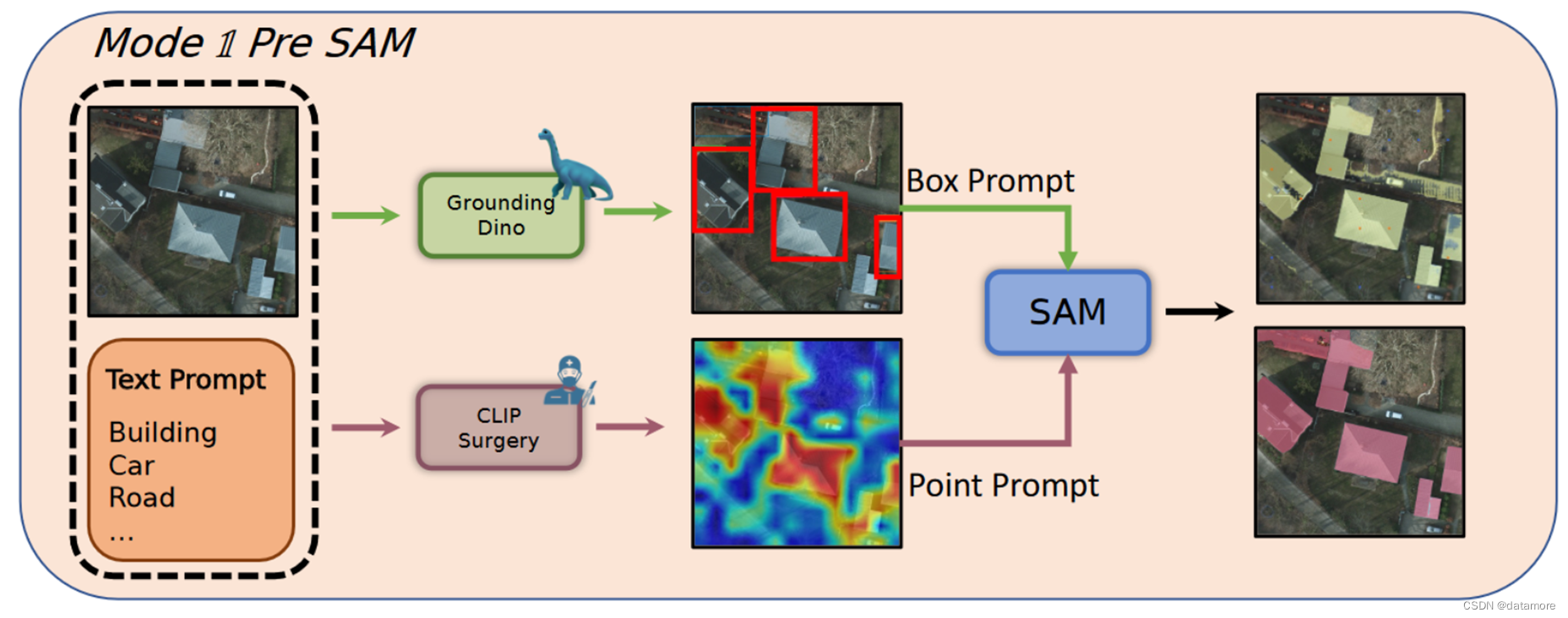
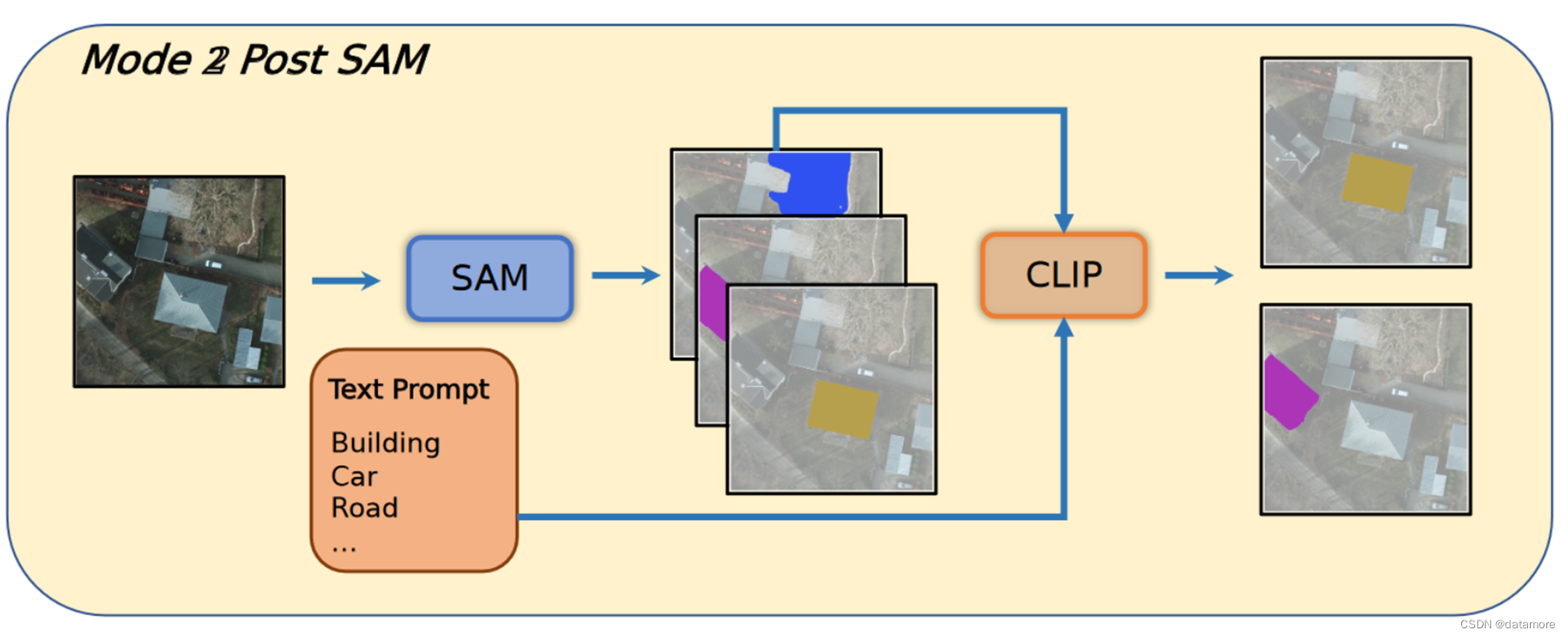
用到了Groounding DINO和CLIP Surgery
Grounding DINO将 DINO 与开放集目标检测结合起来,Grounding DINO可以根据文字描述检测指定目标。
CLIP Surgery是一种专门针对CLIP模型的解释方法。通过使用文本提示,CLIP Surgery 可以生成准确突出显示相应区域的解释图。这些解释图作为弱分割结果。
















 911
911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









