标签,采用滑动窗口的方式,构造训练集的时候针对产生购买的行为标记为1 整合特征 def get_labels ( start_date, end_date, all_actions) :
actions = get_actions( start_date, end_date, all_actions)
actions = actions[ ( actions[ 'type' ] == 4 ) & ( actions[ 'cate' ] == 8 ) ]
actions = actions. groupby( [ 'user_id' , 'sku_id' ] , as_index= False ) . sum ( )
actions[ 'label' ] = 1
actions = actions[ [ 'user_id' , 'sku_id' , 'label' ] ]
return actions
train_start_date = '2016-03-01'
train_actions = None
all_actions = get_all_action( )
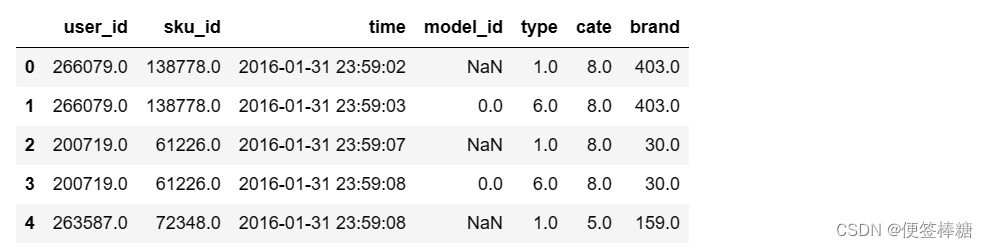
all_actions. head( )
user = get_basic_user_feat( )
product = get_basic_product_feat( )
train_start_date = '2016-03-01'
train_end_date = datetime. strptime( train_start_date, '%Y-%m-%d' ) + timedelta( days= 3 )
train_end_date
train_end_date = train_end_date. strftime( '%Y-%m-%d' )
start_days = datetime. strptime( train_end_date, '%Y-%m-%d' ) - timedelta( days= 30 )
start_days = start_days. strftime( '%Y-%m-%d' )
user_acc = get_recent_user_feat( train_end_date, all_actions)
def make_actions ( user, product, all_actions, train_start_date) :
train_end_date = datetime. strptime( train_start_date, '%Y-%m-%d' ) + timedelta( days= 3 )
train_end_date = train_end_date. strftime( '%Y-%m-%d' )
start_days = datetime. strptime( train_end_date, '%Y-%m-%d' ) - timedelta( days= 30 )
start_days = start_days. strftime( '%Y-%m-%d' )
print ( train_end_date)
user_acc = get_recent_user_feat( train_end_date, all_actions)
print ( 'get_recent_user_feat finsihed' )
user_cate = get_user_cate_feature( train_start_date, train_end_date, all_actions)
print ( 'get_user_cate_feature finished' )
product_acc = get_accumulate_product_feat( start_days, train_end_date, all_actions)
print ( 'get_accumulate_product_feat finsihed' )
cate_acc = get_accumulate_cate_feat( start_days, train_end_date, all_actions)
print ( 'get_accumulate_cate_feat finsihed' )
comment_acc = get_comments_product_feat( train_end_date)
print ( 'get_comments_product_feat finished' )
test_start_date = train_end_date
test_end_date = datetime. strptime( test_start_date, '%Y-%m-%d' ) + timedelta( days= 5 )
test_end_date = test_end_date. strftime( '%Y-%m-%d' )
labels = get_labels( test_start_date, test_end_date, all_actions)
print ( "get labels" )
actions = None
for i in ( 3 , 5 , 7 , 10 , 15 , 21 , 30 ) :
start_days = datetime. strptime( train_end_date, '%Y-%m-%d' ) - timedelta( days= i)
start_days = start_days. strftime( '%Y-%m-%d' )
if actions is None :
actions = get_action_feat( start_days, train_end_date, all_actions, i)
else :
actions = pd. merge( actions, get_action_feat( start_days, train_end_date, all_actions, i) , how= 'left' ,
on= [ 'user_id' , 'sku_id' , 'cate' ] )
actions = pd. merge( actions, user, how= 'left' , on= 'user_id' )
actions = pd. merge( actions, user_acc, how= 'left' , on= 'user_id' )
actions = pd. merge( actions, user_cate, how= 'left' , on= 'user_id' )
actions = pd. merge( actions, product, how= 'left' , on= [ 'sku_id' , 'cate' ] )
actions = pd. merge( actions, product_acc, how= 'left' , on= 'sku_id' )
actions = pd. merge( actions, cate_acc, how= 'left' , on= 'cate' )
actions = pd. merge( actions, comment_acc, how= 'left' , on= 'sku_id' )
actions = pd. merge( actions, labels, how= 'left' , on= [ 'user_id' , 'sku_id' ] )
actions = actions. fillna( 0 )
action_postive = actions[ actions[ 'label' ] == 1 ]
action_negative = actions[ actions[ 'label' ] == 0 ]
del actions
neg_len = len ( action_postive) * 10
action_negative = action_negative. sample( n= neg_len)
action_sample = pd. concat( [ action_postive, action_negative] , ignore_index= True )
return action_sample
def make_train_set ( train_start_date, setNums , f_path, all_actions) :
train_actions = None
user = get_basic_user_feat( )
print ( 'get_basic_user_feat finsihed' )
product = get_basic_product_feat( )
print ( 'get_basic_product_feat finsihed' )
for i in range ( setNums) :
print ( train_start_date)
if train_actions is None :
train_actions = make_actions( user, product, all_actions, train_start_date)
else :
train_actions = pd. concat( [ train_actions, make_actions( user, product, all_actions, train_start_date) ] ,
ignore_index= True )
train_start_date = datetime. strptime( train_start_date, '%Y-%m-%d' ) + timedelta( days= 1 )
train_start_date = train_start_date. strftime( '%Y-%m-%d' )
print ( "round {0}/{1} over!" . format ( i+ 1 , setNums) )
train_actions. to_csv( f_path, index= False )
all_actions = get_all_action( )
train_start_date = '2016-02-01'
train_end_date = datetime. strptime( train_start_date, '%Y-%m-%d' ) + timedelta( days= 3 )
train_end_date
train_end_date = train_end_date. strftime( '%Y-%m-%d' )
start_days = datetime. strptime( train_end_date, '%Y-%m-%d' ) - timedelta( days= 30 )
start_days = start_days. strftime( '%Y-%m-%d' )
user_cate = get_user_cate_feature( train_start_date, train_end_date, all_actions)
product_acc = get_accumulate_product_feat( start_days, train_end_date, all_actions)
cate_acc = get_accumulate_cate_feat( start_days, train_end_date, all_actions)
comment_acc = get_comments_product_feat( train_end_date)
train_start_date = '2016-02-01'
make_train_set( train_start_date, 20 , 'train_set.csv' , all_actions)
def make_val_answer ( val_start_date, val_end_date, all_actions, label_val_s1_path) :
actions = get_actions( val_start_date, val_end_date, all_actions)
actions = actions[ ( actions[ 'type' ] == 4 ) & ( actions[ 'cate' ] == 8 ) ]
actions = actions[ [ 'user_id' , 'sku_id' ] ]
actions = actions. drop_duplicates( )
actions. to_csv( label_val_s1_path, index= False )
def make_val_set ( train_start_date, train_end_date, val_s1_path) :
start_days = datetime. strptime( train_end_date, '%Y-%m-%d' ) - timedelta( days= 30 )
start_days = start_days. strftime( '%Y-%m-%d' )
all_actions = get_all_action( )
print ( "get all actions!" )
user = get_basic_user_feat( )
print ( 'get_basic_user_feat finsihed' )
product = get_basic_product_feat( )
print ( 'get_basic_product_feat finsihed' )
user_acc = get_recent_user_feat( train_end_date, all_actions)
print ( 'get_recent_user_feat finsihed' )
user_cate = get_user_cate_feature( train_start_date, train_end_date, all_actions)
print ( 'get_user_cate_feature finished' )
product_acc = get_accumulate_product_feat( start_days, train_end_date, all_actions)
print ( 'get_accumulate_product_feat finsihed' )
cate_acc = get_accumulate_cate_feat( start_days, train_end_date, all_actions)
print ( 'get_accumulate_cate_feat finsihed' )
comment_acc = get_comments_product_feat( train_end_date)
print ( 'get_comments_product_feat finished' )
actions = None
for i in ( 3 , 5 , 7 , 10 , 15 , 21 , 30 ) :
start_days = datetime. strptime( train_end_date, '%Y-%m-%d' ) - timedelta( days= i)
start_days = start_days. strftime( '%Y-%m-%d' )
if actions is None :
actions = get_action_feat( start_days, train_end_date, all_actions, i)
else :
actions = pd. merge( actions, get_action_feat( start_days, train_end_date, all_actions, i) , how= 'left' ,
on= [ 'user_id' , 'sku_id' , 'cate' ] )
actions = pd. merge( actions, user, how= 'left' , on= 'user_id' )
actions = pd. merge( actions, user_acc, how= 'left' , on= 'user_id' )
actions = pd. merge( actions, user_cate, how= 'left' , on= 'user_id' )
actions = pd. merge( actions, product, how= 'left' , on= [ 'sku_id' , 'cate' ] )
actions = pd. merge( actions, product_acc, how= 'left' , on= 'sku_id' )
actions = pd. merge( actions, cate_acc, how= 'left' , on= 'cate' )
actions = pd. merge( actions, comment_acc, how= 'left' , on= 'sku_id' )
actions = actions. fillna( 0 )
val_start_date = train_end_date
val_end_date = datetime. strptime( val_start_date, '%Y-%m-%d' ) + timedelta( days= 5 )
val_end_date = val_end_date. strftime( '%Y-%m-%d' )
make_val_answer( val_start_date, val_end_date, all_actions, 'label_' + val_s1_path)
actions. to_csv( val_s1_path, index= False )
make_val_set( '2016-02-23' , '2016-02-26' , 'val_3.csv' )
def make_test_set ( train_start_date, train_end_date) :
start_days = datetime. strptime( train_end_date, '%Y-%m-%d' ) - timedelta( days= 30 )
start_days = start_days. strftime( '%Y-%m-%d' )
all_actions = get_all_action( )
print "get all actions!"
user = get_basic_user_feat( )
print 'get_basic_user_feat finsihed'
product = get_basic_product_feat( )
print 'get_basic_product_feat finsihed'
user_acc = get_recent_user_feat( train_end_date, all_actions)
print 'get_accumulate_user_feat finsihed'
user_cate = get_user_cate_feature( train_start_date, train_end_date, all_actions)
print 'get_user_cate_feature finished'
product_acc = get_accumulate_product_feat( start_days, train_end_date, all_actions)
print 'get_accumulate_product_feat finsihed'
cate_acc = get_accumulate_cate_feat( start_days, train_end_date, all_actions)
print 'get_accumulate_cate_feat finsihed'
comment_acc = get_comments_product_feat( train_end_date)
actions = None
for i in ( 3 , 5 , 7 , 10 , 15 , 21 , 30 ) :
start_days = datetime. strptime( train_end_date, '%Y-%m-%d' ) - timedelta( days= i)
start_days = start_days. strftime( '%Y-%m-%d' )
if actions is None :
actions = get_action_feat( start_days, train_end_date, all_actions, i)
else :
actions = pd. merge( actions, get_action_feat( start_days, train_end_date, all_actions, i) , how= 'left' ,
on= [ 'user_id' , 'sku_id' , 'cate' ] )
actions = pd. merge( actions, user, how= 'left' , on= 'user_id' )
actions = pd. merge( actions, user_acc, how= 'left' , on= 'user_id' )
actions = pd. merge( actions, user_cate, how= 'left' , on= 'user_id' )
actions = pd. merge( actions, product, how= 'left' , on= [ 'sku_id' , 'cate' ] )
actions = pd. merge( actions, product_acc, how= 'left' , on= 'sku_id' )
actions = pd. merge( actions, cate_acc, how= 'left' , on= 'cate' )
actions = pd. merge( actions, comment_acc, how= 'left' , on= 'sku_id' )
actions = actions. fillna( 0 )
actions. to_csv( "test_set.csv" , index= False )
sub_start_date = '2016-04-13'
sub_end_date = '2016-04-16'
make_test_set( sub_start_date, sub_end_date)
import sys
import pandas as pd
import numpy as np
import xgboost as xgb
from sklearn. model_selection import train_test_split
import operator
from matplotlib import pylab as plt
from datetime import datetime
import time
from sklearn. model_selection import GridSearchCV
data = pd. read_csv( 'train_set.csv' )
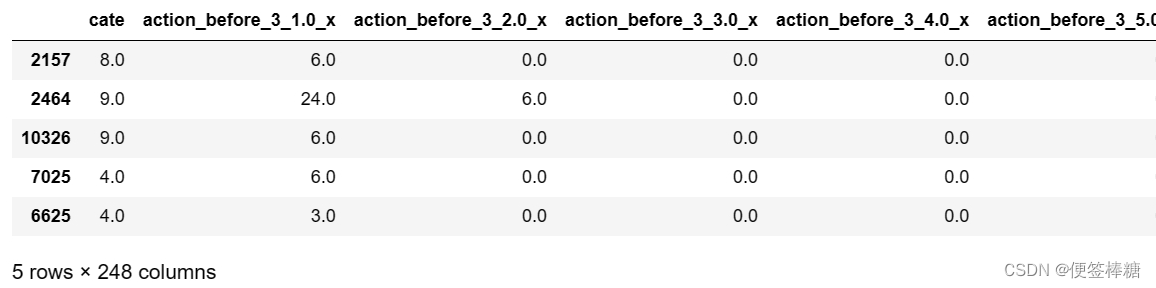
data. head( )
data. columns
data_x = data. loc[ : , data. columns != 'label' ]
data_y = data. loc[ : , data. columns == 'label' ]
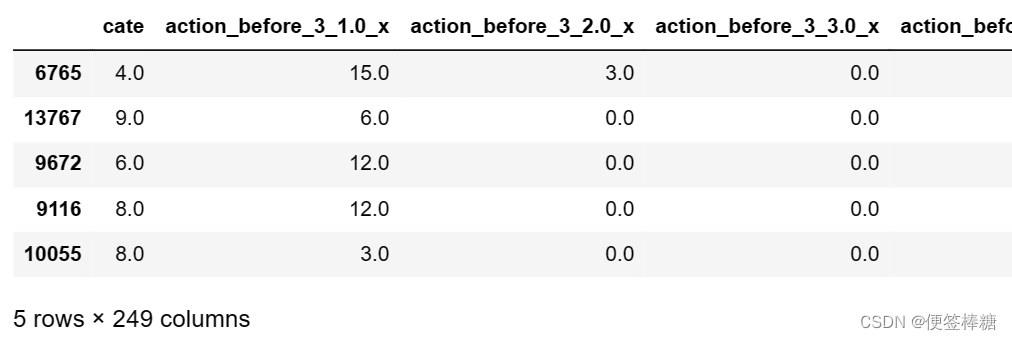
data_x. head( )
data_y. head( )
x_train, x_test, y_train, y_test = train_test_split( data_x, data_y, test_size = 0.2 , random_state = 0 )
x_test. shape
x_val = x_test. iloc[ : 1500 , : ]
y_val = y_test. iloc[ : 1500 , : ]
x_test = x_test. iloc[ 1500 : , : ]
y_test = y_test. iloc[ 1500 : , : ]
del x_train[ 'user_id' ]
del x_train[ 'sku_id' ]
del x_val[ 'user_id' ]
del x_val[ 'sku_id' ]
x_train. head( )
dtrain = xgb. DMatrix( x_train, label= y_train)
dvalid = xgb. DMatrix( x_val, label= y_val)
param = { 'n_estimators' : 4000 , 'max_depth' : 3 , 'min_child_weight' : 5 , 'gamma' : 0 , 'subsample' : 1.0 ,
'colsample_bytree' : 0.8 , 'scale_pos_weight' : 10 , 'eta' : 0.1 , 'silent' : 1 , 'objective' : 'binary:logistic' ,
'eval_metric' : 'auc' }
num_round = param[ 'n_estimators' ]
plst = param. items( )
evallist = [ ( dtrain, 'train' ) , ( dvalid, 'eval' ) ]
bst = xgb. train( plst, dtrain, num_round, evallist, early_stopping_rounds= 10 )
bst. save_model( 'bst.model' )
print ( bst. attributes( ) )
def create_feature_map ( features) :
outfile = open ( r'xgb.fmap' , 'w' )
i = 0
for feat in features:
outfile. write( '{0}\t{1}\tq\n' . format ( i, feat) )
i = i + 1
outfile. close( )
features = list ( x_train. columns[ : ] )
create_feature_map( features)
def feature_importance ( bst_xgb) :
importance = bst_xgb. get_fscore( fmap= r'xgb.fmap' )
importance = sorted ( importance. items( ) , key= operator. itemgetter( 1 ) , reverse= True )
df = pd. DataFrame( importance, columns= [ 'feature' , 'fscore' ] )
df[ 'fscore' ] = df[ 'fscore' ] / df[ 'fscore' ] . sum ( )
file_name = 'feature_importance_' + str ( datetime. now( ) . date( ) ) [ 5 : ] + '.csv'
df. to_csv( file_name)
feature_importance( bst)
fi = pd. read_csv( 'feature_importance_10-24.csv' )
fi. sort_values( "fscore" , inplace= True , ascending= False )
fi. head( )
users = x_test[ [ 'user_id' , 'sku_id' , 'cate' ] ] . copy( )
del x_test[ 'user_id' ]
del x_test[ 'sku_id' ]
x_test_DMatrix = xgb. DMatrix( x_test)
y_pred = bst. predict( x_test_DMatrix, ntree_limit= bst. best_ntree_limit)
x_test[ 'pred_label' ] = y_pred
x_test. head( )
def label ( column) :
if column[ 'pred_label' ] > 0.5 :
column[ 'pred_label' ] = 1
else :
column[ 'pred_label' ] = 0
return column
x_test = x_test. apply ( label, axis = 1 )
x_test[ 'true_label' ] = y_test
x_test[ 'user_id' ] = users[ 'user_id' ]
x_test[ 'sku_id' ] = users[ 'sku_id' ]
x_test. head( )
all_user_set = x_test[ x_test[ 'true_label' ] == 1 ] [ 'user_id' ] . unique( )
print ( len ( all_user_set) )
all_user_test_set = x_test[ x_test[ 'pred_label' ] == 1 ] [ 'user_id' ] . unique( )
print ( len ( all_user_test_set) )
all_user_test_item_pair = x_test[ x_test[ 'pred_label' ] == 1 ] [ 'user_id' ] . map ( str ) + '-' + x_test[ x_test[ 'pred_label' ] == 1 ] [ 'sku_id' ] . map ( str )
all_user_test_item_pair = np. array( all_user_test_item_pair)
print ( len ( all_user_test_item_pair) )
pos, neg = 0 , 0
for user_id in all_user_test_set:
if user_id in all_user_set:
pos += 1
else :
neg += 1
all_user_acc = 1.0 * pos / ( pos + neg)
all_user_recall = 1.0 * pos / len ( all_user_set)
print ( '所有用户中预测购买用户的准确率为 ' + str ( all_user_acc) )
print ( '所有用户中预测购买用户的召回率' + str ( all_user_recall) )
all_user_item_pair = x_test[ x_test[ 'true_label' ] == 1 ] [ 'user_id' ] . map ( str ) + '-' + x_test[ x_test[ 'true_label' ] == 1 ] [ 'sku_id' ] . map ( str )
all_user_item_pair = np. array( all_user_item_pair)
pos, neg = 0 , 0
for user_item_pair in all_user_test_item_pair:
if user_item_pair in all_user_item_pair:
pos += 1
else :
neg += 1
all_item_acc = 1.0 * pos / ( pos + neg)
all_item_recall = 1.0 * pos / len ( all_user_item_pair)
print ( '所有用户中预测购买商品的准确率为 ' + str ( all_item_acc) )
print ( '所有用户中预测购买商品的召回率' + str ( all_item_recall) )
F11 = 6.0 * all_user_recall * all_user_acc / ( 5.0 * all_user_recall + all_user_acc)
F12 = 5.0 * all_item_acc * all_item_recall / ( 2.0 * all_item_recall + 3 * all_item_acc)
score = 0.4 * F11 + 0.6 * F12
print ( 'F11=' + str ( F11) )
print ( 'F12=' + str ( F12) )
print ( 'score=' + str ( score) )

































 100
100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









