






情感预测之Fastai 结合 HuggingFace Transformers
Fastai是一个基于PyTorch的深度学习库,提供了一系列用于训练和部署深度学习模型的高级API。 它简化了深度学习的许多常见任务,包括计算机视觉、文本分类和自然语言处理。
HuggingFace Transformers是一个开源的NLP库,提供了一系列预训练的模型和用于处理文本数据的工具。 它支持多种常见的预训练模型架构,包括BERT、RoBERTa、XLNet、XLM和DistilBERT等。 这些模型在大规模文本语料库上进行了预训练,可以通过微调适应特定的NLP任务,如文本分类、命名实体识别和问答等。
Fastai with HuggingFace Transformers结合了Fastai和HuggingFace Transformers的功能,使得在NLP任务中使用预训练模型更加简单和高效。 它提供了一套易于使用的API,可以轻松地加载、微调和训练HuggingFace Transformers中的模型。 此外,它还提供了一些方便的功能,如数据预处理、批处理和模型推断等。
(一) NLP中的迁移学习
1. NLP
自然语言处理(Natural Language Processing,NLP)是一门与人类语言和计算机之间的交互以及语言数据处理相关的领域。NLP致力于将人类语言的特征和规律应用于计算机系统中,使计算机能够理解、处理和生成自然语言。
NLP涉及多个子任务和技术,其中包括:
-
语言理解:语言理解是指使计算机能够理解和解释人类语言的能力。这包括词法分析(分词、词性标注)、句法分析(句子结构分析)、语义分析(意图识别、命名实体识别)和语篇理解(文本关联、指代消解)等。
-
机器翻译:机器翻译涉及将一种语言的文本自动转化为另一种语言的文本。这是一个复杂的任务,需要处理语言之间的词汇差异、句法结构和语义差异等。
-
信息检索与问答:信息检索和问答系统旨在根据用户提供的查询,从大量的文本数据中检索相关的信息或直接回答用户的问题。这涉及到关键词匹配、语义匹配、信息抽取和逻辑推理等技术。
-
文本分类与情感分析:文本分类是将文本划分到预定义的类别或标签中,常见的应用包括文本垃圾邮件过滤、情感分析(分析文本的情感倾向)和主题分类等。
-
文本生成:文本生成任务涉及自动生成符合语法和语义规则的自然语言文本。这包括语言模型的训练、文本摘要、对话系统和机器创作等。
2. 迁移学习
迁移学习(Transfer Learning)是一种机器学习方法,旨在通过在一个任务上学习到的知识和经验,来改善在另一个相关任务上的性能。在传统的机器学习中,通常每个任务都需要独立地收集和标注大量的数据进行训练,而迁移学习可以利用已有的数据和模型,从而在新任务上更有效地进行学习。
迁移学习的主要思想是将源领域(source domain)上学习到的知识迁移到目标领域(target domain)上。这可以通过以下方式实现:
-
特征提取:从源领域的数据中学习到的特征可以迁移到目标领域上。在源领域上训练的模型可以作为特征提取器,提取出数据的共享特征,然后将这些特征用于目标领域的模型训练。
-
知识迁移:源领域上的模型的参数和知识可以迁移到目标领域上的模型中。这可以通过使用预训练模型、模型微调或使用模型的部分层来实现。迁移的知识可以包括权重、模型结构、注意力权重等。
迁移学习的优势包括:
-
数据效率:迁移学习可以利用源领域上的丰富数据进行预训练,从而减少目标领域上需要标注的数据量,提高数据效率。
-
泛化能力:源领域上的知识可以帮助目标领域上的学习,提高模型的泛化能力和性能。
-
加速训练过程:通过利用预训练模型的参数或特征提取能力,可以加速目标领域上模型的训练过程。
迁移学习在自然语言处理(NLP)领域得到了广泛的应用。例如,使用在大规模文本数据上预训练的语言模型(如BERT、GPT)进行迁移学习,在下游任务(如文本分类、命名实体识别)上可以取得良好的效果。
(二)将tramsformers与 fastai 集成以实现多类分类
1. 库安装
%%bash
pip install -q transformers
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from pathlib import Path
import os
import torch
import torch.optim as optim
import random
# fastai
from fastai import *
from fastai.text import *
from fastai.callbacks import *
# transformers
from transformers import PreTrainedModel, PreTrainedTokenizer, PretrainedConfig
from transformers import BertForSequenceClassification, BertTokenizer, BertConfig
from transformers import RobertaForSequenceClassification, RobertaTokenizer, RobertaConfig
from transformers import XLNetForSequenceClassification, XLNetTokenizer, XLNetConfig
from transformers import XLMForSequenceClassification, XLMTokenizer, XLMConfig
from transformers import DistilBertForSequenceClassification, DistilBertTokenizer, DistilBertConfi
import fastai
import transformers
print('fastai version :', fastai.__version__)
print('transformers version :', transformers.__version__)
2. 示例任务
所选任务是电影评论上的多类文本分类。
对于每个文本电影评论,模型必须预测情绪的标签。我们评估模型的输出的分类准确性。情绪标签为:
0 → 差评
1 → 有点负面
2 →中立
3 → 有点积极
4 →好评
数据被加载到使用 .DataFramepandas
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))

DATA_ROOT = Path("..") / "/ entiment-analysis-on-movie-reviews"
train = pd.read_csv(DATA_ROOT / 'train.tsv.zip', sep="\t")
test = pd.read_csv(DATA_ROOT / 'test.tsv.zip', sep="\t")
print(train.shape,test.shape)
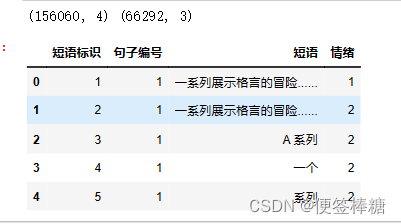
train.head()
看一下数据集的样子:
3. 主要变压器类
每个模型体系结构都与 3 种主要类型的类相关联:transformers
- 用于加载/存储特定预训练模型的模型类。
- 一个分词器类,用于预处理数据并使其与特定模型兼容。
- 用于加载/存储特定模型的配置的配置类。
如果要使用 Bert 体系结构进行文本分类,则可以对模型类使用 BertForSequenceClassification,对分词器类使用 BertTokenizer,对配置类使用 BertConfig。
为了在类之间轻松切换 ,每个类都与特定的模型类型相关,我创建了一个字典,该字典允许通过指定正确的模型类型名称来加载正确的类。
MODEL_CLASSES = {
'bert': (BertForSequenceClassification, BertTokenizer, BertConfig),
'xlnet': (XLNetForSequenceClassification, XLNetTokenizer, XLNetConfig),
'xlm': (XLMForSequenceClassification, XLMTokenizer, XLMConfig),
'roberta': (RobertaForSequenceClassification, RobertaTokenizer, RobertaConfig),
'distilbert': (DistilBertForSequenceClassification, DistilBertTokenizer, DistilBertConfig)
}
这段代码定义了一个名为MODEL_CLASSES的Python字典,用于存储不同类型的预训练模型的相关信息。字典中的键是预训练模型的名称,而对应的值是一个包含三个元素的元组。每个元组中的三个元素分别是相应预训练模型的类、标记器和配置类。
让我们一行一行解释代码:
-
MODEL_CLASSES = {: 这行代码开始定义MODEL_CLASSES字典。 -
'bert': (BertForSequenceClassification, BertTokenizer, BertConfig),: 这行代码将’BERT’作为键,对应的值是一个包含三个元素的元组。这三个元素是:BertForSequenceClassification: 一个类,用于进行序列分类任务的BERT模型。BertTokenizer: 一个类,用于将输入文本转换为BERT模型可接受的标记。BertConfig: 一个类,包含BERT模型的配置参数。
-
'xlnet': (XLNetForSequenceClassification, XLNetTokenizer, XLNetConfig),: 这行代码将’XLNet’作为键,对应的值也是一个包含三个元素的元组,分别是XLNet模型相关的类和配置。 -
'xlm': (XLMForSequenceClassification, XLMTokenizer, XLMConfig),: 这行代码将’XLM’作为键,对应的值也是一个包含三个元素的元组,分别是XLM模型相关的类和配置。 -
'roberta': (RobertaForSequenceClassification, RobertaTokenizer, RobertaConfig),: 这行代码将’Roberta’作为键,对应的值也是一个包含三个元素的元组,分别是Roberta模型相关的类和配置。 -
'distilbert': (DistilBertForSequenceClassification, DistilBertTokenizer, DistilBertConfig): 这行代码将’distilbert’作为键,对应的值也是一个包含三个元素的元组,分别是DistilBERT模型相关的类和配置。
最终,MODEL_CLASSES字典包含了不同预训练模型的名称与相关类和配置的映射关系,方便后续在代码中根据模型名称获取相应的类和配置信息。这种设计通常在构建通用模型训练和推理工具时非常有用,因为可以通过字符串名称来选择所需的模型和相关组件,而不需要显式地引入和实例化特定的类。
# Parameters
seed = 42
use_fp16 = False
bs = 16
model_type = 'roberta'
pretrained_model_name = 'roberta-base'
# model_type = 'bert'
# pretrained_model_name='bert-base-uncased'
# model_type = 'distilbert'
# pretrained_model_name = 'distilbert-base-uncased'
#model_type = 'xlm'
#pretrained_model_name = 'xlm-clm-enfr-1024'
# model_type = 'xlnet'
# pretrained_model_name = 'xlnet-base-cased'
model_class, tokenizer_class, config_class = MODEL_CLASSES[model_type]
model_class.pretrained_model_archive_map.keys()
设置参数,并选择了一个特定的预训练语言模型用于后续的使用。
-
seed = 42:这行代码将随机种子设置为42。设置随机种子可以确保代码中的随机操作每次运行时都产生相同的结果,用于保证模型训练和评估的可复现性。 -
use_fp16 = False:这行代码将变量use_fp16设置为False。它表示是否使用16位浮点数(半精度)进行计算。当设置为True时,可以加快模型训练和推理的速度,但会牺牲数值精度。 -
bs = 16:这行代码将变量bs设置为16,表示在训练和推理过程中所使用的批处理大小。批处理大小决定在每次模型训练和推理时并行处理的样本数量。 -
model_type = 'roberta':这行代码将变量model_type设置为’roberta’,表示选择了Roberta模型作为预训练语言模型。 -
pretrained_model_name = 'roberta-base':这行代码将变量pretrained_model_name设置为’roberta-base’,指定了Roberta模型的具体变种。在这种情况下,'roberta-base’代表Roberta模型的一个较小版本。 -
接下来的几行代码被使用了
#符号注释掉了。这些代码提供了其他选项的model_type和pretrained_model_name。通过取消注释和注释这些行,用户可以轻松地在不同的预训练语言模型(BERT、DistilBERT、XLM、XLNet或Roberta)及其对应的变体之间进行切换。 -
model_class, tokenizer_class, config_class = MODEL_CLASSES[model_type]:这行代码从MODEL_CLASSES字典中获取所选择的model_type对应的类。MODEL_CLASSES在代码的其他地方可能已经定义好了,其中包含模型类型(例如,‘roberta’、'bert’等)与相应类(模型、标记器和配置类)之间的映射关系。在这里,它获取了与Roberta模型相关的类。 -
model_class.pretrained_model_archive_map.keys():最后,这行代码访问所选model_class的pretrained_model_archive_map属性。pretrained_model_archive_map是一个字典,它将模型名称映射到预训练权重的下载链接。通过使用keys()方法,它显示了所选model_type(在这里是Roberta)的所有可用预训练模型名称。
这段代码主要用于根据所选的model_type和pretrained_model_name配置语言模型、标记器和配置类。通过这种方式,用户可以轻松地在不同的预训练语言模型及其变体之间进行切换,而无需手动更改代码的其余部分。
这些模型类型是:transformers
- BERT (from Google)
- XLNet (from Google/CMU)
- XLM (from Facebook)
- RoBERTa (from Facebook)
- DistilBERT (from HuggingFace)
4. 其他功能
设置用于生成随机数的种子的函数:
def seed_all(seed_value):
random.seed(seed_value) # Python
np.random.seed(seed_value) # cpu vars
torch.manual_seed(seed_value) # cpu vars
if torch.cuda.is_available():
torch.cuda.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value) # gpu vars
torch.backends.cudnn.deterministic = True #needed
torch.backends.cudnn.benchmark = False
这是一个用于设置随机种子(seed)的函数。它通过设置不同的随机种子,以确保在模型训练和评估过程中产生的随机性行为都是可复现的。函数中使用了Python标准库的random模块、NumPy库和PyTorch库。
让我们逐行解释这个函数:
-
def seed_all(seed_value):: 这行代码定义了一个名为seed_all的函数,并设置一个输入参数seed_value,用于接收要设置的随机种子值。 -
random.seed(seed_value): 这行代码使用random模块,将Python内置的随机数生成器的种子设置为seed_value。这样,在代码中使用random模块产生的随机性行为都会受到该种子的影响,保证了代码的可重复性。 -
np.random.seed(seed_value): 这行代码使用NumPy库,将NumPy中的随机数生成器的种子设置为seed_value。类似于Python内置的random模块,NumPy中的随机数生成器在设置了种子后,产生的随机数序列将是可复现的。 -
torch.manual_seed(seed_value): 这行代码使用PyTorch库,将PyTorch的CPU随机数生成器的种子设置为seed_value。在模型训练和评估过程中,如果使用了CPU计算,设置了这个种子后,随机性行为也将是可复现的。 -
if torch.cuda.is_available():: 这行代码检查当前环境是否支持CUDA(GPU计算),如果支持则进入下面的代码块。 -
torch.cuda.manual_seed(seed_value): 这行代码使用PyTorch库,将PyTorch的CUDA随机数生成器的种子设置为seed_value。在使用GPU计算时,设置了这个种子后,随机性行为也将是可复现的。 -
torch.cuda.manual_seed_all(seed_value): 这行代码设置所有可用的GPU设备的随机数生成器种子为seed_value。这确保了在多GPU环境下,所有GPU计算的随机性行为都是可复现的。 -
torch.backends.cudnn.deterministic = True: 这行代码设置PyTorch的CuDNN库在每次运行时使用相同的算法,以确保GPU计算的结果也是可复现的。通常,CuDNN会根据硬件和其他因素优化计算,但这会导致不同运行之间的计算结果不一致。将deterministic属性设置为True可以禁用这种优化,保证结果的可重复性。 -
torch.backends.cudnn.benchmark = False: 这行代码禁用了PyTorch的CuDNN的自动寻找最适合当前硬件的最优算法的功能。确保了计算的可复现性。
5. 数据预处理
- 为了匹配预训练,须以特定格式格式化模型输入序列。
- 首先对文本进行标记化,然后正确地对文本进行数字化。
- 问题难点在于,将微调的每个预训练模型都需要与预训练部分使用的预处理完全相同的特定预处理标记化和数字化。
- 幸运的是,transformers类提供了与每个预训练模型相对应的正确预处理工具。
在库中,数据预处理是在创建,分词器和数数器以 以下格式在处理器参数中传递:fastaiDataBunchDataBunch
processor = [TokenizeProcessor(tokenizer=tokenizer,…), NumericalizeProcessor(vocab=vocab,…)]
首先分析如何在函数中集成分词器。transformersTokenizeProcessor
5.1 自定义分词器
TokenizeProcessor 对象将对象作为参数。tokenizerTokenizer
分词器对象将对象作为参数。tok_funcBaseTokenizer
对象实现接受文本并返回其标记列表的函数。tokenizer(t:str) → List[str]t
因此,我们可以简单地创建一个继承并覆盖新函数的新类。TransformersBaseTokenizerBaseTokenizertokenizer
class TransformersBaseTokenizer(BaseTokenizer):
"""Wrapper around PreTrainedTokenizer to be compatible with fast.ai"""
def __init__(self, pretrained_tokenizer: PreTrainedTokenizer, model_type = 'bert', **kwargs):
self._pretrained_tokenizer = pretrained_tokenizer
self.max_seq_len = pretrained_tokenizer.max_len
self.model_type = model_type
def __call__(self, *args, **kwargs):
return self
def tokenizer(self, t:str) -> List[str]:
"""Limits the maximum sequence length and add the spesial tokens"""
CLS = self._pretrained_tokenizer.cls_token
SEP = self._pretrained_tokenizer.sep_token
if self.model_type in ['roberta']:
tokens = self._pretrained_tokenizer.tokenize(t, add_prefix_space=True)[:self.max_seq_len - 2]
tokens = [CLS] + tokens + [SEP]
else:
tokens = self._pretrained_tokenizer.tokenize(t)[:self.max_seq_len - 2]
if self.model_type in ['xlnet']:
tokens = tokens + [SEP] + [CLS]
else:
tokens = [CLS] + tokens + [SEP]
return tokens
transformer_tokenizer = tokenizer_class.from_pretrained(pretrained_model_name)
transformer_base_tokenizer = TransformersBaseTokenizer(pretrained_tokenizer = transformer_tokenizer, model_type = model_type)
fastai_tokenizer = Tokenizer(tok_func = transformer_base_tokenizer, pre_rules=[], post_rules=[])

注意:
- 由于不使用 RNN,因此须将序列长度限制为模型输入大小。
- 大多数模型都需要在序列的开头和结尾放置特殊的标记。
- 某些模型(如 RoBERTa)需要一个空格来开始输入字符串。对于这些模型,应调用编码方法,设置为 add_prefix_spaceTrue
bert: [CLS] + tokens + [SEP] + padding
roberta: [CLS] + prefix_space + tokens + [SEP] + padding
distilbert: [CLS] + tokens + [SEP] + padding
xlm: [CLS] + tokens + [SEP] + padding
xlnet: padding + tokens + [SEP] + [CLS]
5.2 自定义取数器
NumericalizeProcessor 对象将 Vocab 对象作为参数,分析建议两种方法来适应fastai数字器:fastaivocab
- 创建一个继承自、覆盖和函数的新类。TransformersVocabVocabnumericalizetextify
- 使用函数和分别在Transformersconvert_tokens_to_ids和convert_ids_to_tokensnumericalizetextify中
class TransformersVocab(Vocab):
def __init__(self, tokenizer: PreTrainedTokenizer):
super(TransformersVocab, self).__init__(itos = [])
self.tokenizer = tokenizer
def numericalize(self, t:Collection[str]) -> List[int]:
"Convert a list of tokens `t` to their ids."
return self.tokenizer.convert_tokens_to_ids(t)
#return self.tokenizer.encode(t)
def textify(self, nums:Collection[int], sep=' ') -> List[str]:
"Convert a list of `nums` to their tokens."
nums = np.array(nums).tolist()
return sep.join(self.tokenizer.convert_ids_to_tokens(nums)) if sep is not None else self.tokenizer.convert_ids_to_tokens(nums)
def __getstate__(self):
return {'itos':self.itos, 'tokenizer':self.tokenizer}
def __setstate__(self, state:dict):
self.itos = state['itos']
self.tokenizer = state['tokenizer']
self.stoi = collections.defaultdict(int,{v:k for k,v in enumerate(self.itos)})
注意:函数load_learner和函数 gestate____setstate__TransformersVocab允许导出并正常工作
5.3 定制处理器
现在有了自定义分词器和数字器,接下来创建自定义处理器。
transformer_vocab = TransformersVocab(tokenizer = transformer_tokenizer)
numericalize_processor = NumericalizeProcessor(vocab=transformer_vocab)
tokenize_processor = TokenizeProcessor(tokenizer=fastai_tokenizer, include_bos=False, include_eos=False)
transformer_processor = [tokenize_processor, numericalize_processor]
6. 设置数据组
对于 DataBunch 创建,须注意将处理器参数设置为我们新的自定义处理器并正确管理填充。transformer_processor
正如HuggingFace教程中提到的,BERT,RoBERTa,XLM和DistilBERT是具有绝对位置嵌入的模型,因此通常将输入填充在右侧而不是左侧。关于XLNET,它是一个具有相对位置嵌入的模型,因此在右侧或左侧填充输入。
pad_first = bool(model_type in ['xlnet'])
pad_idx = transformer_tokenizer.pad_token_id
tokens = transformer_tokenizer.tokenize('Salut c est moi, Hello it s me')
print(tokens)
ids = transformer_tokenizer.convert_tokens_to_ids(tokens)
print(ids)
transformer_tokenizer.convert_ids_to_tokens(ids)

检查批处理和分词器:
databunch = (TextList.from_df(train, cols='Phrase', processor=transformer_processor)
.split_by_rand_pct(0.1,seed=seed)
.label_from_df(cols= 'Sentiment')
.add_test(test)
.databunch(bs=bs, pad_first=pad_first, pad_idx=pad_idx))
检查批处理和分词器:
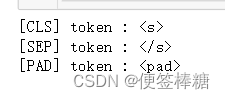
print('[CLS] token :', transformer_tokenizer.cls_token)
print('[SEP] token :', transformer_tokenizer.sep_token)
print('[PAD] token :', transformer_tokenizer.pad_token)
databunch.show_batch()

检查批次和数式:
print('[CLS] id :', transformer_tokenizer.cls_token_id)
print('[SEP] id :', transformer_tokenizer.sep_token_id)
print('[PAD] id :', pad_idx)
test_one_batch = databunch.one_batch()[0]
print('Batch shape : ',test_one_batch.shape)
print(test_one_batch)

6.1 定制模型
每个模型的前向方法总是输出具有各种元素的 a,具体取决于模型和配置参数。在例子中,只对访问 logit 感兴趣。 访问它们的一种方法是创建自定义模型
# defining our model architecture
class CustomTransformerModel(nn.Module):
def __init__(self, transformer_model: PreTrainedModel):
super(CustomTransformerModel,self).__init__()
self.transformer = transformer_model
def forward(self, input_ids, attention_mask=None):
# attention_mask
# Mask to avoid performing attention on padding token indices.
# Mask values selected in ``[0, 1]``:
# ``1`` for tokens that are NOT MASKED, ``0`` for MASKED tokens.
attention_mask = (input_ids!=pad_idx).type(input_ids.type())
logits = self.transformer(input_ids,
attention_mask = attention_mask)[0]
return logits
为了使变压器适应多类分类,在加载预训练模型之前,需要精确标签的数量。
为此,修改配置实例,或者修改num_labels参数。
config = config_class.from_pretrained(pretrained_model_name)
config.num_labels = 5
config.use_bfloat16 = use_fp16
print(config)

7. 自定义优化器/自定义指标
8. 判别性微调和渐进式解冻(可选)
我们可以决定将模型分为 14 个块:
1 嵌入
12 变换
1 个分类器
在这种情况下,可以这样拆分为此模型:
# For DistilBERT
# list_layers = [learner.model.transformer.distilbert.embeddings,
# learner.model.transformer.distilbert.transformer.layer[0],
# learner.model.transformer.distilbert.transformer.layer[1],
# learner.model.transformer.distilbert.transformer.layer[2],
# learner.model.transformer.distilbert.transformer.layer[3],
# learner.model.transformer.distilbert.transformer.layer[4],
# learner.model.transformer.distilbert.transformer.layer[5],
# learner.model.transformer.pre_classifier]
# For xlnet-base-cased
# list_layers = [learner.model.transformer.transformer.word_embedding,
# learner.model.transformer.transformer.layer[0],
# learner.model.transformer.transformer.layer[1],
# learner.model.transformer.transformer.layer[2],
# learner.model.transformer.transformer.layer[3],
# learner.model.transformer.transformer.layer[4],
# learner.model.transformer.transformer.layer[5],
# learner.model.transformer.transformer.layer[6],
# learner.model.transformer.transformer.layer[7],
# learner.model.transformer.transformer.layer[8],
# learner.model.transformer.transformer.layer[9],
# learner.model.transformer.transformer.layer[10],
# learner.model.transformer.transformer.layer[11],
# learner.model.transformer.sequence_summary]
# For roberta-base
list_layers = [learner.model.transformer.roberta.embeddings,
learner.model.transformer.roberta.encoder.layer[0],
learner.model.transformer.roberta.encoder.layer[1],
learner.model.transformer.roberta.encoder.layer[2],
learner.model.transformer.roberta.encoder.layer[3],
learner.model.transformer.roberta.encoder.layer[4],
learner.model.transformer.roberta.encoder.layer[5],
learner.model.transformer.roberta.encoder.layer[6],
learner.model.transformer.roberta.encoder.layer[7],
learner.model.transformer.roberta.encoder.layer[8],
learner.model.transformer.roberta.encoder.layer[9],
learner.model.transformer.roberta.encoder.layer[10],
learner.model.transformer.roberta.encoder.layer[11],
learner.model.transformer.roberta.pooler]
检查组 :
learner.split(list_layers)
num_groups = len(learner.layer_groups)
print('Learner split in',num_groups,'groups')
print(learner.layer_groups)

9. 训练
使用倾斜三角学习率、判别学习率并逐渐解冻模型。
learner.save('untrain')
seed_all(seed)
learner.load('untrain');
- 首先冻结除分类器之外的所有组:
learner.freeze_to(-1)
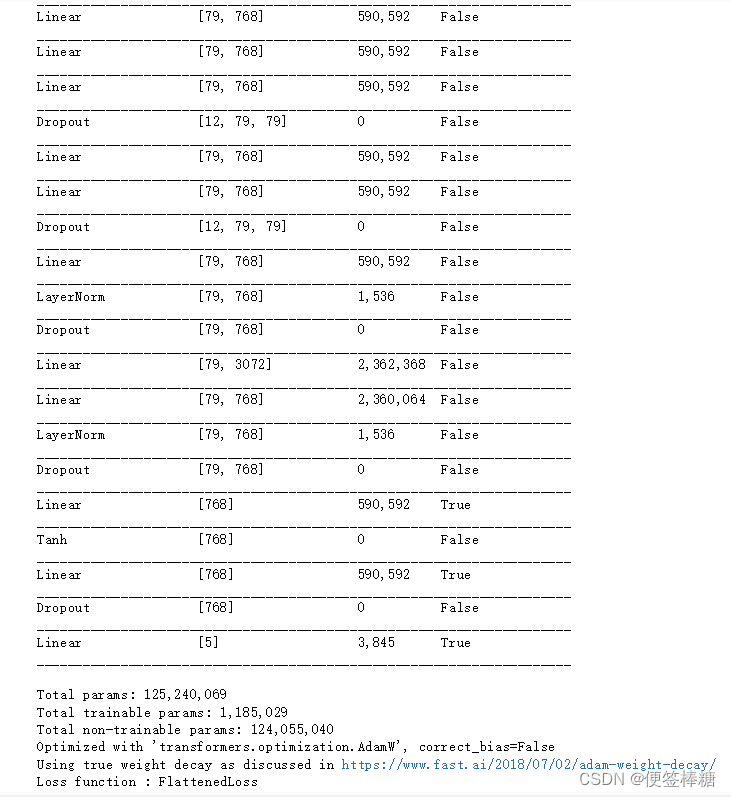
- 检查哪一层是可训练的:
learner.summary()
- 通过使用学习率查找器来找到这个学习率,该查找器可以通过使用 调用。one_cyclelr_find
learner.lr_find()

learner.recorder.plot(skip_end=10,suggestion=True)
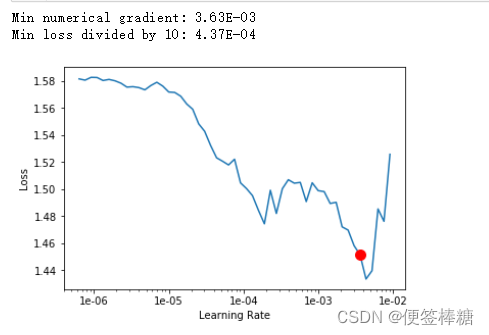
在最小值之前选择一个值,此时损失仍然会改善。2x10^-3 似乎是一个不错的值。
将使用所选的 fit_one_cycle 学习率作为最大学习率。
learner.fit_one_cycle(1,max_lr=2e-03,moms=(0.8,0.7))
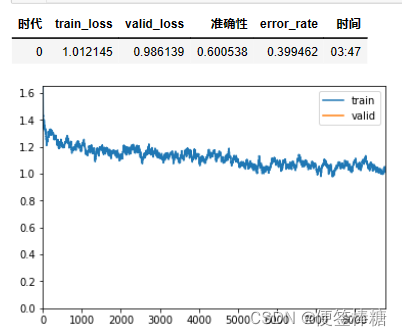
learner.save('first_cycle')
seed_all(seed)
learner.load('first_cycle');
- 然后,解冻第二组层并重复这些操作:
learner.freeze_to(-2)
lr = 1e-5
- 使用切片为每个组创建单独的学习率:
learner.fit_one_cycle(1, max_lr=slice(lr*0.95**num_groups, lr), moms=(0.8, 0.9))
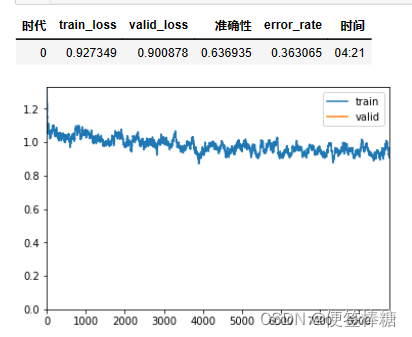
learner.save('second_cycle')
seed_all(seed)
learner.load('second_cycle');
learner.freeze_to(-3)
learner.fit_one_cycle(1, max_lr=slice(lr*0.95**num_groups, lr), moms=(0.8, 0.9))
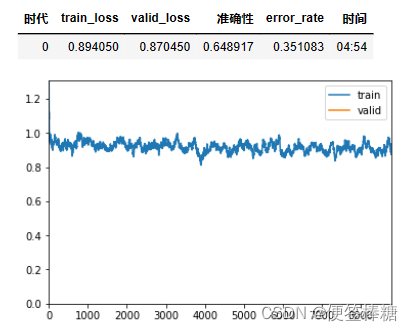
learner.save('third_cycle')
seed_all(seed)
learner.load('third_cycle');
- 解冻所有组:
learner.unfreeze()
learner.fit_one_cycle(2, max_lr=slice(lr*0.95**num_groups, lr), moms=(0.8, 0.9))
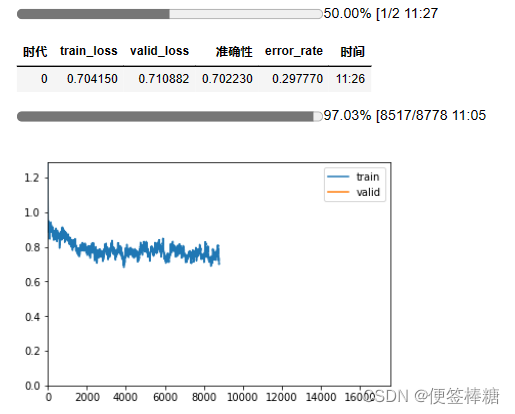
- 使用以下方法预测示例:
learner.predict('This is the best movie of 2020')

learner.predict('This is the worst movie of 2020')

10. 导出
learner.export(file = 'transformer.pkl');
path = '/kaggle/working'
export_learner = load_learner(path, file = 'transformer.pkl')
export_learner.predict('This is the worst movie of 2020')

(三)创建预测
训练模型后,目的为测试数据集生成预测
def get_preds_as_nparray(ds_type) -> np.ndarray:
"""
the get_preds method does not yield the elements in order by default
we borrow the code from the RNNLearner to resort the elements into their correct order
"""
preds = learner.get_preds(ds_type)[0].detach().cpu().numpy()
sampler = [i for i in databunch.dl(ds_type).sampler]
reverse_sampler = np.argsort(sampler)
return preds[reverse_sampler, :]
test_preds = get_preds_as_nparray(DatasetType.Test)
sample_submission = pd.read_csv(DATA_ROOT / 'sampleSubmission.csv')
sample_submission['Sentiment'] = np.argmax(test_preds,axis=1)
sample_submission.to_csv("predictions.csv", index=False)
检查:
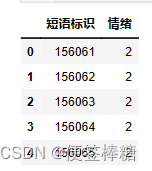
test.head()
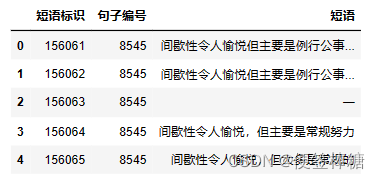
sample_submission.head()
from IPython.display import HTML
def create_download_link(title = "Download CSV file", filename = "data.csv"):
html = '<a href={filename}>{title}</a>'
html = html.format(title=title,filename=filename)
return HTML(html)
# create a link to download the dataframe which was saved with .to_csv method
create_download_link(filename='predictions.csv')
(四) 结论
使用倾斜三角学习率,判别学习率甚至逐渐解冻。因此,甚至无需调整参数,您就可以快速获得最先进的结果。transformersfastai
今年,变压器成为NLP的重要工具。正因为如此,我认为预先训练的变压器架构将很快集成到 fastai 的未来版本中。同时,本教程是一个很好的入门。














 2127
2127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









