







调度器源码解析
笔者刚开始学,有些地方理解错了请谅解。kubernetes版本为1.28.1
1. scheduler
首先是调度器的数据结构:
type Scheduler struct {
// ! podState nodeInfoListitem
Cache internalcache.Cache
Extenders []framework.Extender
NextPod func() (*framework.QueuedPodInfo, error)
FailureHandler FailureHandlerFn
SchedulePod func(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (ScheduleResult, error)
// Close this to shut down the scheduler.
StopEverything <-chan struct{}
// SchedulingQueue holds pods to be scheduled
// ! 调度队列 priorityQueue
SchedulingQueue internalqueue.SchedulingQueue
// Profiles are the scheduling profiles.
// ! 调度器配置
Profiles profile.Map
client clientset.Interface
nodeInfoSnapshot *internalcache.Snapshot
percentageOfNodesToScore int32
nextStartNodeIndex int
logger klog.Logger
registeredHandlers []cache.ResourceEventHandlerRegistration
}
调度器内部主要有以下数据结构:
- Cache: 保存了需调度的podState nodeInfoListitem信息
- SchedulingQueue:调度队列
- Profiles:调度器的配置,Map定义是
map[string]framework.Framework,Framework是调度框架。该Map用于映射scheduler名字到Framework
2. schedulingQueue
调度队列为interface,这里直接展示它的实现PriorityQueue:
type PriorityQueue struct {
*nominator // ! 记录调度结果,pod <-> node
stop chan struct{}
clock clock.Clock
// ! 轮询podBackoffQ和unschedulablePods的时间间隔
// pod initial backoff duration.
podInitialBackoffDuration time.Duration
// pod maximum backoff duration.
podMaxBackoffDuration time.Duration
// the maximum time a pod can stay in the unschedulablePods.
podMaxInUnschedulablePodsDuration time.Duration
cond sync.Cond
inFlightPods map[types.UID]inFlightPod
receivedEvents *list.List
// activeQ is heap structure that scheduler actively looks at to find pods to
// schedule. Head of heap is the highest priority pod.
// ! heap是一个内部为map的队列
activeQ *heap.Heap
// podBackoffQ is a heap ordered by backoff expiry. Pods which have completed backoff
// are popped from this heap before the scheduler looks at activeQ
podBackoffQ *heap.Heap
// unschedulablePods holds pods that have been tried and determined unschedulable.
// ! 内部是一个map
unschedulablePods *UnschedulablePods
// schedulingCycle represents sequence number of scheduling cycle and is incremented
// when a pod is popped.
schedulingCycle int64
moveRequestCycle int64
// preEnqueuePluginMap is keyed with profile name, valued with registered preEnqueue plugins.
preEnqueuePluginMap map[string][]framework.PreEnqueuePlugin
// queueingHintMap is keyed with profile name, valued with registered queueing hint functions.
queueingHintMap QueueingHintMapPerProfile
// closed indicates that the queue is closed.
// It is mainly used to let Pop() exit its control loop while waiting for an item.
closed bool
nsLister listersv1.NamespaceLister
metricsRecorder metrics.MetricAsyncRecorder
// pluginMetricsSamplePercent is the percentage of plugin metrics to be sampled.
pluginMetricsSamplePercent int
// isSchedulingQueueHintEnabled indicates whether the feature gate for the scheduling queue is enabled.
isSchedulingQueueHintEnabled bool
}
主要的包含的数据结构有:
- nominator:记录pod与node的调度结果
- stop chan: 调度队列关闭的通知管道
- clock:计时工具,用于flush时判断pod是否可出队(后面会讲)
- podInitialBackoffDuration、podMaxBackoffDuration、podMaxInUnschedulablePodsDuration:均是flush时判断pod是否可出队的时间标准
- activeQ:heap类型(内部为map+slice)。储存可以被调度的pod
- podBackoffQ:heap类型(内部为map+slice)。储存处于backoff状态的pod
- unschedulablePods:map+slice,储存不可被调度的pod
- schedulingCycle:当某个pod从PriorityQueue中pop后,cycle+1
- preEnqueuePluginMap
- queueingHintMap
这里用到的heap是data的封装,而data是标准的heap实现:
import "container/heap"
type Heap struct {
data *data
metricRecorder metrics.MetricRecorder
}
// !Heap也封装了add,update,delete,pop,push,peek等函数,都是对data的对应函数的封装
type KeyFunc func(obj interface{}) (string, error)
type heapItem struct {
obj interface{} // The object which is stored in the heap.
index int // The index of the object's key in the Heap.queue.
}
type itemKeyValue struct {
key string
obj interface{}
}
// data is an internal struct that implements the standard heap interface
// and keeps the data stored in the heap.
type data struct {
// items is a map from key of the objects to the objects and their index.
// We depend on the property that items in the map are in the queue and vice versa.
items map[string]*heapItem
// queue implements a heap data structure and keeps the order of elements
// according to the heap invariant. The queue keeps the keys of objects stored
// in "items".
queue []string
// keyFunc is used to make the key used for queued item insertion and retrieval, and
// should be deterministic.
keyFunc KeyFunc
// lessFunc is used to compare two objects in the heap.
lessFunc lessFunc
}
func (h *data) Less(i, j int) bool
func (h *data) Len() int
func (h *data) Push(kv interface{})
func (h *data) Swap(i, j int)
func (h *data) Pop() interface{}
func (h *data) Peek() interface{}
普通的heap实现只需要一个slice,然后分别实现heap interface的几个函数即可。这里data中还有一个map,实际上就是heap只作用于itemkeyvalue.key,排序啥的也只对key起作用,而map用来存储heapItem(由itemkeyvalue.obj和slice中该item的index组成的数据结构)。
可能有些绕,这里梳理一下添加一个pod到PriorityQueue的过程,这个要从addAllEventHandlers说起,这个函数在pkg/scheduler/eventHandlers.go内,作用应该类似于事件触发处理,把所有资源对象发生的事件与其处理函数绑定。对于添加pod到activeQ队列的事件,对应的handler是scheduler.addPodToSchedulingQueue,看一下这个函数:
func (sched *Scheduler) addPodToSchedulingQueue(obj interface{}) {
logger := sched.logger
pod := obj.(*v1.Pod)
logger.V(3).Info("Add event for unscheduled pod", "pod", klog.KObj(pod))
if err := sched.SchedulingQueue.Add(logger, pod); err != nil {
utilruntime.HandleError(fmt.Errorf("unable to queue %T: %v", obj, err))
}
}
很明显调用了sched.SchedulingQueue.Add,并且传入了v1.Pod对象。再看Add函数:
// Add adds a pod to the active queue. It should be called only when a new pod
// is added so there is no chance the pod is already in active/unschedulable/backoff queues
func (p *PriorityQueue) Add(logger klog.Logger, pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
pInfo := p.newQueuedPodInfo(pod) // ! 根据v1.pod构造一个QueuedPodInfo数据结构并返回
gated := pInfo.Gated
if added, err := p.addToActiveQ(logger, pInfo); !added {
return err
}
if p.unschedulablePods.get(pod) != nil {
logger.Error(nil, "Error: pod is already in the unschedulable queue", "pod", klog.KObj(pod))
p.unschedulablePods.delete(pod, gated)
}
// Delete pod from backoffQ if it is backing off
if err := p.podBackoffQ.Delete(pInfo); err == nil {
logger.Error(nil, "Error: pod is already in the podBackoff queue", "pod", klog.KObj(pod))
}
logger.V(5).Info("Pod moved to an internal scheduling queue", "pod", klog.KObj(pod), "event", PodAdd, "queue", activeQ)
metrics.SchedulerQueueIncomingPods.WithLabelValues("active", PodAdd).Inc()
p.addNominatedPodUnlocked(logger, pInfo.PodInfo, nil)
p.cond.Broadcast()
return nil
}
牵扯出两个数据结构,分别是QueuedPodInfo和PodInfo,前者用于表示放入PriorityQueue的Pod(是后者的封装,并带有一些时间、尝试次数等成员变量),后者是v1.Pod的封装:
// QueuedPodInfo is a Pod wrapper with additional information related to
// the pod's status in the scheduling queue, such as the timestamp when
// it's added to the queue.
type QueuedPodInfo struct {
*PodInfo
// The time pod added to the scheduling queue.
Timestamp time.Time
// Number of schedule attempts before successfully scheduled.
// It's used to record the # attempts metric.
Attempts int
// The time when the pod is added to the queue for the first time. The pod may be added
// back to the queue multiple times before it's successfully scheduled.
// It shouldn't be updated once initialized. It's used to record the e2e scheduling
// latency for a pod.
InitialAttemptTimestamp *time.Time
// If a Pod failed in a scheduling cycle, record the plugin names it failed by.
UnschedulablePlugins sets.Set[string]
// Whether the Pod is scheduling gated (by PreEnqueuePlugins) or not.
// ! 不是很懂
Gated bool
}
type PodInfo struct {
Pod *v1.Pod
RequiredAffinityTerms []AffinityTerm
RequiredAntiAffinityTerms []AffinityTerm
PreferredAffinityTerms []WeightedAffinityTerm
PreferredAntiAffinityTerms []WeightedAffinityTerm
}
再回到Add函数,官方注释里说了这个函数只有在创建了一个新pod时才会被调用,所以在调用完PriorityQueue.addToActiveQ后需要再判断一下该pod是否在另两个队列中。继续深入,查看addToActiveQ:
// addToActiveQ tries to add pod to active queue. It returns 2 parameters:
// 1. a boolean flag to indicate whether the pod is added successfully.
// 2. an error for the caller to act on.
func (p *PriorityQueue) addToActiveQ(logger klog.Logger, pInfo *framework.QueuedPodInfo) (bool, error) {
pInfo.Gated = !p.runPreEnqueuePlugins(context.Background(), pInfo)
if pInfo.Gated {
// Add the Pod to unschedulablePods if it's not passing PreEnqueuePlugins.
p.unschedulablePods.addOrUpdate(pInfo)
return false, nil
}
// !初始化开始尝试调度时间
if pInfo.InitialAttemptTimestamp == nil {
now := p.clock.Now()
pInfo.InitialAttemptTimestamp = &now
}
// ! 加入activeQ
if err := p.activeQ.Add(pInfo); err != nil {
logger.Error(err, "Error adding pod to the active queue", "pod", klog.KObj(pInfo.Pod))
return false, err
}
return true, nil
}
又开始的每个pod都会被加入到ActiveQ,所以这里调用PriorityQueue.activeQ.Add,即heap的Add成员函数,这里传入的参数是该pod的QueuedPodInfo:
// Add inserts an item, and puts it in the queue. The item is updated if it
// already exists.
func (h *Heap) Add(obj interface{}) error {
// 查找该pod信息对应的key
key, err := h.data.keyFunc(obj)
if err != nil {
return cache.KeyError{Obj: obj, Err: err}
}
if _, exists := h.data.items[key]; exists {
h.data.items[key].obj = obj
heap.Fix(h.data, h.data.items[key].index)
} else {
heap.Push(h.data, &itemKeyValue{key, obj})
if h.metricRecorder != nil {
h.metricRecorder.Inc()
}
}
return nil
}
这里首先h.data.keyFunc就有的说了,用于获取待加入heap的obj的key,盲猜是namespace+name,首先找到调度队列heap初始化的代码,发现使用的KeyFunc是podInfoKeyFunc,继续往下看:
// ! KeyFunc: 用于heap获取QueuedPodInfo的key
func podInfoKeyFunc(obj interface{}) (string, error) {
return cache.MetaNamespaceKeyFunc(obj.(*framework.QueuedPodInfo).Pod) // ! 传入*v1.pod
}
func MetaNamespaceKeyFunc(obj interface{}) (string, error) {
if key, ok := obj.(ExplicitKey); ok {
return string(key), nil
}
objName, err := ObjectToName(obj)
if err != nil {
return "", err
}
return objName.String(), nil
}
// ObjectToName returns the structured name for the given object,
// if indeed it can be viewed as a metav1.Object.
func ObjectToName(obj interface{}) (ObjectName, error) {
meta, err := meta.Accessor(obj)
if err != nil {
return ObjectName{}, fmt.Errorf("object has no meta: %v", err)
}
return MetaObjectToName(meta), nil
}
// MetaObjectToName returns the structured name for the given object
func MetaObjectToName(obj metav1.Object) ObjectName {
if len(obj.GetNamespace()) > 0 {
return ObjectName{Namespace: obj.GetNamespace(), Name: obj.GetName()}
}
return ObjectName{Namespace: "", Name: obj.GetName()}
}
// vendor/k8s.io/apimachinery/api/meta/meta.go vendor文件夹里存放第三方库的代码
// Accessor takes an arbitrary object pointer and returns meta.Interface.
// obj must be a pointer to an API type. An error is returned if the minimum
// required fields are missing. Fields that are not required return the default
// value and are a no-op if set.
func Accessor(obj interface{}) (metav1.Object, error) {
switch t := obj.(type) {
case metav1.Object:
return t, nil
case metav1.ObjectMetaAccessor:
if m := t.GetObjectMeta(); m != nil {
return m, nil
}
return nil, errNotObject
default:
return nil, errNotObject
}
}
总之Accessor()能判断obj的类型并返回obj,如果是metav1.Object则直接返回。pod属于metav1.Object,然后调用MetaObjectToName,返回该obj的命名空间和名字。
绕了一大圈再回到heap.Add,通过KeyFunc获取了obj的key(ns+name),然后如果已经有这个key就更新,如果没有就加入。再介绍下LessFunc,调用的是framework里的queueSortPlugins插件:(framework我还不是很懂)
// QueueSortFunc returns the function to sort pods in scheduling queue
func (f *frameworkImpl) QueueSortFunc() framework.LessFunc {
if f == nil {
// If frameworkImpl is nil, simply keep their order unchanged.
// NOTE: this is primarily for tests.
return func(_, _ *framework.QueuedPodInfo) bool { return false }
}
if len(f.queueSortPlugins) == 0 {
panic("No QueueSort plugin is registered in the frameworkImpl.")
}
// Only one QueueSort plugin can be enabled.
return f.queueSortPlugins[0].Less
}
// Less is the function used by the activeQ heap algorithm to sort pods.
// It sorts pods based on their priority. When priorities are equal, it uses
// PodQueueInfo.timestamp.
func (pl *PrioritySort) Less(pInfo1, pInfo2 *framework.QueuedPodInfo) bool {
p1 := corev1helpers.PodPriority(pInfo1.Pod)
p2 := corev1helpers.PodPriority(pInfo2.Pod)
return (p1 > p2) || (p1 == p2 && pInfo1.Timestamp.Before(pInfo2.Timestamp))
}
func PodPriority(pod *v1.Pod) int32 {
if pod.Spec.Priority != nil {
return *pod.Spec.Priority
}
// When priority of a running pod is nil, it means it was created at a time
// that there was no global default priority class and the priority class
// name of the pod was empty. So, we resolve to the static default priority.
return 0
}
这样一整个添加pod的过程就结束了。
3. scheduler 初始化过程
3.1 config
启动一个调度器应用在源码中有一个config结构,该结构包括了运行调度器所需的调度器配置,客户端配置等等,总之是root配置,定义如下:
// Config has all the context to run a Scheduler
type Config struct {
// ComponentConfig is the scheduler server's configuration object.
ComponentConfig kubeschedulerconfig.KubeSchedulerConfiguration
// ! 调度器应用配置 KubeSchedulerConfiguration:{HealthzBindAddress, MetricsBindAddress, KubeSchedulerProfile[], Extender[]} 整个sheduler实例的配置
// ! 调度器配置 KubeSchedulerProfile:{SchedulerName, *Plugins, PluginConfig[]} 单个scheduler的配置文件,pod和node都可以通过绑定SchedulerName来运行某个特定的scheduler
// ! Plugins: 由多个pluginset组成,每个pluginset都是一个扩展点
// ! pluginset: {enabled[], disabled[]},表示某个扩展点使用哪些插件,不使用哪个扩展点
// ! PluginConfig: 每个plugin都对应一个pluginConfig
// LoopbackClientConfig is a config for a privileged loopback connection
LoopbackClientConfig *restclient.Config
Authentication apiserver.AuthenticationInfo
Authorization apiserver.AuthorizationInfo
SecureServing *apiserver.SecureServingInfo
Client clientset.Interface
KubeConfig *restclient.Config
InformerFactory informers.SharedInformerFactory
DynInformerFactory dynamicinformer.DynamicSharedInformerFactory
//nolint:staticcheck // SA1019 this deprecated field still needs to be used for now. It will be removed once the migration is done.
EventBroadcaster events.EventBroadcasterAdapter
// LeaderElection is optional.
LeaderElection *leaderelection.LeaderElectionConfig
// PodMaxInUnschedulablePodsDuration is the maximum time a pod can stay in
// unschedulablePods. If a pod stays in unschedulablePods for longer than this
// value, the pod will be moved from unschedulablePods to backoffQ or activeQ.
// If this value is empty, the default value (5min) will be used.
PodMaxInUnschedulablePodsDuration time.Duration
}
3.2 KubeSchedulerConfiguration与KubeSchedulerProfile
然后KubeSchedulerConfiguration是调度器应用配置。
这里要首先说明调度策略和调度器应用的区别。调度器应用是一整个k8s服务,它可以包含多个调度策略,需要的初始化参数如下:
type KubeSchedulerConfiguration struct {
// TypeMeta contains the API version and kind. In kube-scheduler, after
// conversion from the versioned KubeSchedulerConfiguration type to this
// internal type, we set the APIVersion field to the scheme group/version of
// the type we converted from. This is done in cmd/kube-scheduler in two
// places: (1) when loading config from a file, (2) generating the default
// config. Based on the versioned type set in this field, we make decisions;
// for example (1) during validation to check for usage of removed plugins,
// (2) writing config to a file, (3) initialising the scheduler.
metav1.TypeMeta // ! API version and kind
// Parallelism defines the amount of parallelism in algorithms for scheduling a Pods. Must be greater than 0. Defaults to 16
Parallelism int32
// LeaderElection defines the configuration of leader election client.
LeaderElection componentbaseconfig.LeaderElectionConfiguration
// ClientConnection specifies the kubeconfig file and client connection
// settings for the proxy server to use when communicating with the apiserver.
ClientConnection componentbaseconfig.ClientConnectionConfiguration
// HealthzBindAddress is the IP address and port for the health check server to serve on.
HealthzBindAddress string
// MetricsBindAddress is the IP address and port for the metrics server to serve on.
MetricsBindAddress string
// DebuggingConfiguration holds configuration for Debugging related features
// TODO: We might wanna make this a substruct like Debugging componentbaseconfig.DebuggingConfiguration
componentbaseconfig.DebuggingConfiguration
// PercentageOfNodesToScore is the percentage of all nodes that once found feasible
// for running a pod, the scheduler stops its search for more feasible nodes in
// the cluster. This helps improve scheduler's performance. Scheduler always tries to find
// at least "minFeasibleNodesToFind" feasible nodes no matter what the value of this flag is.
// Example: if the cluster size is 500 nodes and the value of this flag is 30,
// then scheduler stops finding further feasible nodes once it finds 150 feasible ones.
// When the value is 0, default percentage (5%--50% based on the size of the cluster) of the
// nodes will be scored. It is overridden by profile level PercentageOfNodesToScore.
PercentageOfNodesToScore *int32
// PodInitialBackoffSeconds is the initial backoff for unschedulable pods.
// If specified, it must be greater than 0. If this value is null, the default value (1s)
// will be used.
PodInitialBackoffSeconds int64
// PodMaxBackoffSeconds is the max backoff for unschedulable pods.
// If specified, it must be greater than or equal to podInitialBackoffSeconds. If this value is null,
// the default value (10s) will be used.
PodMaxBackoffSeconds int64
// Profiles are scheduling profiles that kube-scheduler supports. Pods can
// choose to be scheduled under a particular profile by setting its associated
// scheduler name. Pods that don't specify any scheduler name are scheduled
// with the "default-scheduler" profile, if present here.
Profiles []KubeSchedulerProfile
// Extenders are the list of scheduler extenders, each holding the values of how to communicate
// with the extender. These extenders are shared by all scheduler profiles.
Extenders []Extender
// DelayCacheUntilActive specifies when to start caching. If this is true and leader election is enabled,
// the scheduler will wait to fill informer caches until it is the leader. Doing so will have slower
// failover with the benefit of lower memory overhead while waiting to become leader.
// Defaults to false.
DelayCacheUntilActive bool
}
而调度器应用内可以有多个调度策略,这个调度策略所需的参数如下:
// KubeSchedulerProfile is a scheduling profile.
type KubeSchedulerProfile struct {
// SchedulerName is the name of the scheduler associated to this profile.
// If SchedulerName matches with the pod's "spec.schedulerName", then the pod
// is scheduled with this profile.
SchedulerName string
// PercentageOfNodesToScore is the percentage of all nodes that once found feasible
// for running a pod, the scheduler stops its search for more feasible nodes in
// the cluster. This helps improve scheduler's performance. Scheduler always tries to find
// at least "minFeasibleNodesToFind" feasible nodes no matter what the value of this flag is.
// Example: if the cluster size is 500 nodes and the value of this flag is 30,
// then scheduler stops finding further feasible nodes once it finds 150 feasible ones.
// When the value is 0, default percentage (5%--50% based on the size of the cluster) of the
// nodes will be scored. It will override global PercentageOfNodesToScore. If it is empty,
// global PercentageOfNodesToScore will be used.
PercentageOfNodesToScore *int32
// Plugins specify the set of plugins that should be enabled or disabled.
// Enabled plugins are the ones that should be enabled in addition to the
// default plugins. Disabled plugins are any of the default plugins that
// should be disabled.
// When no enabled or disabled plugin is specified for an extension point,
// default plugins for that extension point will be used if there is any.
// If a QueueSort plugin is specified, the same QueueSort Plugin and
// PluginConfig must be specified for all profiles.
Plugins *Plugins
// PluginConfig is an optional set of custom plugin arguments for each plugin.
// Omitting config args for a plugin is equivalent to using the default config
// for that plugin.
PluginConfig []PluginConfig
}
3.3 NewSchedulerCommand
接下来正式进入调度器服务启动过程:
cmd/kube-scheduler/scheduler.go,启动kube-scheduler命令
func main() {
command := app.NewSchedulerCommand()
code := cli.Run(command)
os.Exit(code)
}
NewSchedulerCommand()只看两个选项NewOptions,registryOptions(形参,一串Option函数)和一个函数和runcommand:
func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
opts := options.NewOptions()
cmd := &cobra.Command{
Use: "kube-scheduler",
Long: `The Kubernetes scheduler is a control plane process which assigns
Pods to Nodes. The scheduler determines which Nodes are valid placements for
each Pod in the scheduling queue according to constraints and available
resources. The scheduler then ranks each valid Node and binds the Pod to a
suitable Node. Multiple different schedulers may be used within a cluster;
kube-scheduler is the reference implementation.
See [scheduling](https://kubernetes.io/docs/concepts/scheduling-eviction/)
for more information about scheduling and the kube-scheduler component.`,
RunE: func(cmd *cobra.Command, args []string) error {
return runCommand(cmd, opts, registryOptions...) // ! 传入创建scheduler所需的
},
Args: func(cmd *cobra.Command, args []string) error {
for _, arg := range args {
if len(arg) > 0 {
return fmt.Errorf("%q does not take any arguments, got %q", cmd.CommandPath(), args)
}
}
return nil
},
}
nfs := opts.Flags
verflag.AddFlags(nfs.FlagSet("global"))
globalflag.AddGlobalFlags(nfs.FlagSet("global"), cmd.Name(), logs.SkipLoggingConfigurationFlags())
fs := cmd.Flags()
for _, f := range nfs.FlagSets {
fs.AddFlagSet(f)
}
cols, _, _ := term.TerminalSize(cmd.OutOrStdout())
cliflag.SetUsageAndHelpFunc(cmd, *nfs, cols)
if err := cmd.MarkFlagFilename("config", "yaml", "yml", "json"); err != nil {
klog.Background().Error(err, "Failed to mark flag filename")
}
return cmd
}
NewOptions创建一个Options对象(用于初始化最开始讲的config)
// ! Options所有参数都与config对象的参数对应
type Options struct {
// The default values.
ComponentConfig *kubeschedulerconfig.KubeSchedulerConfiguration
SecureServing *apiserveroptions.SecureServingOptionsWithLoopback
Authentication *apiserveroptions.DelegatingAuthenticationOptions
Authorization *apiserveroptions.DelegatingAuthorizationOptions
Metrics *metrics.Options
Logs *logs.Options
Deprecated *DeprecatedOptions
LeaderElection *componentbaseconfig.LeaderElectionConfiguration
// ConfigFile is the location of the scheduler server's configuration file.
ConfigFile string
// WriteConfigTo is the path where the default configuration will be written.
WriteConfigTo string
Master string
// Flags hold the parsed CLI flags.
Flags *cliflag.NamedFlagSets
}
func NewOptions() *Options {
o := &Options{
SecureServing: apiserveroptions.NewSecureServingOptions().WithLoopback(),
Authentication: apiserveroptions.NewDelegatingAuthenticationOptions(),
Authorization: apiserveroptions.NewDelegatingAuthorizationOptions(),
Deprecated: &DeprecatedOptions{
PodMaxInUnschedulablePodsDuration: 5 * time.Minute,
},
LeaderElection: &componentbaseconfig.LeaderElectionConfiguration{
LeaderElect: true,
LeaseDuration: metav1.Duration{Duration: 15 * time.Second},
RenewDeadline: metav1.Duration{Duration: 10 * time.Second},
RetryPeriod: metav1.Duration{Duration: 2 * time.Second},
ResourceLock: "leases",
ResourceName: "kube-scheduler",
ResourceNamespace: "kube-system",
},
Metrics: metrics.NewOptions(),
Logs: logs.NewOptions(),
}
o.Authentication.TolerateInClusterLookupFailure = true
o.Authentication.RemoteKubeConfigFileOptional = true
o.Authorization.RemoteKubeConfigFileOptional = true
// Set the PairName but leave certificate directory blank to generate in-memory by default
o.SecureServing.ServerCert.CertDirectory = ""
o.SecureServing.ServerCert.PairName = "kube-scheduler"
o.SecureServing.BindPort = kubeschedulerconfig.DefaultKubeSchedulerPort
o.initFlags()
return o
}
形参registryOptions是Server.go中定义的函数类型type Option func(runtime.Registry) error,该类函数用于注册插件到插件工厂。后面涉及到的所有xxx.Option性质都是一样的,都是一种可以添加到函数参数列表中的函数参数,提供一种可选配置的方式创建某些对象。例如下面这个withPlugin:
// WithPlugin creates an Option based on plugin name and factory. Please don't remove this function: it is used to register out-of-tree plugins,
// hence there are no references to it from the kubernetes scheduler code base.
func WithPlugin(name string, factory runtime.PluginFactory) Option {
return func(registry runtime.Registry) error {
return registry.Register(name, factory)
}
}
有了上面的Options,registeroption,就可以调用runCommand了。
// runCommand runs the scheduler.
func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option) error {
verflag.PrintAndExitIfRequested()
// Activate logging as soon as possible, after that
// show flags with the final logging configuration.
if err := logsapi.ValidateAndApply(opts.Logs, utilfeature.DefaultFeatureGate); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
cliflag.PrintFlags(cmd.Flags())
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
go func() {
stopCh := server.SetupSignalHandler()
<-stopCh
cancel()
}()
// ! 读取配置文件 初始化调度器
cc, sched, err := Setup(ctx, opts, registryOptions...)
if err != nil {
return err
}
// add feature enablement metrics
utilfeature.DefaultMutableFeatureGate.AddMetrics()
return Run(ctx, cc, sched)
}
runCommand函数需关注Setup和Run,分别是调度器初始化和调度器启动的入口。本节将探究Setup入口
3.4 Setup
目前只看了Setup中新建scheduler的部分。新建scheduler需调用scheduler.New,New为scheduler的创建函数:
func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
if cfg, err := latest.Default(); err != nil {
return nil, nil, err
} else {
opts.ComponentConfig = cfg
}
if errs := opts.Validate(); len(errs) > 0 {
return nil, nil, utilerrors.NewAggregate(errs)
}
// ! 用Options初始化config
c, err := opts.Config(ctx)
if err != nil {
return nil, nil, err
}
// Get the completed config
cc := c.Complete()
outOfTreeRegistry := make(runtime.Registry)
for _, option := range outOfTreeRegistryOptions {
if err := option(outOfTreeRegistry); err != nil {
return nil, nil, err
}
}
recorderFactory := getRecorderFactory(&cc)
completedProfiles := make([]kubeschedulerconfig.KubeSchedulerProfile, 0)
// Create the scheduler.
sched, err := scheduler.New(ctx,
cc.Client,
cc.InformerFactory,
cc.DynInformerFactory,
recorderFactory,
scheduler.WithComponentConfigVersion(cc.ComponentConfig.TypeMeta.APIVersion),
scheduler.WithKubeConfig(cc.KubeConfig),
scheduler.WithProfiles(cc.ComponentConfig.Profiles...),
scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
scheduler.WithPodMaxInUnschedulablePodsDuration(cc.PodMaxInUnschedulablePodsDuration),
scheduler.WithExtenders(cc.ComponentConfig.Extenders...),
scheduler.WithParallelism(cc.ComponentConfig.Parallelism),
scheduler.WithBuildFrameworkCapturer(func(profile kubeschedulerconfig.KubeSchedulerProfile) {
// Profiles are processed during Framework instantiation to set default plugins and configurations. Capturing them for logging
completedProfiles = append(completedProfiles, profile)
}),
)
if err != nil {
return nil, nil, err
}
if err := options.LogOrWriteConfig(klog.FromContext(ctx), opts.WriteConfigTo, &cc.ComponentConfig, completedProfiles); err != nil {
return nil, nil, err
}
return &cc, sched, nil
}
// New returns a Scheduler
func New(ctx context.Context,
client clientset.Interface,
informerFactory informers.SharedInformerFactory,
dynInformerFactory dynamicinformer.DynamicSharedInformerFactory,
recorderFactory profile.RecorderFactory,
opts ...Option) (*Scheduler, error) {
logger := klog.FromContext(ctx)
stopEverything := ctx.Done()
options := defaultSchedulerOptions
for _, opt := range opts {
opt(&options)
}
if options.applyDefaultProfile {
var versionedCfg configv1.KubeSchedulerConfiguration
scheme.Scheme.Default(&versionedCfg)
cfg := schedulerapi.KubeSchedulerConfiguration{}
if err := scheme.Scheme.Convert(&versionedCfg, &cfg, nil); err != nil {
return nil, err
}
options.profiles = cfg.Profiles
}
// ! 创建插件注册工厂
registry := frameworkplugins.NewInTreeRegistry()
if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {
return nil, err
}
metrics.Register()
extenders, err := buildExtenders(logger, options.extenders, options.profiles)
if err != nil {
return nil, fmt.Errorf("couldn't build extenders: %w", err)
}
podLister := informerFactory.Core().V1().Pods().Lister()
nodeLister := informerFactory.Core().V1().Nodes().Lister()
snapshot := internalcache.NewEmptySnapshot()
metricsRecorder := metrics.NewMetricsAsyncRecorder(1000, time.Second, stopEverything)
profiles, err := profile.NewMap(ctx, options.profiles, registry, recorderFactory,
frameworkruntime.WithComponentConfigVersion(options.componentConfigVersion),
frameworkruntime.WithClientSet(client),
frameworkruntime.WithKubeConfig(options.kubeConfig),
frameworkruntime.WithInformerFactory(informerFactory),
frameworkruntime.WithSnapshotSharedLister(snapshot),
frameworkruntime.WithCaptureProfile(frameworkruntime.CaptureProfile(options.frameworkCapturer)),
frameworkruntime.WithParallelism(int(options.parallelism)),
frameworkruntime.WithExtenders(extenders),
frameworkruntime.WithMetricsRecorder(metricsRecorder),
)
if err != nil {
return nil, fmt.Errorf("initializing profiles: %v", err)
}
if len(profiles) == 0 {
return nil, errors.New("at least one profile is required")
}
preEnqueuePluginMap := make(map[string][]framework.PreEnqueuePlugin)
queueingHintsPerProfile := make(internalqueue.QueueingHintMapPerProfile)
for profileName, profile := range profiles {
preEnqueuePluginMap[profileName] = profile.PreEnqueuePlugins()
queueingHintsPerProfile[profileName] = buildQueueingHintMap(profile.EnqueueExtensions())
}
// ! 创建调度队列
podQueue := internalqueue.NewSchedulingQueue(
profiles[options.profiles[0].SchedulerName].QueueSortFunc(), // ! heap的优先级less函数
informerFactory,
internalqueue.WithPodInitialBackoffDuration(time.Duration(options.podInitialBackoffSeconds)*time.Second),
internalqueue.WithPodMaxBackoffDuration(time.Duration(options.podMaxBackoffSeconds)*time.Second),
internalqueue.WithPodLister(podLister),
internalqueue.WithPodMaxInUnschedulablePodsDuration(options.podMaxInUnschedulablePodsDuration),
internalqueue.WithPreEnqueuePluginMap(preEnqueuePluginMap),
internalqueue.WithQueueingHintMapPerProfile(queueingHintsPerProfile),
internalqueue.WithPluginMetricsSamplePercent(pluginMetricsSamplePercent),
internalqueue.WithMetricsRecorder(*metricsRecorder),
)
for _, fwk := range profiles {
fwk.SetPodNominator(podQueue)
}
schedulerCache := internalcache.New(ctx, durationToExpireAssumedPod)
// Setup cache debugger.
debugger := cachedebugger.New(nodeLister, podLister, schedulerCache, podQueue)
debugger.ListenForSignal(ctx)
sched := &Scheduler{
Cache: schedulerCache,
client: client,
nodeInfoSnapshot: snapshot,
percentageOfNodesToScore: options.percentageOfNodesToScore,
Extenders: extenders,
StopEverything: stopEverything,
SchedulingQueue: podQueue,
Profiles: profiles,
logger: logger,
}
sched.NextPod = podQueue.Pop
sched.applyDefaultHandlers()
// ! 开启所有资源对象的事件监听
if err = addAllEventHandlers(sched, informerFactory, dynInformerFactory, unionedGVKs(queueingHintsPerProfile)); err != nil {
return nil, fmt.Errorf("adding event handlers: %w", err)
}
return sched, nil
}
ctx部分笔者还没看过,先跳过。New函数主要干了三件事:
- 创建插件注册工厂
NewInTreeRegistry - 创建extenders、podLister、nodeLister、snapshot、metricsRecorder、scheduleCache(还没看)
- 创建初始化scheduler需要的profiles
NewMap - 创建调度队列
NewSchedulingQueue(前一节已经介绍) - 开启所有事件监听
addAllEventHandlers(还没看)
3.4.1 NewInTreeRegistry 创建插件注册工厂
// NewInTreeRegistry builds the registry with all the in-tree plugins.
// A scheduler that runs out of tree plugins can register additional plugins
// through the WithFrameworkOutOfTreeRegistry option.
func NewInTreeRegistry() runtime.Registry {
fts := plfeature.Features{
EnableDynamicResourceAllocation: feature.DefaultFeatureGate.Enabled(features.DynamicResourceAllocation),
EnableReadWriteOncePod: feature.DefaultFeatureGate.Enabled(features.ReadWriteOncePod),
EnableVolumeCapacityPriority: feature.DefaultFeatureGate.Enabled(features.VolumeCapacityPriority),
EnableMinDomainsInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.MinDomainsInPodTopologySpread),
EnableNodeInclusionPolicyInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.NodeInclusionPolicyInPodTopologySpread),
EnableMatchLabelKeysInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.MatchLabelKeysInPodTopologySpread),
EnablePodSchedulingReadiness: feature.DefaultFeatureGate.Enabled(features.PodSchedulingReadiness),
EnablePodDisruptionConditions: feature.DefaultFeatureGate.Enabled(features.PodDisruptionConditions),
EnableInPlacePodVerticalScaling: feature.DefaultFeatureGate.Enabled(features.InPlacePodVerticalScaling),
EnableSidecarContainers: feature.DefaultFeatureGate.Enabled(features.SidecarContainers),
}
registry := runtime.Registry{
dynamicresources.Name: runtime.FactoryAdapter(fts, dynamicresources.New),
selectorspread.Name: selectorspread.New,
imagelocality.Name: imagelocality.New,
tainttoleration.Name: tainttoleration.New,
nodename.Name: nodename.New,
nodeports.Name: nodeports.New,
nodeaffinity.Name: nodeaffinity.New,
podtopologyspread.Name: runtime.FactoryAdapter(fts, podtopologyspread.New),
nodeunschedulable.Name: nodeunschedulable.New,
noderesources.Name: runtime.FactoryAdapter(fts, noderesources.NewFit),
noderesources.BalancedAllocationName: runtime.FactoryAdapter(fts, noderesources.NewBalancedAllocation),
volumebinding.Name: runtime.FactoryAdapter(fts, volumebinding.New),
volumerestrictions.Name: runtime.FactoryAdapter(fts, volumerestrictions.New),
volumezone.Name: volumezone.New,
nodevolumelimits.CSIName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCSI),
nodevolumelimits.EBSName: runtime.FactoryAdapter(fts, nodevolumelimits.NewEBS),
nodevolumelimits.GCEPDName: runtime.FactoryAdapter(fts, nodevolumelimits.NewGCEPD),
nodevolumelimits.AzureDiskName: runtime.FactoryAdapter(fts, nodevolumelimits.NewAzureDisk),
nodevolumelimits.CinderName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCinder),
interpodaffinity.Name: interpodaffinity.New,
queuesort.Name: queuesort.New,
defaultbinder.Name: defaultbinder.New,
defaultpreemption.Name: runtime.FactoryAdapter(fts, defaultpreemption.New),
schedulinggates.Name: runtime.FactoryAdapter(fts, schedulinggates.New),
}
return registry
}
type Registry map[string]PluginFactory
type PluginFactory = func(configuration runtime.Object, f framework.Handle) (framework.Plugin, error)
插件注册工厂实际就是一个map,用于映射插件名到插件创建接口PluginFactory ,每个插件都有自己的PluginFactory 。官方注释里说明了如果要注册out-tree plugin, 可以通过在Setup创建scheduler时使用WithFrameworkOutOfTreeRegistry传入新添的plugins(回溯到kube-schdeuler的入口main,newSchedulerCommand(registryOptions))。
func WithFrameworkOutOfTreeRegistry(registry frameworkruntime.Registry) Option {
return func(o *schedulerOptions) {
o.frameworkOutOfTreeRegistry = registry
}
}
3.4.2 创建profiles NewMap【创建framework】
Newmap针对KubeSchedulerProfile数组利用newProfile创建多个调度策略的framework资源对象,返回map[string]framework.Framework。RecorderFactory目前还没看懂是啥。
// newProfile builds a Profile for the given configuration.
func newProfile(ctx context.Context, cfg config.KubeSchedulerProfile, r frameworkruntime.Registry, recorderFact RecorderFactory,
opts ...frameworkruntime.Option) (framework.Framework, error) {
recorder := recorderFact(cfg.SchedulerName)
opts = append(opts, frameworkruntime.WithEventRecorder(recorder))
return frameworkruntime.NewFramework(ctx, r, &cfg, opts...)
}
// Map holds frameworks indexed by scheduler name.
type Map map[string]framework.Framework
// NewMap builds the frameworks given by the configuration, indexed by name.
func NewMap(ctx context.Context, cfgs []config.KubeSchedulerProfile, r frameworkruntime.Registry, recorderFact RecorderFactory,
opts ...frameworkruntime.Option) (Map, error) {
m := make(Map)
v := cfgValidator{m: m}
for _, cfg := range cfgs {
p, err := newProfile(ctx, cfg, r, recorderFact, opts...)
if err != nil {
return nil, fmt.Errorf("creating profile for scheduler name %s: %v", cfg.SchedulerName, err)
}
if err := v.validate(cfg, p); err != nil {
return nil, err
}
m[cfg.SchedulerName] = p
}
return m, nil
}
newProfile调用了NewFramework,这个函数是理解framework的关键。
3.4.3 创建schedulingQueue
3.4 4 开启所有事件监听addAllEventHandlers
4. Framework
4.1 创建framework
这部分代码很关键,注释写的比较详细,理解了话就基本上对scheduler framework和extensionPoint就会有一个理解。
frameworkImpl是framework接口的实现。NewFramework函数主要就是创建frameworkImpl的过程。frameworkImpl的结构包括插件注册工厂Registry、每种类型的插件实现列表、每个打分插件的权重slicesorcePluginWeight:
type frameworkImpl struct {
registry Registry
snapshotSharedLister framework.SharedLister
waitingPods *waitingPodsMap
scorePluginWeight map[string]int
preEnqueuePlugins []framework.PreEnqueuePlugin
enqueueExtensions []framework.EnqueueExtensions
queueSortPlugins []framework.QueueSortPlugin
preFilterPlugins []framework.PreFilterPlugin
filterPlugins []framework.FilterPlugin
postFilterPlugins []framework.PostFilterPlugin
preScorePlugins []framework.PreScorePlugin
scorePlugins []framework.ScorePlugin
reservePlugins []framework.ReservePlugin
preBindPlugins []framework.PreBindPlugin
bindPlugins []framework.BindPlugin
postBindPlugins []framework.PostBindPlugin
permitPlugins []framework.PermitPlugin
clientSet clientset.Interface
kubeConfig *restclient.Config
eventRecorder events.EventRecorder
informerFactory informers.SharedInformerFactory
logger klog.Logger
metricsRecorder *metrics.MetricAsyncRecorder
profileName string
percentageOfNodesToScore *int32
extenders []framework.Extender
framework.PodNominator
parallelizer parallelize.Parallelizer
}
这里每种插件列表都是有严格接口定义的,比如framework.ScorePlugin的接口定义如下。
// ScorePlugin is an interface that must be implemented by "Score" plugins to rank
// nodes that passed the filtering phase.
type ScorePlugin interface {
Plugin
// Score is called on each filtered node. It must return success and an integer
// indicating the rank of the node. All scoring plugins must return success or
// the pod will be rejected.
Score(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) (int64, *Status)
// ScoreExtensions returns a ScoreExtensions interface if it implements one, or nil if does not.
ScoreExtensions() ScoreExtensions
}
可以想象初始化时fwk的插件列表是没有这些插件的,所以在NewFramework中肯定会有把KubeSchedulerProfile中的插件plugin绑定到fwk的插件实现列表的操作,并且KubeSchedulerProfile中的插件plugin资源对象只是定义了插件名和插件创建所需的参数,那么很自然就想到Registry中存储的pluginFactory插件创建函数。这样,其实newframework的核心逻辑就已经想透了。其他的部分就是一些边边角角的处理了。
// NewFramework initializes plugins given the configuration and the registry.
func NewFramework(ctx context.Context, r Registry, profile *config.KubeSchedulerProfile, opts ...Option) (framework.Framework, error) {
options := defaultFrameworkOptions(ctx.Done())
for _, opt := range opts {
opt(&options)
}
logger := klog.FromContext(ctx)
if options.logger != nil {
logger = *options.logger
}
// ! 1.1 初始化framework(不需要profile部分,由Option提供的部分,即可选的配置)
f := &frameworkImpl{
registry: r,
snapshotSharedLister: options.snapshotSharedLister,
scorePluginWeight: make(map[string]int),
waitingPods: newWaitingPodsMap(),
clientSet: options.clientSet,
kubeConfig: options.kubeConfig,
eventRecorder: options.eventRecorder,
informerFactory: options.informerFactory,
metricsRecorder: options.metricsRecorder,
extenders: options.extenders,
PodNominator: options.podNominator,
parallelizer: options.parallelizer,
logger: logger,
}
if profile == nil {
return f, nil
}
// ! 1.2 初始化framework(profile部分)
f.profileName = profile.SchedulerName
f.percentageOfNodesToScore = profile.PercentageOfNodesToScore
if profile.Plugins == nil {
return f, nil
}
// get needed plugins from config
// ! 2.1 从配置中获取enabled plugin
// ? config.KubeSchedulerProfile中的插件组定义Plugins
// ? 每个Plugins内有多个PluginSet,每个PluginSet由两个数组组成,分别储存enabled Plugin和Disabled Plugin(name+weight)
// ? pg为一个map[string]emtpy,存储所有enabled plugin的name(即代表fwk里有多少插件需要被调用)
pg := f.pluginsNeeded(profile.Plugins)
// ! 2.2 从配置中获取每个插件初始化所需参数
pluginConfig := make(map[string]runtime.Object, len(profile.PluginConfig))
for i := range profile.PluginConfig {
name := profile.PluginConfig[i].Name
if _, ok := pluginConfig[name]; ok {
return nil, fmt.Errorf("repeated config for plugin %s", name)
}
pluginConfig[name] = profile.PluginConfig[i].Args
}
outputProfile := config.KubeSchedulerProfile{
SchedulerName: f.profileName,
PercentageOfNodesToScore: f.percentageOfNodesToScore,
Plugins: profile.Plugins,
PluginConfig: make([]config.PluginConfig, 0, len(pg)),
}
// ! 2.3 创建enabled plugin
pluginsMap := make(map[string]framework.Plugin)
for name, factory := range r { // ? name:Plugin name ; factory:创建插件的函数,会调用handle
// initialize only needed plugins.
if !pg.Has(name) { // ! 说明该插件在配置文件中是unabled plugin
continue
}
args := pluginConfig[name] // ! name 插件所需参数
if args != nil {
outputProfile.PluginConfig = append(outputProfile.PluginConfig, config.PluginConfig{
Name: name,
Args: args,
})
}
p, err := factory(args, f) // ! 创建插件 这里返回的framework.Plugin是一个interface
if err != nil {
return nil, fmt.Errorf("initializing plugin %q: %w", name, err)
}
pluginsMap[name] = p
f.fillEnqueueExtensions(p)
}
// ! 2.4 把enabled plugin分配到fwk的各类型插件slice中去
// initialize plugins per individual extension points
for _, e := range f.getExtensionPoints(profile.Plugins) {
// ? e.slicePtr: fwk内每个扩展点(插件slice)的指针
// ? *e.plugins: fwk内每个扩展点的PluginSet
// ? pluginsMap: 所有扩展点内的插件名与已创建的插件的映射
// ! 遍历fwk数据结构里每一种类型的插件slice和通过getExtensionPoints绑定的PluginSet
// ? 把每种类型里符合要求的plugin都添加到fwk中该类型的plugin slice里
if err := updatePluginList(e.slicePtr, *e.plugins, pluginsMap); err != nil {
return nil, err
}
}
// ! 2.5
// initialize multiPoint plugins to their expanded extension points
if len(profile.Plugins.MultiPoint.Enabled) > 0 {
if err := f.expandMultiPointPlugins(logger, profile, pluginsMap); err != nil {
return nil, err
}
}
// ! queueSortPlugins和bindPlugins是必须要有的插件
if len(f.queueSortPlugins) != 1 {
return nil, fmt.Errorf("only one queue sort plugin required for profile with scheduler name %q, but got %d", profile.SchedulerName, len(f.queueSortPlugins))
}
if len(f.bindPlugins) == 0 {
return nil, fmt.Errorf("at least one bind plugin is needed for profile with scheduler name %q", profile.SchedulerName)
}
if err := getScoreWeights(f, pluginsMap, append(profile.Plugins.Score.Enabled, profile.Plugins.MultiPoint.Enabled...)); err != nil {
return nil, err
}
// Verifying the score weights again since Plugin.Name() could return a different
// value from the one used in the configuration.
// ! 判断scorePlugins的权重是否为0;因为该插件权重不能为0
for _, scorePlugin := range f.scorePlugins {
if f.scorePluginWeight[scorePlugin.Name()] == 0 {
return nil, fmt.Errorf("score plugin %q is not configured with weight", scorePlugin.Name())
}
}
// ! 如果调用者需要捕获KubeSchedulerProfile,则将KubeSchedulerProfile回调给调用者
if options.captureProfile != nil {
if len(outputProfile.PluginConfig) != 0 {
sort.Slice(outputProfile.PluginConfig, func(i, j int) bool {
return outputProfile.PluginConfig[i].Name < outputProfile.PluginConfig[j].Name
})
} else {
outputProfile.PluginConfig = nil
}
options.captureProfile(outputProfile)
}
f.setInstrumentedPlugins()
return f, nil
}
其中涉及到的几个函数:
pluginsNeeded:从plugins中获取每个xxxpluginSet中enabled plugin的plugin name,按顺序放入set(没有val的map)中getExtensionPoints:返回扩展点数组,扩展点extensionPoint是包括某一类插件的插件定义和插件实现指针的数据结构。该函数把处于KubeSchedulerProfile中的plugins.xxxpluginSet与fwk中的插件列表地址绑定
type extensionPoint struct {
// the set of plugins to be configured at this extension point.
plugins *config.PluginSet
// a pointer to the slice storing plugins implementations that will run at this
// extension point.
slicePtr interface{}
}
func (f *frameworkImpl) getExtensionPoints(plugins *config.Plugins) []extensionPoint {
// ! &(plugins.PreFilter)
return []extensionPoint{
{&plugins.PreFilter, &f.preFilterPlugins},
{&plugins.Filter, &f.filterPlugins},
{&plugins.PostFilter, &f.postFilterPlugins},
{&plugins.Reserve, &f.reservePlugins},
{&plugins.PreScore, &f.preScorePlugins},
{&plugins.Score, &f.scorePlugins},
{&plugins.PreBind, &f.preBindPlugins},
{&plugins.Bind, &f.bindPlugins},
{&plugins.PostBind, &f.postBindPlugins},
{&plugins.Permit, &f.permitPlugins},
{&plugins.PreEnqueue, &f.preEnqueuePlugins},
{&plugins.QueueSort, &f.queueSortPlugins},
}
}
updatePluginList(很重要):用于把插件的实现放入到fwk的插件实现列表,这样fwk就可以调用扩展点内的插件了。要用到reflect反射来获取每种插件的类型和插件实现。对反射不熟悉可以看reflect基础。
// ! 判断配置文件中指定的enable plugin是否被创建;
// ! 如果是,判断该plugin实例是否是fwk中声明的插件类型;
// ! 如果是,则该插件符合条件,需被调用
// ? 把插件实现放入fwK的插件列表
func updatePluginList(pluginList interface{}, pluginSet config.PluginSet, pluginsMap map[string]framework.Plugin) error {
// ! 反射reflect
// ! 这里pluginList为什么要用接口类型?因为可能传入不同插件类型,只能定义为interface,然后用反射获取其值类型
// ? reflect.ValueOf(interface{}):获取接口变量的值
// ? reflect.TypeOf(interface{}):获取接口变量的类型
plugins := reflect.ValueOf(pluginList).Elem() // ! 获取某类插件列表指针
pluginType := plugins.Type().Elem() // ! 获取某类插件列表指针的类型
set := sets.New[string]()
for _, ep := range pluginSet.Enabled {
// ! 判断该插件是否已经创建
pg, ok := pluginsMap[ep.Name]
if !ok {
return fmt.Errorf("%s %q does not exist", pluginType.Name(), ep.Name)
}
// ! 判断之前创建的插件类型是不是pluginType
if !reflect.TypeOf(pg).Implements(pluginType) {
return fmt.Errorf("plugin %q does not extend %s plugin", ep.Name, pluginType.Name())
}
if set.Has(ep.Name) {
return fmt.Errorf("plugin %q already registered as %q", ep.Name, pluginType.Name())
}
set.Insert(ep.Name)
newPlugins := reflect.Append(plugins, reflect.ValueOf(pg)) // * 通过反射把reflect.ValueOf(pg)添加到切片plugins上
plugins.Set(newPlugins) // ? 通过反射赋值下一个插件列表地址
}
return nil
}
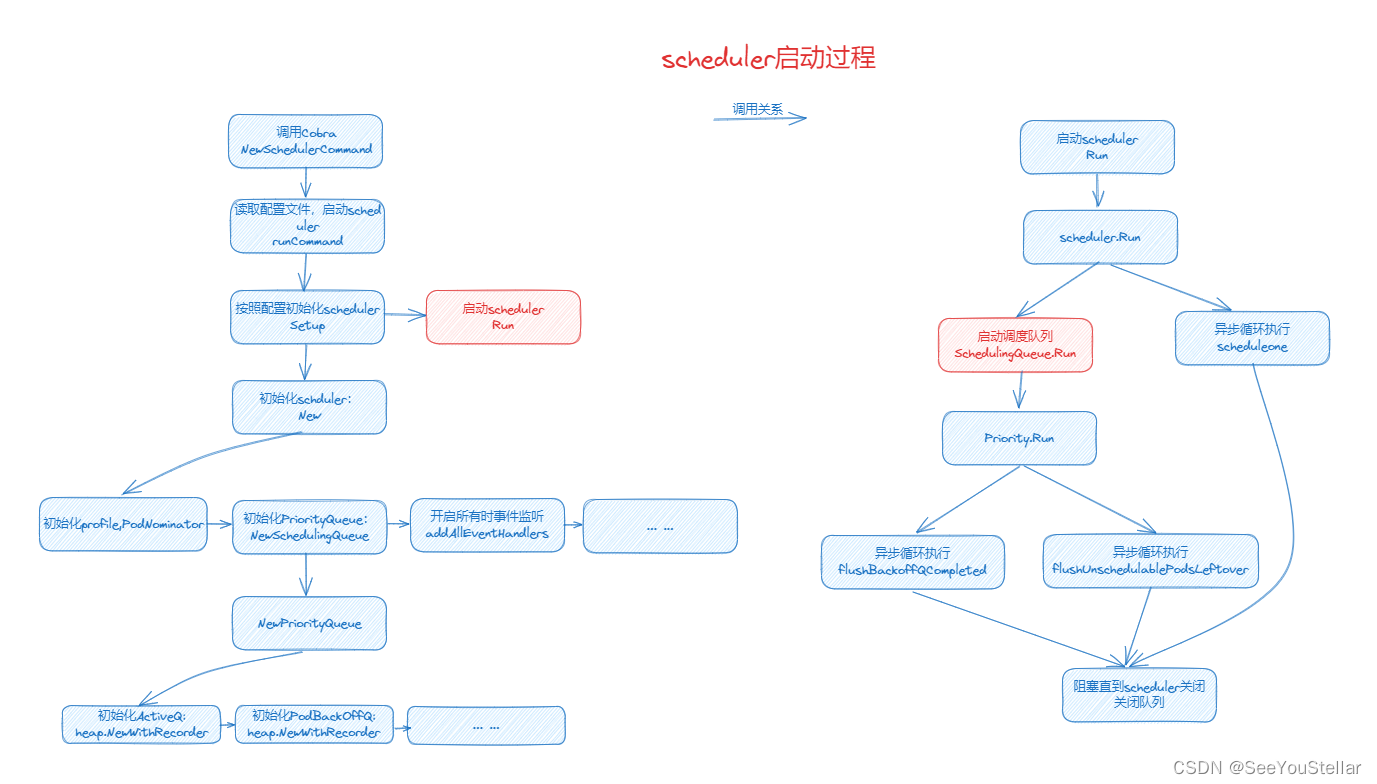
5. scheduler 启动过程
5.1 scheduler.Run
// Run begins watching and scheduling. It starts scheduling and blocked until the context is done.
func (sched *Scheduler) Run(ctx context.Context) {
logger := klog.FromContext(ctx)
// ! 启动调度队列
sched.SchedulingQueue.Run(logger)
// We need to start scheduleOne loop in a dedicated goroutine,
// because scheduleOne function hangs on getting the next item
// from the SchedulingQueue.
// If there are no new pods to schedule, it will be hanging there
// and if done in this goroutine it will be blocking closing
// SchedulingQueue, in effect causing a deadlock on shutdown.
// ! UntilWithContext函数循环执行schedule函数
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
// ! 阻塞接收
<-ctx.Done()
sched.SchedulingQueue.Close()
}
首先启动调度队列,UntilWithContext函数用于异步循环执行(按一定间隔),这里循环执行scheduler.scheduleone,先不管这个函数干了什么,后面就是阻塞直到接收到关闭信号,将调度队列关闭。
5.2 scheduler.SchedulingQueue.Run
// Run starts the goroutine to pump from podBackoffQ to activeQ
func (p *PriorityQueue) Run(logger klog.Logger) {
// ? p.stop关闭时停止
// ! 1s执行一次backoffQ队列的flush
go wait.Until(func() {
p.flushBackoffQCompleted(logger)
}, 1.0*time.Second, p.stop)
// ! 1s执行一次unschedulablePods队列的flush
go wait.Until(func() {
p.flushUnschedulablePodsLeftover(logger)
}, 30*time.Second, p.stop)
}
异步循环执行flushBackoffQCompleted和flushUnschedulablePodsLeftover函数,默认前者时间间隔为1s,后者时间间隔为30s
// flushBackoffQCompleted Moves all pods from backoffQ which have completed backoff in to activeQ
func (p *PriorityQueue) flushBackoffQCompleted(logger klog.Logger) {
// ! 执行一次flush,最多出队一个pod
p.lock.Lock()
defer p.lock.Unlock()
activated := false
for {
rawPodInfo := p.podBackoffQ.Peek()
if rawPodInfo == nil {
break
}
// ! 断言
pInfo := rawPodInfo.(*framework.QueuedPodInfo)
pod := pInfo.Pod
// ! 判断是否可出队
if p.isPodBackingoff(pInfo) {
break
}
_, err := p.podBackoffQ.Pop()
if err != nil {
logger.Error(err, "Unable to pop pod from backoff queue despite backoff completion", "pod", klog.KObj(pod))
break
}
if added, _ := p.addToActiveQ(logger, pInfo); added {
logger.V(5).Info("Pod moved to an internal scheduling queue", "pod", klog.KObj(pod), "event", BackoffComplete, "queue", activeQ)
metrics.SchedulerQueueIncomingPods.WithLabelValues("active", BackoffComplete).Inc()
activated = true
}
}
if activated {
p.cond.Broadcast()
}
}
// flushUnschedulablePodsLeftover moves pods which stay in unschedulablePods
// longer than podMaxInUnschedulablePodsDuration to backoffQ or activeQ.
func (p *PriorityQueue) flushUnschedulablePodsLeftover(logger klog.Logger) {
// ! 执行一次flush,可出队多个pod
p.lock.Lock()
defer p.lock.Unlock()
var podsToMove []*framework.QueuedPodInfo
currentTime := p.clock.Now()
for _, pInfo := range p.unschedulablePods.podInfoMap {
lastScheduleTime := pInfo.Timestamp
if currentTime.Sub(lastScheduleTime) > p.podMaxInUnschedulablePodsDuration {
podsToMove = append(podsToMove, pInfo)
}
}
if len(podsToMove) > 0 {
p.movePodsToActiveOrBackoffQueue(logger, podsToMove, UnschedulableTimeout, nil, nil)
}
}
这两个函数注释说的很明白了,就不解释了。注意每次从backoffQ出队最多只能有1个,而从unschedulable队列可以出队多个。涉及到最开始在scheduler中定义的几个时间间隔。
5.3 scheduler.scheduleone
// scheduleOne does the entire scheduling workflow for a single pod. It is serialized on the scheduling algorithm's host fitting.
func (sched *Scheduler) scheduleOne(ctx context.Context) {
logger := klog.FromContext(ctx)
podInfo, err := sched.NextPod() // 初始化时定义:sched.NextPod = podQueue.Pop
if err != nil {
logger.Error(err, "Error while retrieving next pod from scheduling queue")
return
}
// pod could be nil when schedulerQueue is closed
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
logger.V(4).Info("About to try and schedule pod", "pod", klog.KObj(pod))
fwk, err := sched.frameworkForPod(pod)
if err != nil {
// This shouldn't happen, because we only accept for scheduling the pods
// which specify a scheduler name that matches one of the profiles.
logger.Error(err, "Error occurred")
return
}
if sched.skipPodSchedule(ctx, fwk, pod) {
return
}
logger.V(3).Info("Attempting to schedule pod", "pod", klog.KObj(pod))
// Synchronously attempt to find a fit for the pod.
start := time.Now()
state := framework.NewCycleState()
state.SetRecordPluginMetrics(rand.Intn(100) < pluginMetricsSamplePercent)
// Initialize an empty podsToActivate struct, which will be filled up by plugins or stay empty.
podsToActivate := framework.NewPodsToActivate()
state.Write(framework.PodsToActivateKey, podsToActivate)
schedulingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
scheduleResult, assumedPodInfo, status := sched.schedulingCycle(schedulingCycleCtx, state, fwk, podInfo, start, podsToActivate)
if !status.IsSuccess() {
sched.FailureHandler(schedulingCycleCtx, fwk, assumedPodInfo, status, scheduleResult.nominatingInfo, start)
return
}
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
go func() {
bindingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
metrics.Goroutines.WithLabelValues(metrics.Binding).Inc()
defer metrics.Goroutines.WithLabelValues(metrics.Binding).Dec()
status := sched.bindingCycle(bindingCycleCtx, state, fwk, scheduleResult, assumedPodInfo, start, podsToActivate)
if !status.IsSuccess() {
sched.handleBindingCycleError(bindingCycleCtx, state, fwk, assumedPodInfo, start, scheduleResult, status)
return
}
// Usually, DonePod is called inside the scheduling queue,
// but in this case, we need to call it here because this Pod won't go back to the scheduling queue.
sched.SchedulingQueue.Done(assumedPodInfo.Pod.UID)
}()
}















 6005
6005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









