







背景:
在“ Transcribing DNA into RNA”中,我们讨论了DNA转录为RNA,在" “Translating RNA into Protein"中,我们研究了 将RNA翻译成氨基酸链以构建蛋白质。 我们可以将这两个过程视为一个步骤,我们直接翻译 将DNA串变成蛋白质串,因此需要DNA密码子表。
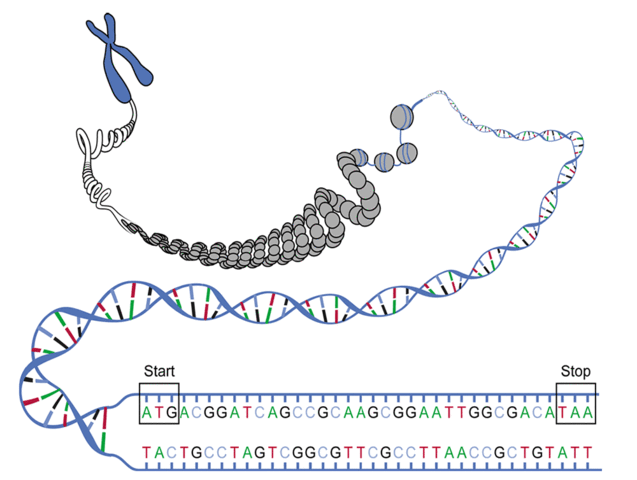
然而,当我们试图直接从 DNA到蛋白质。首先,并非所有DNA都会转录成RNA: 所谓的垃圾DNA似乎对细胞功能没有实际用途。 其次,我们可以在沿RNA链的任何位置开始翻译, 这意味着DNA链的任何子链都可以作为翻译的模板, 只要它以起始密码子开头,以终止密码子结束, 并且中间没有其他终止密码子。参见图1。 因此,相同的RNA链实际上可以用三种不同的方式翻译, 取决于我们如何将符号的三元组分组为密码子。比如...AUGCUGAC... 可以被阅读为...AUGCUG...,或 ...UGCUGA...或...GCUGAC...;两条链都可以作为模板链,因此还需要得到原序列的反向互补序列,以同样的思路得到另外三种阅读方式。
https://rosalind.info/problems/orf/
问题:
给出一串不超过1kbp的DNA序列。
返回每个不同的候选蛋白质链。 字符串可以按任意顺序返回。
示例:
Input:
>Rosalind_99 AGCCATGTAGCTAACTCAGGTTACATGGGGATGACCCCGCGACTTGGATTAGAGTCTCTTTTGGAATAAGCCTGAATGATCCGAGTAGCATCTCAG
output:
MLLGSFRLIPKETLIQVAGSSPCNLS M MGMTPRLGLESLLE MTPRLGLESLLE
代码:
import re
from method import fasta
name_list,value_list = fasta('文件所在位置')
dna = value_list[0]
"""
dna = 'AGCCATGTAGCTAACTCAGGTTACATGGGGATGACCCCGCGACTTGGATTAGAGTCTCTTTTGGAATAAGCCTGAATGATCCGAGTAGCATCTCAG'
"""
dna_codon_table = {
"TTT":"F", "CTT":"L", "ATT":"I", "GTT":"V",
"TTC":"F", "CTC":"L", "ATC":"I", "GTC":"V",
"TTA":"L", "CTA":"L", "ATA":"I", "GTA":"V",
"TTG":"L", "CTG":"L", "ATG":"M", "GTG":"V",
"TCT":"S", "CCT":"P", "ACT":"T", "GCT":"A",
"TCC":"S", "CCC":"P", "ACC":"T", "GCC":"A",
"TCA":"S", "CCA":"P", "ACA":"T", "GCA":"A",
"TCG":"S", "CCG":"P", "ACG":"T", "GCG":"A",
"TAT":"Y", "CAT":"H", "AAT":"N", "GAT":"D",
"TAC":"Y", "CAC":"H", "AAC":"N", "GAC":"D",
"TAA":"STOP", "CAA":"Q", "AAA":"K", "GAA":"E",
"TAG":"STOP", "CAG":"Q", "AAG":"K", "GAG":"E",
"TGT":"C", "CGT":"R", "AGT":"S", "GGT":"G",
"TGC":"C", "CGC":"R", "AGC":"S", "GGC":"G",
"TGA":"STOP", "CGA":"R", "AGA":"R", "GGA":"G",
"TGG":"W", "CGG":"R", "AGG":"R", "GGG":"G"
} #DNA密码子表
com = { "A" : "T", "T" : "A", "C" : "G", "G" : "C"}
Reversed_dna = ''
for i in dna[::-1]:
Reversed_dna+=com[i] #得到DNA的反向互补序列
windows = re.compile(r'(?=(ATG(?:...)*?)(?=TAA|TAG|TGA))') #重视正则表达式的学习
seq = []
for i in re.findall(windows, dna): #将符合要求的DNA序列加入列表
if i not in seq:
seq.append(i)
for i in re.findall(windows,Reversed_dna): #将符合要求的DNA反向互补序列加入列表
if i not in seq:
seq.append(i)
for i in seq: #将符合要求的序列翻译成蛋白质序列
res = ''
for j in range(0, len(i) - 2, 3):
res += dna_codon_table[i[j:j + 3]]
print(res)
















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}