







DataFrame、Dataset 的起源与演变
DataFrame 在 Spark 1.3 被引入,它的出现取代了 SchemaRDD,Dataset 最开始在 Spark 1.6 被引入,当时还属于实验性质,在 2.0 版本时正式成为 Spark 的一部分,并且在 Spark 2.0 中,DataFrame API 与 Dataset API 在形式上得到了统一。
Dataset API 提供了类型安全的面向对象编程接口。Dataset 可以通过将表达式和数据字段暴露给查询计划程序和 Tungsten 的快速内存编码,从而利用 Catalyst 优化器。但是,现在 DataFrame 和 Dataset 都作为 Apache Spark 2.0 的一部分,其实 DataFrame 现在是 Dataset Untyped API 的特殊情况。更具体地说:
DataFrame = Dataset[Row]
下面这张图比较清楚地表示了 DataFrame 与 Dataset 的变迁与关系。
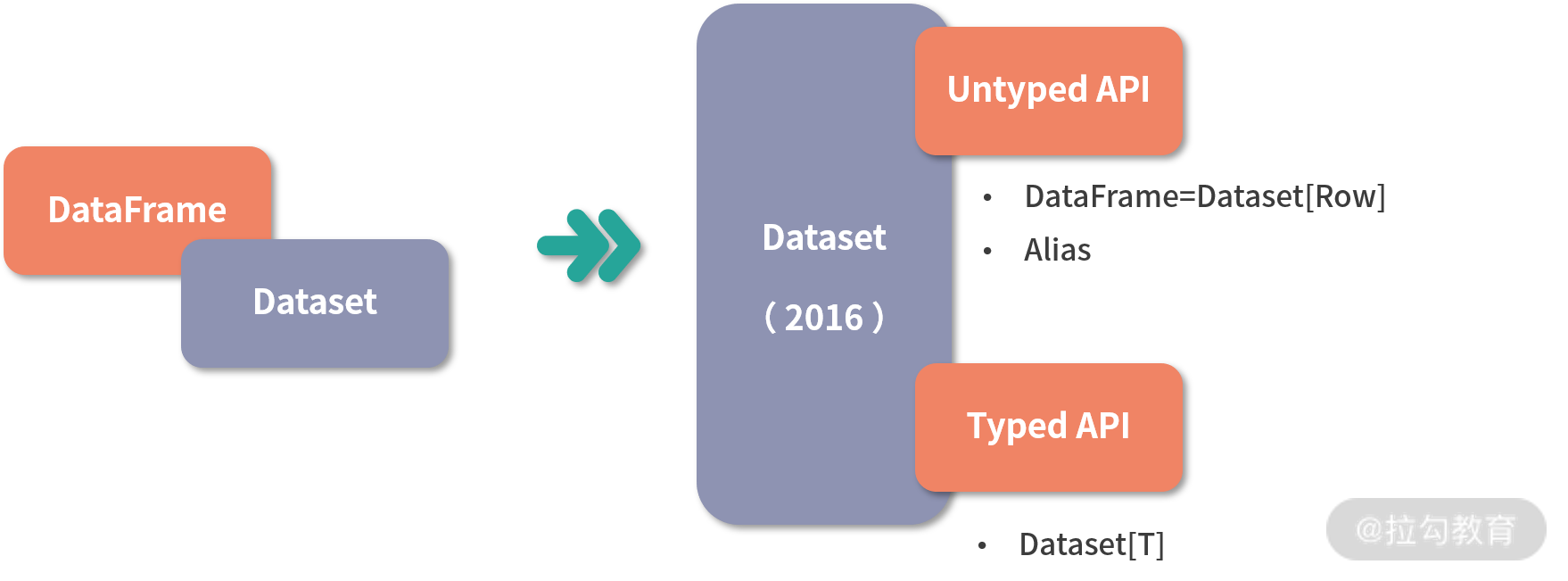
由于 Python 不是类型安全的语言,所以 Spark Python API 没有 Dataset API,而只提供了 DataFrame API。当然,Java 和 Scala 就没有这种问题。
DataFrame API
DataFrame 与 Dataset API 提供了简单的、统一的并且更富表达力的 API ,简言之,与 RDD 与算子的组合相比,DataFrame 与 Dataset API 更加高级,所以这也是为什么我将这个模块命名为 Spark 高级编程。
DataFrame 不仅可以使用 SQL 进行查询,其自身也具有灵活的 API 可以对数据进行查询,与 RDD API 相比,DataFrame API 包含了更多的应用语义,所谓应用语义,就是能让计算框架知道你的目标的信息,这样计算框架就能更有针对性地对作业进行优化,本课时主要介绍如何创建DataFrame 以及如何利用 DataFrame 进行查询。
1、创建DataFrame
DataFrame 目前支持多种数据源、文件格式,如 Json、CSV 等,也支持由外部数据库直接读取数据生成,此外还支持由 RDD 通过类型反射生成,甚至还可以通过流式数据源生成,这在下个模块会详细介绍。DataFrame API 非常标准,创建 DataFrame 都通过 read 读取器进行读取。下面列举了如何读取几种常见格式的文件。
-
读取 Json 文件。Json 文件如下:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
......
val df = spark.read.json("examples/src/main/resources/people.json")
我们可以利用初始化好的 SparkSession(spark)读取 Json 格式文件。
-
读取 CSV 文件:
val df = spark.read.csv("examples/src/main/resources/people.csv")
-
从 Parquet 格式文件中生成:
val df = spark.read.parquet("examples/src/main/resources/people.csv")
-
从 ORC 格式文件中生成:
val df = spark.read.orc("examples/src/main/resources/people.csv")
关于 ORC 与 Parquet 文件格式会在后面详细介绍。
-
从文本中生成:
val df = spark.read.text("examples/src/main/resources/people.csv")
-
通过 JDBC 连接外部数据库读取数据生成
val df = spark.read
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.load()
上面的代码表示通过 JDBC 相关配置,读取数据。
-
通过 RDD 反射生成。此种方法是字符串反射为 DataFrame 的 Schema,再和已经存在的 RDD 一起生成 DataFrame,代码如下所示:
import spark.implicits._
val schemaString = "id f1 f2 f3 f4"
// 通过字符串转换和类型反射生成schema
val fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)
// 需要将RDD转化为RDD[Row]类型
val rowRDD = spark.sparkContext.textFile(textFilePath).map(_.split(",")).map(attributes =>
Row(attributes(0),
attributes(1),
attributes(2),
attributes(3),
attributes(4).trim)
)
// 生成DataFrame
val df = spark.createDataFrame(rowRDD, schema)
注意这种方式需要隐式转换,需在转换前写上第一行:
import spark.implicits._
DataFrame 初始化完成后,可以通过 show 方法来查看数据,Json、Parquet、ORC 等数据源是自带 Schema 的,而那些无 Schema 的数据源,DataFrame 会自己生成 Schema。
Json 文件生成的 DataFrame 如下:
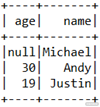
CSV 文件生成的 DataFrame 如下:

2、查询
完成初始化的工作之后就可以使用 DataFrame API 进行查询了,DataFrame API 主要分为两种风格,一种依然是 RDD 算子风格,如 reduce、groupByKey、map、flatMap 等,另外一种则是 SQL 风格,如 select、where 等。
2.1 算子风格
我们简单选取几个有代表性的 RDD 算子风格的 API,具体如下:
def groupByKey[K: Encoder](func: T => K): KeyValueGroupedDataset[K, T]
与 RDD 算子版作用相同,返回类型为 Dataset。
def map[U : Encoder](func: T => U): Dataset[U]
与 RDD 算子版作用相同,返回类型为 Dataset。
def flatMap[U : Encoder](func: T => TraversableOnce[U]): Dataset[U]
与 RDD 算子版作用相同,返回类型为 Dataset。
这些算子用法大同小异,但都需要传入 Encoder 参数,这可以通过隐式转换解决,在调用算子前,需加上:
import spark.implicits._
2.2 SQL风格
这类 API 的共同之处就是支持将部分 SQL 语法的字符串作为参数直接传入。
-
select 和 where
def select(cols: Column*): DataFrame
def where(conditionExpr: String): Dataset[T]
条件查询,例如:
df.select("age").where("name is not null and age > 10").foreach(println(_))
-
groupBy
def groupBy(col1: String, cols: String*): RelationalGroupedDataset
分组统计。例如:
df.select("name","age").groupBy("age").count().foreach(println(_))
此外,某些 RDD 算子风格的 API 也可以传入部分 SQL 语法的字符串,如 filter。例如:
df.select("age", "name").filter("age > 10").foreach(println(_))
-
join
def join(right: Dataset[_], usingColumns: Seq[String], joinType: String): DataFrame
DataFrame API 还支持最普遍的连接操作,代码如下:
val leftDF = ...
val rightDF = ...
leftDF.join(rightDF, leftDF("pid") === rightDF("fid"), "left_outer").foreach(println(_))
其中 joinType 参数支持常用的连接类型,选项有 inner、cross、outer、full、full_outer、left、left_outer、right、right_outer、left_semi 和 left_anti,其中 cross 表示笛卡儿积,这在实际使用中比较少见;left_semi 是左半连接,是 Spark 对标准 SQL 中的 in 关键字的变通实现;left_anti 是 Spark 对标准 SQL 中的 not in 关键字的变通实现。
除了 groupBy 这种分组方式,DataFrame 还支持一些特别的分组方式如 pivot、rollup、cube 等,以及常用的分析函数,先来看一个数据集:
{"name":"Michael", "grade":92, "subject":"Chinese", "year":"2017"}
{“name”:“Andy”, “grade”:87, “subject”:“Chinese”, “year”:“2017”}
{“name”:“Justin”, “grade”:75, “subject”:“Chinese”, “year”:“2017”}
{“name”:“Berta”, “grade”:62, “subject”:“Chinese”, “year”:“2017”}
{“name”:“Michael”, “grade”:96, “subject”:“math”, “year”:“2017”}
{“name”:“Andy”, “grade”:98, “subject”:“math”, “year”:“2017”}
{“name”:“Justin”, “grade”:78, “subject”:“math”, “year”:“2017”}
{“name”:“Berta”, “grade”:87, “subject”:“math”, “year”:“2017”}
{“name”:“Michael”, “grade”:87, “subject”:“Chinese”, “year”:“2016”}
{“name”:“Andy”, “grade”:90, “subject”:“Chinese”, “year”:“2016”}
{“name”:“Justin”, “grade”:76, “subject”:“Chinese”, “year”:“2016”}
{“name”:“Berta”, “grade”:74, “subject”:“Chinese”, “year”:“2016”}
{“name”:“Michael”, “grade”:68, “subject”:“math”, “year”:“2016”}
{“name”:“Andy”, “grade”:95, “subject”:“math”, “year”:“2016”}
{“name”:“Justin”, “grade”:87, “subject”:“math”, “year”:“2016”}
{“name”:“Berta”, “grade”:81, “subject”:“math”, “year”:“2016”}
{“name”:“Michael”, “grade”:95, “subject”:“Chinese”, “year”:“2015”}
{“name”:“Andy”, “grade”:91, “subject”:“Chinese”, “year”:“2015”}
{“name”:“Justin”, “grade”:85, “subject”:“Chinese”, “year”:“2015”}
{“name”:“Berta”, “grade”:77, “subject”:“Chinese”, “year”:“2015”}
{“name”:“Michael”, “grade”:63, “subject”:“math”, “year”:“2015”}
{“name”:“Andy”, “grade”:99, “subject”:“math”, “year”:“2015”}
{“name”:“Justin”, “grade”:79, “subject”:“math”, “year”:“2015”}
{“name”:“Berta”, “grade”:85, “subject”:“math”, “year”:“2015”}
以上是某班学生 3 年的成绩单,一共有 3 个维度,即 name、subject 和 year,度量为 grade,也就是成绩,因此,这个 DataFrame 可以看成三维数据立方体,如下图所示。
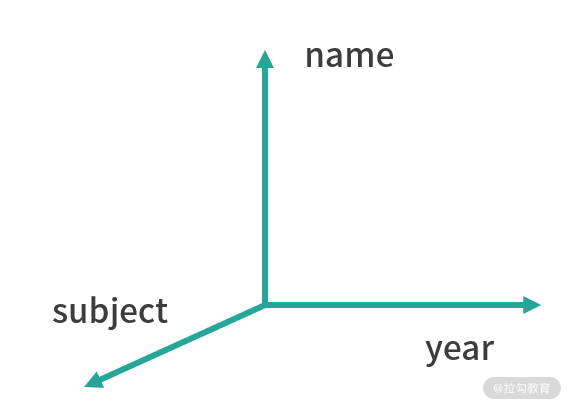
现在需要统计每个学生各科目 3 年的平均成绩,该操作可以通过下面的方式实现:
dfSG.groupBy("name","subject").avg("grade")
但是,这种形式使结果数据集只有两列——name 和 subject,不利于进一步分析,而利用 DataFrame 的数据透视 pivot 功能无疑更加方便。 pivot 功能在 pandas、Excel 等分析工具已得到了广泛应用,用户想使用透视功能,需要指定分组规则、需要透视的列以及聚合的维度列。所谓“透视”比较形象,即在分组结果上,对每一组进行“透视”,透视的结果会导致每一组基于透视列展开,最后再根据聚合操作进行聚合,统计每个学生每科 3 年平均成绩实现如下:
dfSG.groupBy("name").pivot("subject").avg("grade").show()
结果如下:

除了 groupBy 之外,DataFrame 还提供 rollup 和 cube 的方式进行分组聚合,如下:
def rollup(col1: String, cols: String*): RelationalGroupedDataset
rollup 也是用来进行分组统计,只不过分组逻辑有所不同,假设 rollup(A,B,C),其中 A、B、C 分别为 3 列,那么会先对 A、B、C 进行分组,然后依次对 A、B 进行分组、对 A 进行分组、对全表进行分组,执行:
dfSG.rollup("name", "subject").avg("grade").show()
结果如下:
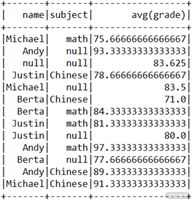
可以看到,除了按照 name + subject 的组合键进行分组,还分别对每个人进行了分组,如 Michael,null,此外还将全表分为了一组,如 null,null。
def cube(col1: String, cols: String*): RelationalGroupedDataset
cube 与 rollup 类似,分组依据有所不同,仍以 cube(A,B,C) 为例,分组依据分别是 (A,B,C)、(A,B)、(A,C)、(B,C)、(A)、(B)、(C)、全表,执行:
dfSG.cube("name", "subject").avg("grade").show()
结果如下:
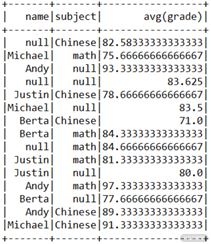
可以看到与 rollup 不同,这里还分别对每个科目进行分组,如 null、math。
在实际使用中,你应该尽量选用并习惯于用 SQL 风格的算子完成开发任务,SQL 风格的查询 API 不光表现力强,另外也非常易读。
3、写出
与创建 DataFrame 的 read 读取器相对应,写出为 write 输出器 API。下面列举了如何输出几种常见格式的文件。
-
写出为 Json 文件:
df.select("age", "name").filter("age > 10").write.json("/your/output/path")
-
写出为 Parquet 文件:
df.select("age", "name").filter("age > 10").write.parquet("/your/output/path")
-
写出为 ORC 文件:
df.select("age", "name").filter("age > 10").write.orc("/your/output/path")
-
写出为文本文件:
df.select("age", "name").filter("age > 10").write.text("/your/output/path")
-
写出为 CSV 文件:
val saveOptions = Map("header" -> "true", "path" -> "csvout")
df.select("age", "name").filter("age > 10")
.write
.format("com.databricks.spark.csv")
.mode(SaveMode.Overwrite)
.options(saveOptions)
.save()
我们还可以在保存时对格式已经输出的方式进行设定,例如本例中是保留表头,并且输出方式是 Overwrite,输出方式有 Append、ErrorIfExist、Ignore、Overwrite,分别代表追加到已有输出路径中、如果输出路径存在则报错、存在则停止、存在则覆盖。
-
写出到关系型数据库:
val prop = new java.util.Properties
prop.setProperty("user","spark")
prop.setProperty("password","123")
df.write.mode(SaveMode.Append).jdbc("jdbc:mysql://localhost:3306/test","tablename",prop)
写出到关系型数据库同样基于 JDBC ,用此种方式写入关系型数据库,表名可以不存在。
Dataset API
从本质上来说,DataFrame 只是 Dataset 的一种特殊情况,在 Spark 2.x 中已经得到了统一:
DataFrame = Dataset[Row]
因此,在使用 DataFrame API 的过程中,很容易就会自动转换为 Dataset[String]、Dataset[Int] 等类型。除此之外,用户还可以自定义类型。下面来看看 DataFrame 转成 Dataset 的例子,下面是一个 Json 文件,记录了学生的单科成绩:
{"name":"Michael", "grade":92, "subject":"Chinese"}
{“name”:“Andy”, “grade”:87, “subject”:“Chinese”}
{“name”:“Justin”, “grade”:75, “subject”:“Chinese”}
{“name”:“Berta”, “grade”:62, “subject”:“Chinese”}
{“name”:“Michael”, “grade”:96, “subject”:“math”}
{“name”:“Andy”, “grade”:98, “subject”:“math”}
{“name”:“Justin”, “grade”:78, “subject”:“math”}
{“name”:“Berta”, “grade”:87, “subject”:“math”}
代码如下:
// 首先定义StudentGrade类
case class StudentGrade(name: String, subject: String, grade: Long)
// 生成DataFrame
val dfSG = spark.read.json("data/examples/target/scala-2.11/classes/student_grade.json")
// 方法1:通过map函数手动转换为Dataset[StudentGrade]类型
val dsSG: Dataset[StudentGrade] = dfSG.map(a => StudentGrade(a.getAs[String](0),a.getAs[String](1),a.getAs[Long](2)))
// 方法2:使用DataFrame的as函数进行转换
val dsSG2: Dataset[StudentGrade] = dfSG.as[StudentGrade]
// 方法3:通过RDD转换而成(基于同样内容的CSV文件)
val dsSG3 = spark.sparkContext.
textFile("data/examples/target/scala-2.11/classes/student_grade.csv").
map[StudentGrade](row => {
val fields = row.split(",")
StudentGrade(
fields(0).toString(),
fields(1).toString(),
fields(2).toLong
)
}).toDS
// 求每科的平均分
dsSG3.groupBy("subject").mean("grade").foreach(println(_))
以上 3 种方法都可以将 DataFrame 转换为 Dataset 。转换完成后,就可以使用其 API 对数据进行分析,使用方式与 DataFrame 并无不同。
Spark SQL
在实际工作中,使用频率最高的当属 Spark SQL,通常一个大数据处理项目中,70% 的数据处理任务都是由 Spark SQL 完成,它贯穿于数据预处理、数据转换和最后的数据分析。由于 SQL 的学习成本低、用户基数大、函数丰富,Spark SQL 也通常是使用 Spark 最方便的方式。此外,由于 SQL 包含了丰富的应用语义,所以 Catalyst 优化器带来的性能巨大提升也使 Spark SQL 成为编写 Spark 作业的最佳方式。接下来我将为你介绍 Spark SQL 的使用。
从使用层面上来讲,要想用好 Spark SQL,只需要编写 SQL 就行了,本课时的最后简单介绍了下 SQL 的常用语法,方便没有接触过 SQL 的同学快速入门。
1、创建临时视图
想使用 Spark SQL,可以先创建临时视图,相当于数据库中的表,这可以通过已经存在的 DataFrame、Dataset 直接生成;也可以直接从 Hive 元数据库中获取元数据信息直接进行查询。先来看看创建临时视图:
case class StudentGrade(name: String, subject: String, grade: Long)
// 生成DataFrame
val dfSG = spark.read.json("data/examples/target/scala-2.11/classes/student_grade.json")
// 生成Dataset
val dsSG = dfSG.map(
a => StudentGrade(
a.getAs[String]("name"),
a.getAs[String]("subject"),
a.getAs[Long]("grade")
)
)
// 创建临时视图
dfSG.createOrReplaceTempView("student_grade_df")
dsSG.createOrReplaceTempView("student_grade_ds")
// 计算每科的平均分
spark.sql("SELECT subject, AVG(grade) FROM student_grade_df GROUP BY subject").show()
spark.sql("SELECT subject, AVG(grade) FROM student_grade_ds GROUP BY subject").show()
对于 Dataset 来说,对象类型的数据结构会作为临时视图的元数据,在 SQL 中可以直接使用。
2、使用Hive元数据
随着 Spark 越来越流行,有很多情况,需要将 Hive 作业改写成 Spark SQL 作业,Spark SQL 可以通过 hive-site.xml 文件的配置,直接读取 Hive 元数据。这样,改写的工作量就小了很多,代码如下:
val spark = SparkSession
.builder()
.master("local[*]")
.appName("Hive on Spark")
.enableHiveSupport()
.getOrCreate()
// 直接查询
spark.sql(…………)
代码中通过 enableHiveSupport 方法开启对 Hive 的支持,但需要将 Hive 配置文件 hive-site.xml 复制到 Spark 的配置文件夹下。
3、查询语句
Spark 的 SQL 语法源于 Presto (一种支持 SQL 的大规模并行处理技术,适合 OLAP),在源码中我们可以看见,Spark 的 SQL 解析引擎直接采用了 Presto 的 SQL 语法文件。查询是 Spark SQL 的核心功能,Spark SQL 的查询语句模式如下:
[ WITH with_query [, ...] ]
SELECT [ ALL | DISTINCT ] select_expr [, ...]
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition]
[ UNION [ ALL | DISTINCT ] select ]
[ ORDER BY expression [ ASC | DESC ] [, ...] ]
[ LIMIT count ]
其中 from_item 为以下之一:
table_name [ [ AS ] alias [ ( column_alias [, ...] ) ] ]
from_item join_type from_item [ ON join_condition | USING ( join_column [, ...] ) ]
该模式基本涵盖了 Spark SQL 中查询语句的各种写法。
3.1 SELECT 与 FROM 子句
SELECT 与 FROM 是构成查询语句的最小单元,SELECT 后面跟列名表示要查询的列,或者用 * 表示所有列,FROM 后面跟表名,示例如下:
SELECT name, grade FROM student_grade t;
在使用过程中,对列名和表名都可以赋予别名,这里对 student_grade 赋予别名 t,此外我们还可以对某一列用关键字 DISTINCT 进行去重,默认为 ALL,表示不去重:
SELECT COUNT( DISTINCT name) FROM student_grade;
上面这条 SQL 代表统计有多少学生参加了考试。
3.2 WHERE 子句
WHERE 子句经常和 SELECT 配合使用,用来过滤参与查询的数据集,WHERE 后面一般会由运算符组合成谓词表达式(返回值为 True 或者 False ),例如:
SELECT * FROM student_grade WHERE grade > 90;
SELECT * FROM student_grade WHERE name IS NOT NULL;
SELECT * FROM student_grade WHERE name LIKE "*ndy";
常见的运算符还有 !=、<> 等,此外还可以用逻辑运算符:AND、OR 组合谓词表达式进行查询,例如:
SELECT * FROM student_grade WHERE grade > 90 AND name IS NOT NULL
3.3 GROUP BY 子句
GROUP BY 子句用于对 SELECT 语句的输出进行分组,分组中是匹配值的数据行。GROUP BY 子句支持指定列名或列序号(从 1 开始)表达式。以下查询是等价的,都会对 subject 列进行分组,第一个查询使用列序号,第二个查询使用列名:
SELECT avg(grade), subject FROM student_grade GROUP BY 2;
SELECT avg(grade), subject FROM student_grade GROUP BY subject;
使用 GROUP BY 子句时需注意,出现在 SELECT 后面的列,要么同时出现在 GROUP BY 后面,要么就在聚合函数中。
3.4 HAVING 子句
HAVING 子句与聚合函数以及 GROUP BY 子句配合使用,用来过滤分组统计的结果。HAVING 子句去掉不满足条件的分组。在分组和聚合计算完成后,HAVING 对分组进行过滤。例如以下查询会过滤掉平均分大于 90 分的科目:
SELECT subject,AVG(grade)
FROM student_grade
GROUP BY subject
HAVING AVG(grade) < 90;
3.5 UNION 子句
UNION 子句用于将多个查询语句的结果合并为一个结果集:
query UNION [ALL | DISTINCT] query
参数 ALL 或 DISTINCT 可以控制最终结果集包含哪些行。如果指定参数 ALL,则包含全部行,即使行完全相同;如果指定参数 DISTINCT ,则合并结果集,结果集只有唯一不重复的行;如果不指定参数,执行时默认使用 DISTINCT。下面这句 SQL 是将两个班级的成绩进行合并:
SELECT * FROM student_grade_class1
UNION ALL
SELECT * FROM student_grade_class2;
多个 UNION 子句会从左向右执行,除非用括号明确指定顺序。
3.6 ORDER BY 子句
ORDER BY 子句按照一个或多个输出表达式对结果集排序:
ORDER BY expression [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...]
每个表达式由列名或列序号(从 1 开始)组成。ORDER BY 子句作为查询的最后一步,在 GROUP BY 和 HAVING 子句之后。ASC 为默认升序,DESC 为降序。下面这句 SQL 会对结果进行过滤,并按照平均分进行排序,注意这里使用了列别名:
SELECT subject,AVG(grade) avg
FROM student_grade
GROUP BY subject
HAVING AVG(grade) < 90
ORDER BY avg DESC;
3.7 LIMIT 子句
LIMIT 子句限制结果集的行数,这在查询大表时很有用。以下示例为对单科成绩进行排序并只返回前 3 名的记录:
SELECT * FROM student_grade
WHERE subject = 'math'
ORDER BY grade DESC
LIMIT 3;
3.8 JOIN 子句
JOIN 操作可以将多个有关联的表进行关联查询,下面这句 SQL 是查询数学成绩在 90 分以上的学生的院系,其中院系信息可以从学生基础信息表内,通过姓名连接得到:
SELECT g.*, a.department
FROM student_grade g
JOIN student_basic b
ON g.name = b.name
WHERE g.subject = 'math' and grade > 90
在这句 SQL 中,表 g 被称为驱动表或是左表,表 b 被称为右表。如前所述,Spark 支持多种连接类型。















 6447
6447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









