






这是后端功能代码的搭建流程,只是一个演示。后续会更新llm过程代码以及通过FastAPI与gradio前端进行通信的接口。以搭建一个有用户登录、注册界面,对话界面、会话历史等界面的系统
ollama+qwen2.5+nomic本地部署
1.ollama部署
windows版本
1.点击这里 https://ollama.com/download/windows 下载 Ollama 安装程序。
2.右键单击下载的 OllamaSetup.exe 文件并以管理员身份运行安装程序。
3.安装完成后,Ollama 就可以在您的 Windows 系统上使用。
由于Ollama的exe安装软件双击安装的时候默认是在C盘,以及后续的模型数据下载也在C盘,导致会占用C盘空间,所以这里单独写了一个自定义安装Ollama安装目录的教程。
1.手动创建Ollama安装目录
首先在你想安装的路径下创建好一个新文件夹,并把Ollama的安装包放在里面。比如我的是:D:\Experiment\Ollama
在文件路径上输入CMD回车后会自动打开命令窗口
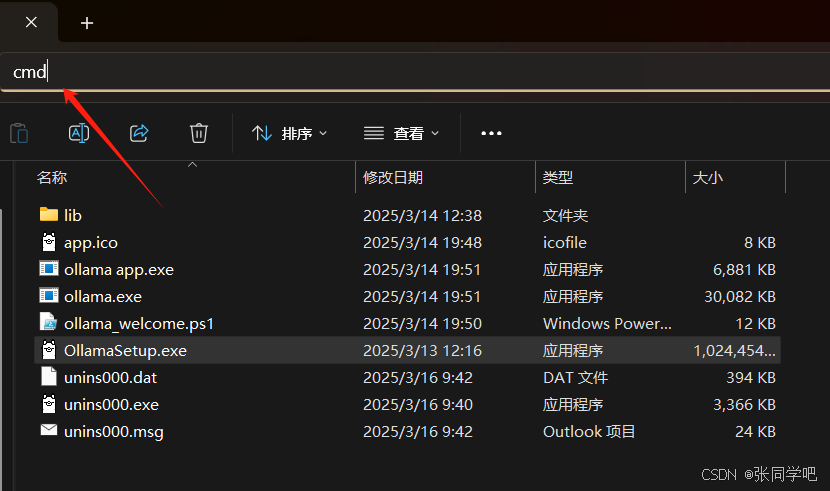
2.输入命令行
然后在CMD窗口输入:OllamaSetup.exe /DIR=D:\Experiment\Ollama

然后Ollama就会开始安装,点击Install后,可以看到Ollama的安装路径就变成了我们指定的目录了,这样大模型数据包也会默认下载在指定目录中。
Linux版本
在Linux平台下,Ollama提供了一种简单的安装方法,只需一行命令即可完成安装。
1.安装Ollama
curl -fsSL https://ollama.com/install.sh | sh
2.更新Ollama
curl -fsSL https://ollama.com/install.sh | sh
3.卸载Ollama
如果您决定不再使用Ollama,可以通过以下步骤将其完全从系统中移除:
1.停止并禁用服务
sudo systemctl stop ollama
sudo systemctl disable ollama
2.删除服务文件和Ollama二进制文件
sudo rm /etc/systemd/system/ollama.service
sudo rm $(which ollama)
3.清理Ollama用户和组
sudo rm -r /usr/share/ollama
sudo userdel ollama
sudo groupdel ollama
验证方法
不论是windows还是linux平台,都通过ollama --version来验证ollama是否安装成功。
windows直接win+R,输入cmd,启动命令窗口。

linux或者服务器直接启动终端输入。

2.qwen2.5为例的推理模型
1.ollama run qwen2.5:7b:
ollama pull qwen2.5:7b
这将从 Ollama 的模型库中下载 qwen2.5 模型。
2.下载完成后,可以使用以下命令查看已下载的模型:
ollama list
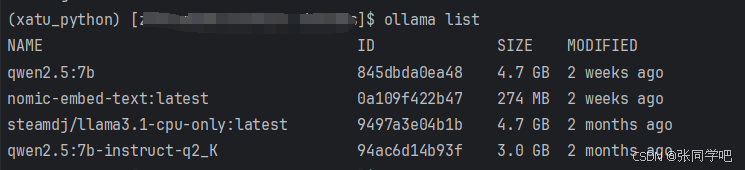
细心的小伙伴可以发现在模型名称的后面,应该是qwen2.5的版本信息。没错,这是一个模型根据他的权重大小和运行所学显存来分的等级。如qwen2.5根据他的权重和运行占用显存分为了三个等级,分别是:
NAME 显存占用 SIZE
qwen2.5:32b 24 G 19 GB
qwen2.5:14b 11 G 9.0 GB
qwen2.5:7b 6 G 4.7 GB
在ollama官网上还有好多好用的最新的模型等你来run,感兴趣的小伙伴可以自行搜索排行榜。
3.nomic-embed-text为例的嵌入模型
1.与qwen2.5的下载过程一致,我们直接使用pull来下载即可。
ollama pull nomic-embed-text
2.Embedding排行榜
Huggingface上的mteb是一个海量Embeddings排行榜,定期会更新Huggingface开源的Embedding模型各项指标,进行一个综合的排名。因为某个模型对于不同语种的嵌入能力会有差异,要注意辨别。我们可以选择符合我们使用场景的Embedding模型。
4.模型调用
- 查看ollama所服务的端口
ollama serve

默认情况下,安装好ollama之后就已经启动API服务了,Ollama只能为一个端口服务,所以再次启动serve时会有一个Error,但是并不影响我们通过端口调用模型。
- 通过API端口调用示例
import requests
def generate_answer(query: str, context: str = "") -> str:
"""调用 Ollama 的 API 生成答案。"""
data = {
"model": "qwen2.5:7b", # 使用生成文本的模型
"prompt": f"""
You are an AI assistant that answers questions based on the provided context.
### Context:
{context}
### Question:
{query}
### Answer:""",
# context为提供实际的上下文信息,query为用户的问题。
# 输入给模型的文本内容(例如问题或指令)。
"stream": False, # 是否为流式输出
"temperature": 0.7, # 生成答案时的温度参数(值越高,输出越随机)
"max_tokens": 200 # 限制生成文本的最大长度(以 token 为单位)
}
response = requests.post("http://127.0.0.1:11434/api/generate", json=data)
if response.status_code == 200:
return response.json().get("response", "")
else:
return f"API 请求失败,状态码:{response.status_code}"
# 示例对话
context = "The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France."
question = "Where is the Eiffel Tower located?"
answer = generate_answer(question, context)
print(f"Question: {question}")
print(f"Answer: {answer}")
- 请求的过程
- 构造请求:
使用 requests.post 方法发送 HTTP POST 请求。请求的 URL 是 “http://127.0.0.1:11434/api/embeddings”,也就是ollama服务的API端口+/api/embeddings(如果你是generate模型就是+/api/generate,因为有的模型无法generate只能embedding)。
请求体是 data,以 JSON 格式发送。 - 发送请求:
请求被发送到本地运行的 Ollama API 服务(http://127.0.0.1:11434/api/embeddings)。
API 会根据请求的内容生成文本的嵌入。 - 接收响应:
如果请求成功(HTTP 状态码为 200),API 会返回一个 JSON 格式的响应。
响应中通常包含生成的嵌入向量(embeddings)以及其他元数据。 - 处理响应:
通过 response.json() 解析响应体。
提取嵌入向量(例如 response.json().get(“embeddings”))。
- 构造请求:
- 运行结果
 这就是所有的部署流程以及简单的提问&回复的流程。模型的一些参数可以根据实际应用场景来更改。最后祝小伙伴大模型的学习顺利!
这就是所有的部署流程以及简单的提问&回复的流程。模型的一些参数可以根据实际应用场景来更改。最后祝小伙伴大模型的学习顺利!

















 1549
1549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









