







一、I/O与显示器
CPU 通过 out 指令 将内容发送到终端设备:显示器
1.让外设工作起来:CPU 给相应的硬件的控制器或者寄存器发出相应的指令
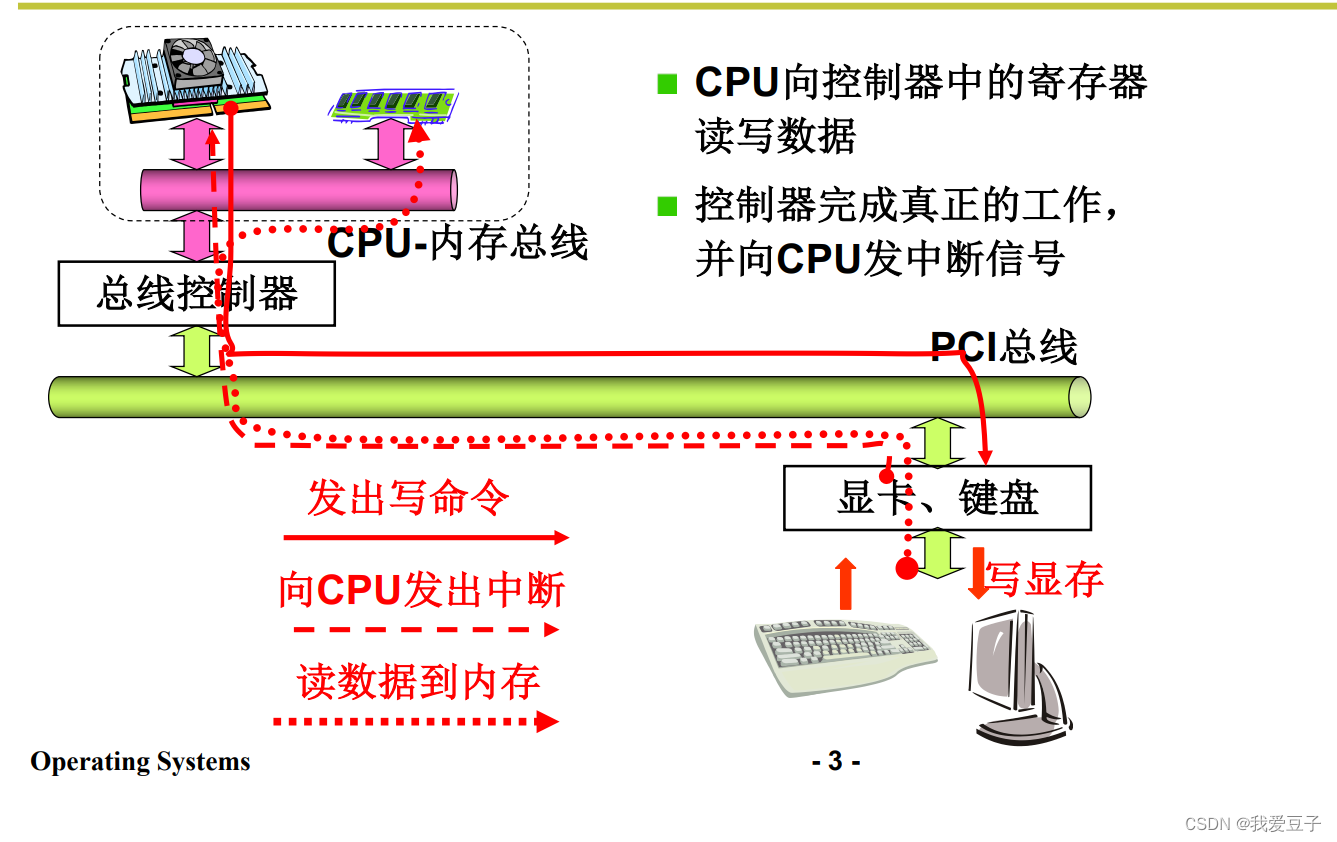
对外设使用:
- 对控制器(对应端口)发指令:out xxx,al
- 外设工作完毕,向CPU发中断处理信号
- 文件视图(文件接口):OS给用户提供简单视图,方便用户使用
形成文件视图(即统一文件接口)-----> CPU发出 out 指令 -----> 形成中断处理!!!!
2.一段操纵外设的程序
(1)不论什么外部设备都是open,read,write,close
OS为用户提供统一接口
(2)不同设备对应不同设备文件
根据设备文件找到控制器的地址、内容格式等
3.文件视图

无论用什么外设,都从文件接口开始
4.printf(" Host Name : %s " , name)
(1)先创建缓存buf,将格式化输出写入其中,然后再write(1,buf):int 0x80,sys_write
- write(1,buf)中的1:dev / tty0 (终端设备)对应iNode

- write(1,buf)中的1从哪里来:从PCB来
- PCB创建:fork创建时copy_process来的(从父进程copy来的)
- 父进程(shell进程):系统初始化时打开 dev / tty0 文件
- 故1从哪里来:shell进程(dev / tty0 )-----> PCB -----> write(1,buf)
- inode:file的目的是得到iNode,显示器信息就在这里
- iNode = file ---> f_iNode
- iNode:存放文件信息(设备文件:哪些设备,什么类型设备)
open系统调用过程:open( "dev / tty0 ")
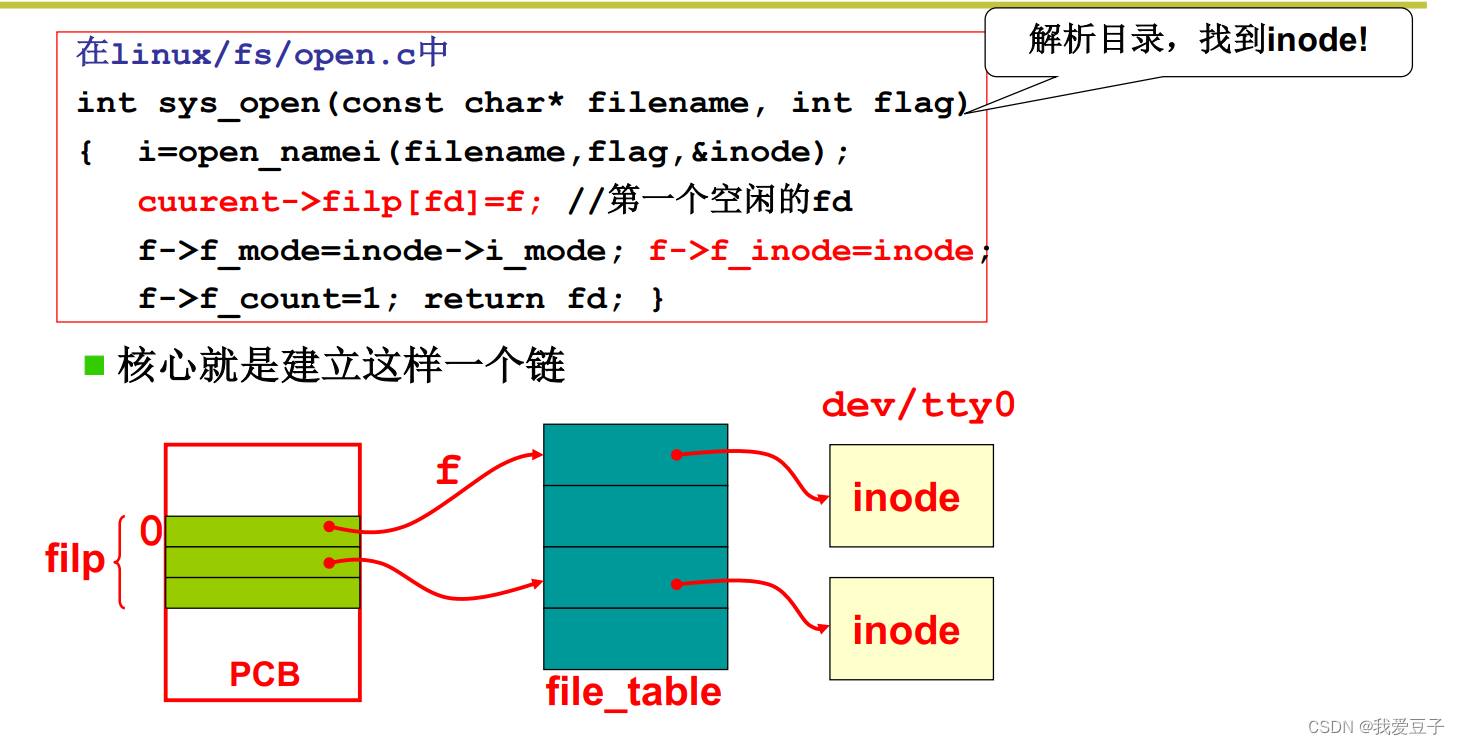
- open( "dev / tty0 ") 产生write(1,buf)中的1
- open( "dev / tty0 ")核心:把dev / tty0 这个设备文件所对应的信息写到iNode上(读进dev/tty0信息)
- write(1,buf)中的1是找到dev/tty0对应的iNode
(2)继续 sys_write:判断设备是块设备还是字符设备(iNode)
几号设备(iNode里面)

(3)假设是字符设备:转到 rw_char :根据几号设备(设备表:crw_table)做相应处理

(4)假设是4号设备L在 crw_table 中找到 4 号设备对应操作 rw_ttyx
(5)转到 rw_ttyx:判断终端设备是写还是读(终端设备:键盘读、显示器写)
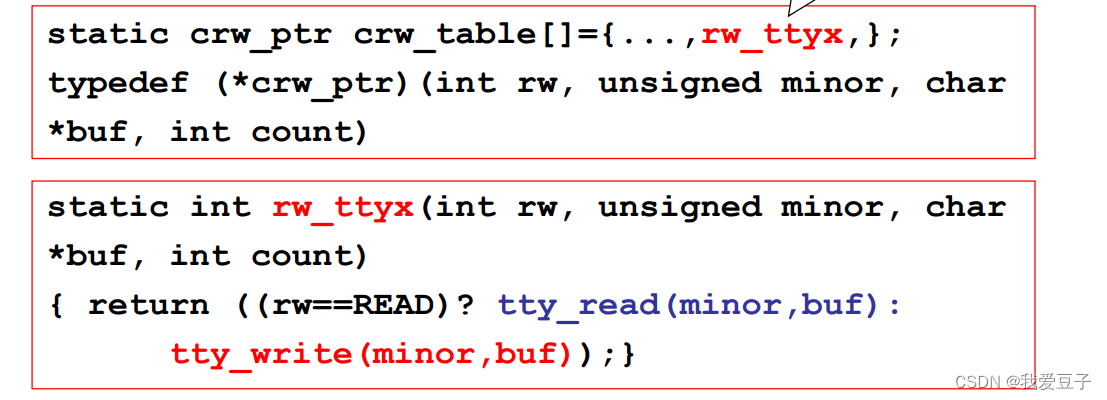
(6)假设显示器写操作:tty_write // 实现输出的核心函数
tty_write 写入队列,若队列满,sleep
写在显示器前是先写入缓冲设备
缓冲设备是平衡CPU和设备运行速度不平衡

(7)调用函数 con_write ,从缓冲区提取信息到显卡
何时调用中断处理程序:显存 con_write 发现设备工作完(即写完设备)

(8)tty_write 在结构体 tty_struct中
tty_struct 中有 con_write

con_write 真正写显示器:out(和内存独立编址)xxxx,al
move(和内存统一编址)xxxx,al
5. printf的整个过程:文件视图

系统调用(write):
- 在系统初始化时,shell进程初始化,进行open(" dev/tty0 "):把 dev/tty0 这个设备文件所对应设备信息写入iNode
- 而write(1,buf)中的1 就是找到shell进程中对应设备信息的iNode
二、键盘
对于OS:敲了键盘就中断(int 0x21)
1.中断处理函数(keyboard_interrupt)

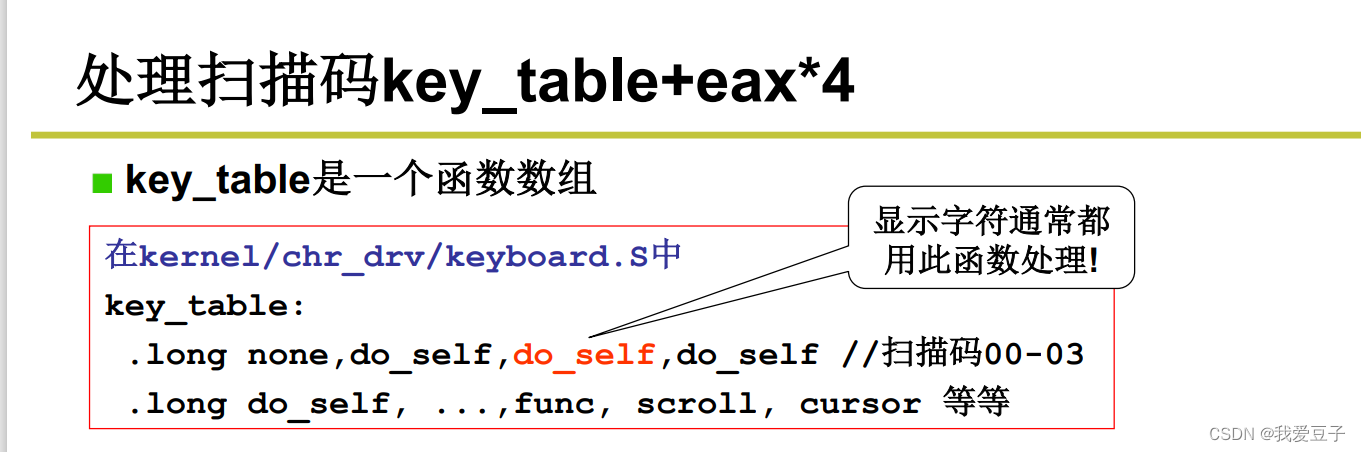



put_queue将ASCII码放到 tty_queue (缓冲队列)
- CPU从 tty_queue 中读入写的信息:con.read_ q函数

回显:
- 将字符放入 write_queue 中,用 con_write 写到显示器

键盘处理、显示器处理!!!!

三、生磁盘的使用
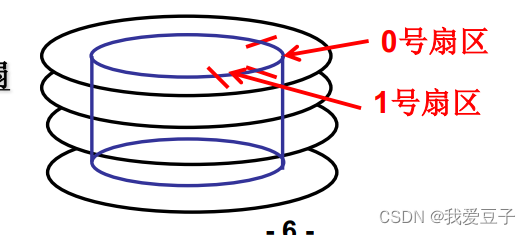
磁盘的访问单位是 扇区
扇区的大小:512字节
读/写磁盘:找到磁道(磁头)---->旋转磁盘找到扇区(磁盘控制器)寻道 ---->旋转 ---->数据传输

1.通过盘快好读写磁盘(一层抽象)

- 磁盘访问时间 = 队列时间+写入控制器时间 + 寻道时间(浪费时间最多) + 旋转时间 + 传输时间(可以忽略)
- 如何编址? block相邻的盘块可以快速读出(放在相同盘块)
- 7号扇区放在0号扇区下面
OS的目的:使用户使用硬件简单、高效
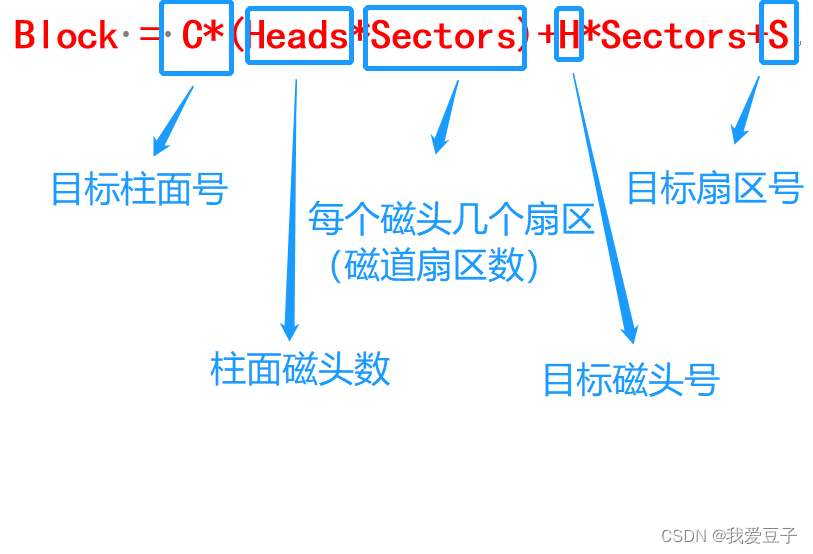
S = block % Sectors

- 盘块:连续几个扇区变成盘块(盘块是磁盘读写基本单位,空间换时间)
- Linux0.11 的盘块为2个扇区
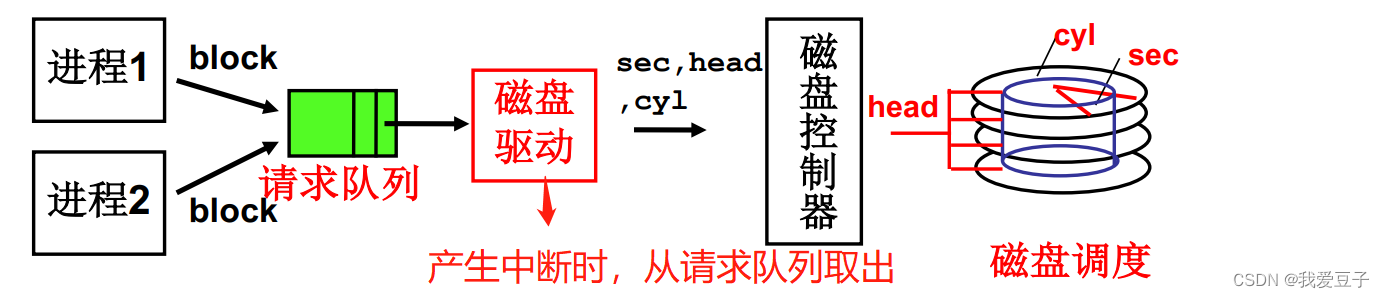
2.多个进程通过队列使用磁盘(第二层抽象)
(1)FCFS磁盘调度算法:
- 最直观、最公平的调度

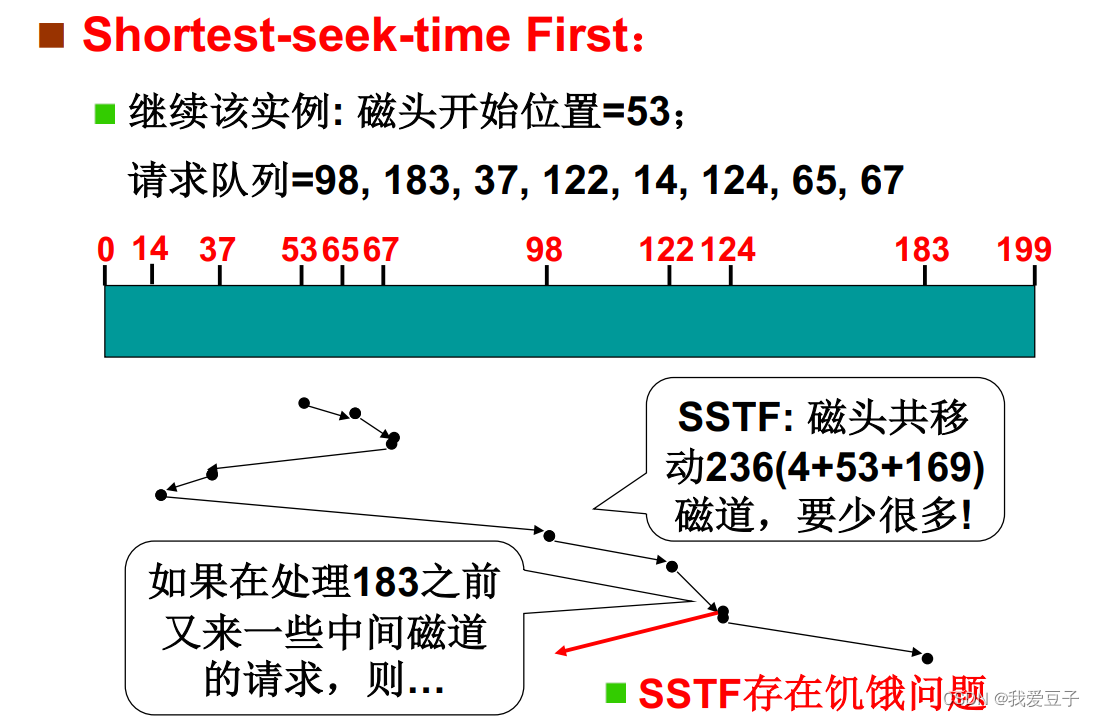
(2)SSTF(短寻道优先):磁头总在中间处理(存在饥饿)
- 总是选择最小寻找时间并不能保证平均寻找时间最小,比 FCFS 算法性能更好
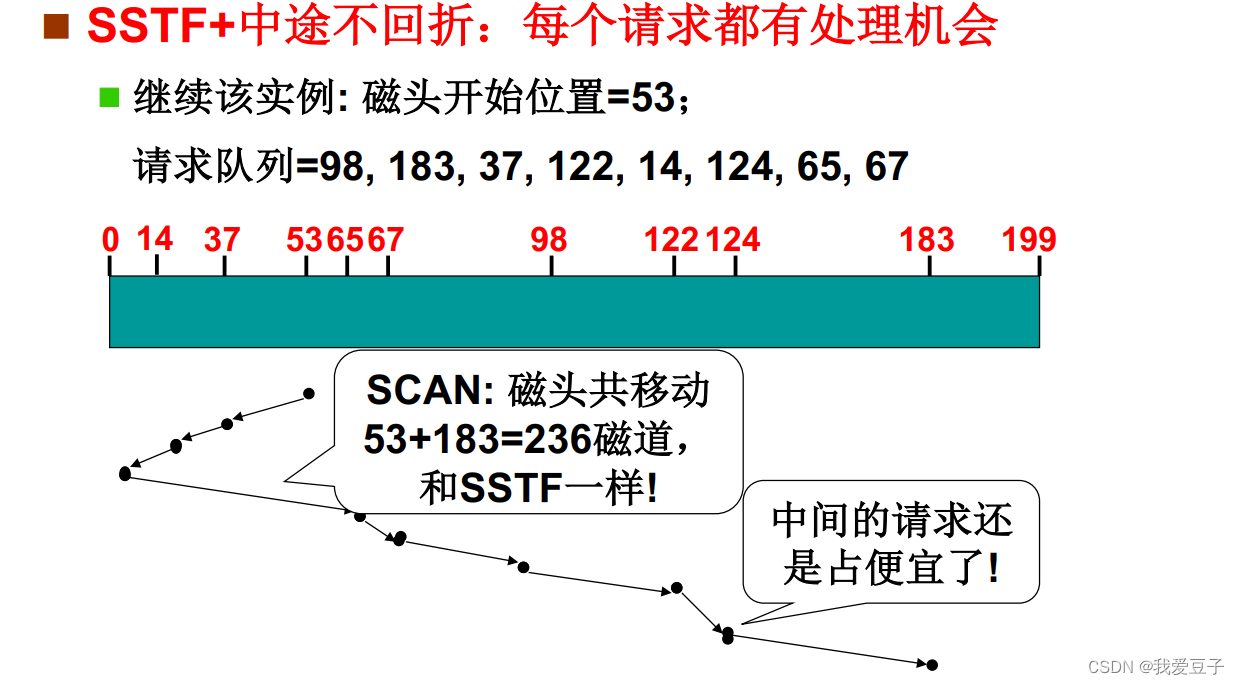
(3)SCAN磁盘调度:
- SSTF + 中途不回折:每个请求都有处理机会
- SCAN 算法对最近扫描过的区域不公平,因此,它在访问局部性方面不如 FCFS 算法和 SSTF 算法好
(4)C - SCAN(电梯算法):
- SCAN + 直接移动到另一端:两端请求都能很快处理

多个进程使用生磁盘过程:
- 进程“得到盘快号”,算出对应起始位置的扇区号(sector)
- 用扇区号make_req,用电梯算法add_request(形成队列)
- 进程sleep_on
- 磁盘中断处理
- do_hd_request 是算出cyl、head、sectors
- hd_out调用outp(……)完成端口写

四、从生磁盘到文件(磁盘使用的第三层抽象)
文件:建立字符流到盘块集合的映射关系,这个映射关系对航层用户透明
- 用户发出请求 ----> OS根据映射关系找到相应盘块(解释) ----> OS发出读/写请求 ----> 放入电梯队列 ----> 磁盘驱动从电梯队列中取出请求,并解释出cyl,head,sec
1.连续结构来实现文件(不适合动态增长)
- 6号盘块:0~99字符
- 7号盘块:100~199字符

映射表中存放:test.c 的 FCB(文件控制块)

2.链式结构(列表)(适合动态增长,存取慢)
映射表:test.c 的 FCB

例: FAT 文件系统,它没有 inode,每个 block 中存储着下一个 block 的编号

3.索引结构:连续结构和链式结构的折中
- test.c 的 FCB
- 索引块19中存放的是 test.c 中所有字符对应的盘块号(iNode)
- 实际系统是多级索引

例: Ext2 文件系统,当要读取一个文件的内容时,先在 inode 中查找文件内容所在的所有 block,然后把所有 block 的内容读出来


五、文件使用的磁盘实现

1.用户发出将200~212字符删去(file_write)
file_write(inode,file,buf,count)
- file中有一个读写指针,是开始地址(200),fseek(从文件开始第多少个偏移)就是修改读写指针,再加上count(12),就锁定200~212字符
- 根据iNode找到盘块号(一个盘块号2个字节;一个盘块2个扇区1024字节=1K)
- 用盘块号、buf等形成request放入电梯队列

2.create_block
- 调用_bmap(m_inode,*inode,int block,int create)
block:[0~6]:直接数据块
block:if(block<512):一级间接索引


六、目录与文件系统
1.目录树:最常用文件系统
文件经 K 次划分后,每个集合中的文件数为 O(logkN)
目录:
- 表示一个文件集合
-
建立一个目录时,会分配一个 inode 与至少一个 block,block 记录的内容是目录下所有文件的 inode 编号以及文件名
-
可以看到文件的 inode 本身不记录文件名,文件名记录在目录中,因此新增文件、删除文件、更改文件名这些操作与目录的写权限有关
-
如果突然断电,那么文件系统会发生错误,例如断电前只修改了 block bitmap,而还没有将数据真正写入 block 中。
-
ext3/ext4 文件系统引入了日志功能,可以利用日志来修复文件系统
2.用“my/data/a”定位文件a




3.目录配置
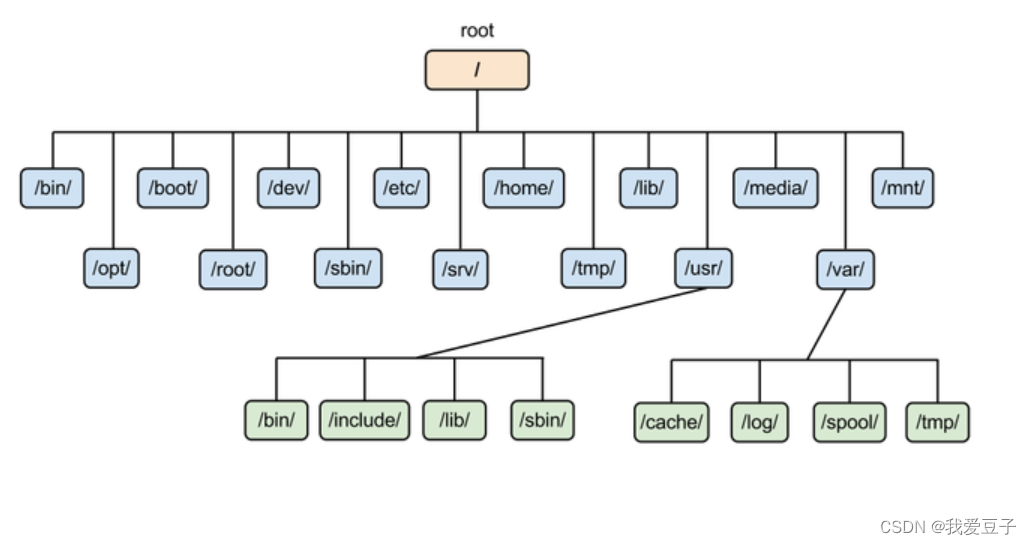
为了使不同 Linux 发行版本的目录结构保持一致性,Filesystem Hierarchy Standard (FHS) 规定了 Linux 的目录结构。最基础的三个目录如下:
- / (root, 根目录)
- /usr (unix software resource):所有系统默认软件都会安装到这个目录
- /var (variable):存放系统或程序运行过程中的数据文件
七、目录解析代码实现
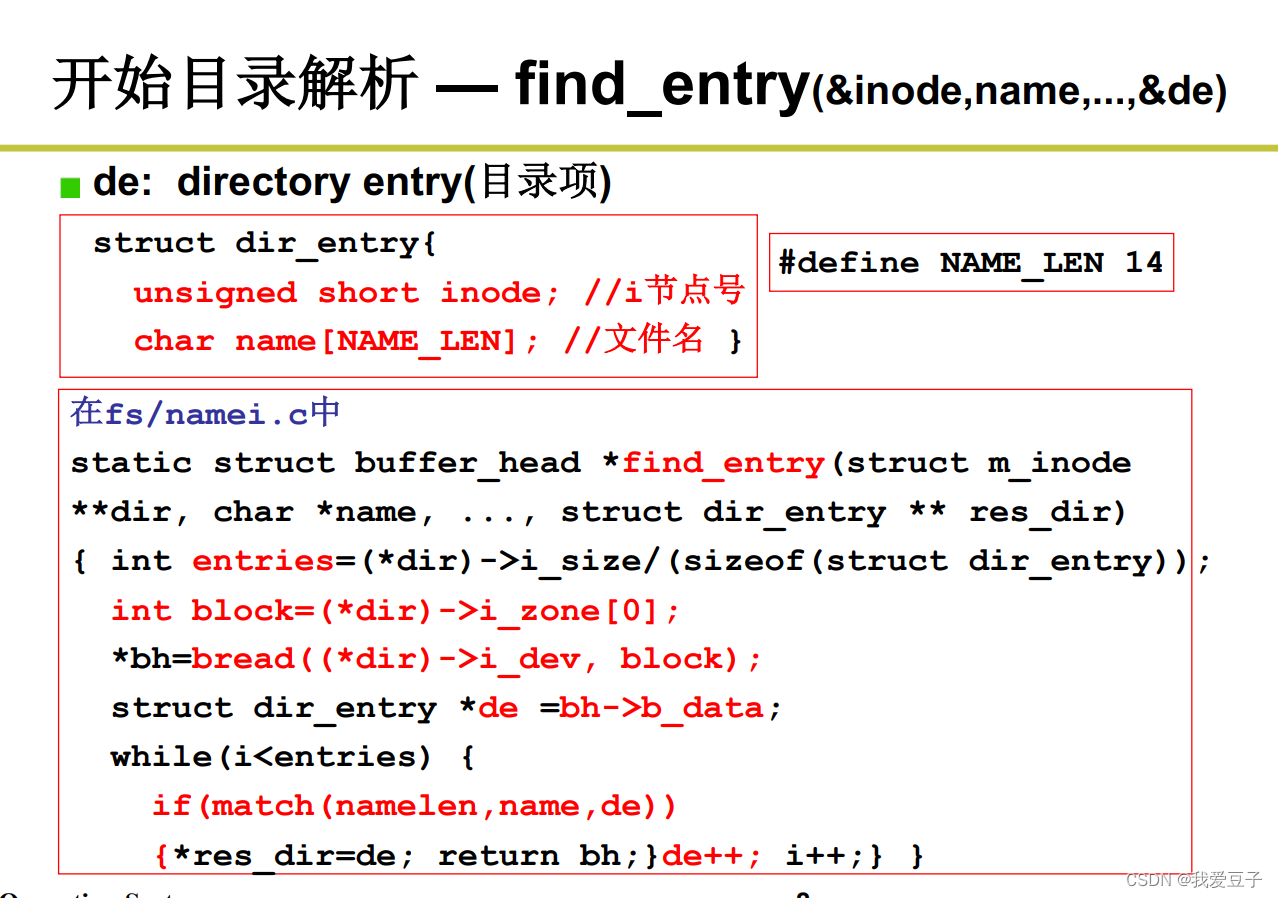
1.get_dir 完成真正的目录解析
- root:找到根目录
- find_entry:从目录中读取目录项

- inr:目录项中的索引节点<var,13>中的13
- iget:在读下一层目录
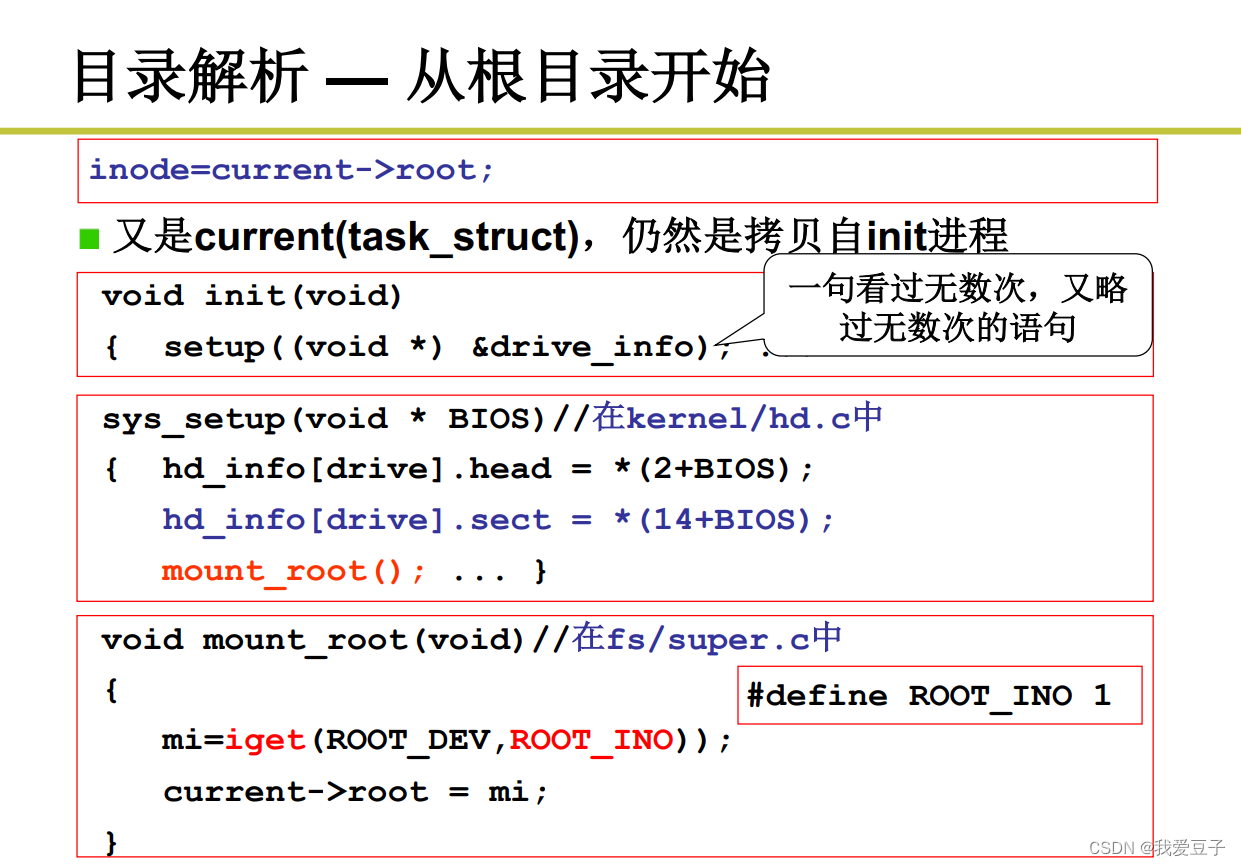
2.目录解析——从根目录开始
- 算出根目录所对应iNode数组中的起始盘块号,根据盘块号读入盘块,抽取iNode
3.读取iNode_iget

4.find_entry:var(匹名filename)
- 找到iNode,再读iNode,iget,find_entry,直到循环结束,无(“/”)
八、文件系统琐碎知识点
- inode:一个文件占用一个 inode,记录文件的属性,同时记录此文件的内容所在的 block 编号
- block:记录文件的内容,文件太大时,会占用多个 block
- superblock:记录文件系统的整体信息,包括 inode 和 block 的总量、使用量、剩余量,以及文件系统的格式与相关信息等;
- block bitmap:记录 block 是否被使用的位图
1.inode 具体包含以下信息:
- 权限 (read/write/excute);
- 拥有者与群组 (owner/group);
- 容量;
- 建立或状态改变的时间 (ctime);
- 最近读取时间 (atime);
- 最近修改时间 (mtime);
- 定义文件特性的旗标 (flag),如 SetUID...;
- 该文件真正内容的指向 (pointer)。
2.inode 具有以下特点:
- 每个 inode 大小均固定为 128 bytes (新的 ext4 与 xfs 可设定到 256 bytes);
- 每个文件都仅会占用一个 inode。
- inode 中记录了文件内容所在的 block 编号,但是每个 block 非常小,一个大文件随便都需要几十万的 block。而一个 inode 大小有限,无法直接引用这么多 block 编号。因此引入了间接、双间接、三间接引用。间接引用让 inode 记录的引用 block 块记录引用信息
3.挂载:
- 挂载利用目录作为文件系统的进入点,也就是说,进入目录之后就可以读取文件系统的数据















 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









