






 本文探讨了日志关联分析在数字化转型中网络运维中的重要性,特别是面对海量数据、多重上报和设备间关联性问题。通过引入AI和知识图谱技术,文章介绍了如何利用AI算法自动挖掘日志关联,减少人工定义的局限,以及基于AI的根因推导,以提高运维效率和问题定位准确性。
本文探讨了日志关联分析在数字化转型中网络运维中的重要性,特别是面对海量数据、多重上报和设备间关联性问题。通过引入AI和知识图谱技术,文章介绍了如何利用AI算法自动挖掘日志关联,减少人工定义的局限,以及基于AI的根因推导,以提高运维效率和问题定位准确性。
1 日志关联分析的挑战
随着各行各业数字化转型的不断深入,网络承载了人们日常生活所需的政务、金融、娱乐等多方面的业务系统,已经成为影响社会稳定运行、关系国计民生的重要基础设施资源。哪怕网络发生及其微小的故障,也可能带来难以估量的后果。因此,网络运维人员在保证网络平稳运行的基础上,还要能够在网络发生问题时以最快的速度找到问题根因和排除故障,从而将问题的影响降至最低。网络设备运行时产生的日志数据详细的记录了网络的运行情况,并且在网络发生问题时还会产生与问题相关的描述信息。通过分析日志来定位网络出现的问题,是运维过程中最常使用的手段之一。
尽管日志中蕴含着大量的有效信息,但是如何高效的实现日志分析却一直是运维领域面临的巨大挑战。挑战主要来自以下几个方面:(1)日志数据量过于庞大,通过人工分析的方法难以快速从海量数据中获取到有效信息。(2)日志的多重上报问题,即当一个网络问题发生时,网络设备的多个层面可能产生不同的告警日志,对日志分析工作带来极大干扰。(3)单一设备日志片面性问题,因为网络设备间存在连接关系,一台网络设备上发生的问题可能会传递到其他设备上引起衍生问题。在此情境下,大量设备会同时产生不同的日志,这些日志间又存在关联关系。如果在进行日志分析时没有选中问题最初发生的设备,将会浪费大量的时间或者分析出片面的结果,最终贻误问题排查时机。
为了解决以上问题,网络运维系统在传统方案中一般通过内置告警根因关联规则的方法实现告警的数量压缩与根因分析。但是静态的告警根因关联规则需要基于大量的知识经验进行总结,规则的复杂度及覆盖率受限于运维系统设计者的经验水平,并且专家经验无法覆盖随着网络技术的快速发展而不断产生的新的问题类型。因此传统的网络运维系统内置静态告警根因关联规则的方法已无法满足当前的运维需求。
在这种情况下,网络运维系统可通过AIOps理念,创新性的利用AI算法挖掘历史数据中隐藏的显式知识来总结日志关联规则,避免专家经验的局限性风险;利用知识图谱技术在全网范围推导网络问题根因及触发路径,解决静态规则自适应性不足的问题。通过以上改进,网络运维系统可有效提高日志数据关联分析的准确率和效率。
2 基于AI能力协助分析日志间的关系
日志关联分析的基本思想是按照时间滑动窗口分析窗口范围内的日志间是否存在关联关系,当存在多组关联关系时再进一步推导问题根因。因此我们主要是在发现日志间关联关系和推导问题根因这两个关键环节中通过引入AI算法来提升效率。
2.1 挖掘日志关联关系
存在关联关系的日志往往一起出现,因此日志间的关联关系其实已经显式的存在于历史数据中。但受限于数据量过大等问题,传统的日志关联关系主要还是通过专家经验由人为定义,而人为定义的过程既存在因思虑不周造成遗漏的风险,也难以跟上因网络技术不断发展而持续出现新的关联关系的节奏。如果我们能够先利用AI算法从海量的历史数据中挖掘出日志关联关系,专家经验只需对挖掘出的关联关系进行定义,就可以有效的解决定义日志关联关系过程中所面临的问题。
基于以上思路,网络运维系统开发团队可对大量的日志历史数据运行聚类算法生成日志关联矩阵,再通过设置阈值的方式过滤出有效的日志关联规则,最后结合专家经验对日志关联规则进行定义,即可实现日志关联关系定义过程的全面性和高效性。

图1. 日志关联关系定义过程
开发团队在AI算法的助力下,可以总结出“父子”、“衍生”、“频次”三种单设备日志关联关系和“推导”一种跨设备日志关联关系。
- 父子关系:事件A(父)的发生会引起事件B(子)的发生,那么我们认为A和B之间为父子关系,即A→B。例如端口shutdown操作导致所有子接口shutdown。
- 衍生关系:如果事件A和事件B两者间不存在因果关系,但A发生时如果伴随B发生可被整体认为是事件C,则A和B共同与C是衍生关系,即A+B→C。例如端口down后又up,衍生出端口震荡事件。
- 频次关系:如果事件A重复发生若干次后可被认为衍生出事件B,则A与B之间是频次关系,即A*n→B。例如多次登录失败后衍生出密码暴力破解事件。
- 推导关系:如果X设备上A事件的发生会引起Y设备的B事件的发生,则XA和YB是推导关系,即XA→YB。例如A设备的路由协议状态改变导致相邻设备的路由协议状态改变。
通过AI算法分析出的以上日志关联关系后,经过阈值筛选,再由运维专家对关联关系进行人工分析并定义,最终可形成产品内置的日志关联规则库。网络运维系统收集的日志如果可以匹配到关联规则库,则可对日志进行聚合,仅展示分析结果,从而有效的实现日志展示数量的压缩。
2.2 推导问题根因
当网络发生较严重问题时会同时触发较多的日志信息,即使经过了日志关联聚合后仍可能存在多条聚合结果,我们将日志聚合结果与检测到的网络问题相结合,利用AI算法推导问题根因。
在进行推导前,我们同样要对系统检测到的网络问题建立因果关系知识图谱。因为系统可检测到的网络问题类型数量固定,我们可以完全通过专家经验的方式定义网络问题知识图谱。
之后我们便可以根据网元的属性建立一棵网元对象树,网络运维系统将检测到的网络问题和接收到的日志信息按照其所属对象共同挂载到树上对应的节点上,生成根因分析树。例如下面的形式:
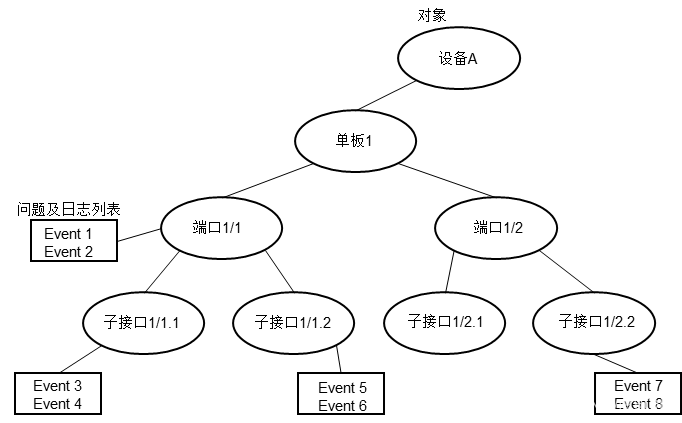
图2. 根因分析树示意图
基于以上的根因分析树,我们便可以进行根因分析推导。例如分析问题A的根因,大致推导过程如下:
-
创建有向图X0={A}。在A的前后时间窗口内,查找所有与X0相关的问题或日志并记录,得到X1。
-
再次在A的前后时间窗口内,查找所有与X1中任何元素相关的问题或日志并记录,得到X2。
-
重复以上过程,直至不再有新的信息被添加到Xn中,即Xn=Xn+1。
-
在Xn中,以A作为终点,按照所有可能路径倒推,每一个起点即为一种可能根因。
下面以BFD Session中断问题为例,推导过程可能如下:
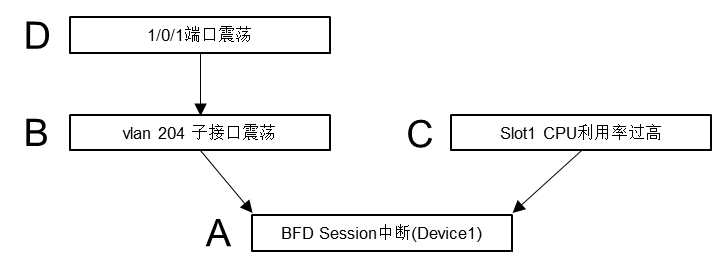
图3. BFD Session中断推导过程示意图 -
X0={A}
-
查找所有与X0相关的问题或日志,发现存在B和C,则X1={B→A,C→A}
-
查找所有与X1相关的问题或日志,发现存在D,则X2={ B→A,C→A,D→B}
-
查找所有与X2相关的问题或日志,未发现新的数据,则X3=X2,结束查找。
-
按照路径倒推,以A为终点的路径起点分别是D和C,那么该问的可能根因即为(1)物理端口1/0/1端口震荡;(2)Slot 1 CPU利用率过高。
3 日志数据关联分析实践
基于以上介绍的方法,网络运维系统内置的日志关联规则库可随着版本迭代而不断丰富,为日志压缩展示提供高质量的规则依据,可以有效协助网络管理员减少日志展示条数,提高日志分析效率。在网络问题分析时,网络运维系统基于知识图谱的AI算法对于已发现的问题可触发根因推导过程,提供疑似根因分析,显著降低运维人员的分析成本,辅助运维人员尽快规避和修复问题,从而尽可能的降低网络问题所带来的损失。

















 1223
1223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









