







一、哈希表概述
1. 前言
- 假设我们现在有一个数组,假设有个数组 [9, 5, 2, 7, 3, 6, 8] ,需要判断 3 这个元素是否存在,两种方法:
- (1) 使用搜索树存储这个集合,然后查找 3 是否存在:二分查找。
- (2) 可以创建一个 boolean 数组,这个数组的长度取决于原集合最大值是谁。
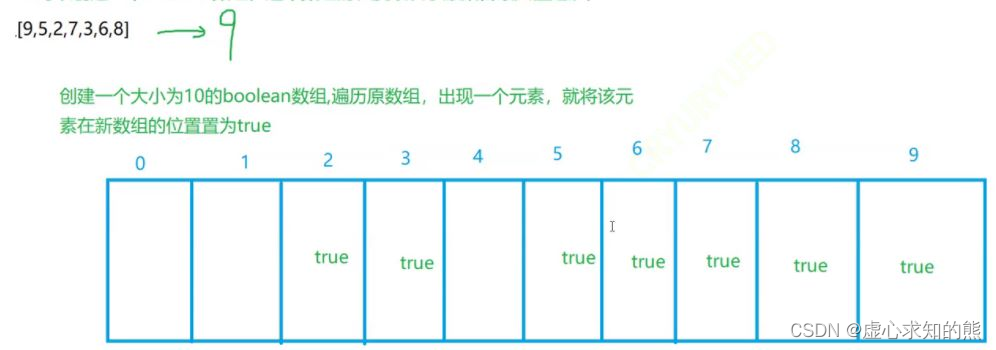
- 有了这个新的 boolean 数组后,要查询原数组中 3 是否存在,只需看hash[3]是否为 true 。
2. 基本概念
- 散列表(Hash table,也叫哈希表),是根据关键码值 (Key value) 而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做哈希函数(散列函数),存放记录的数组叫做哈希表(散列)。
- 给定表 M ,存在函数 f(key) ,对任意给定的关键字值 key ,代入函数后若能得到包含该关键字的记录在表中的地址,则称表 M 为哈希 (Hash) 表,函数 f(key) 为哈希 (Hash) 函数。
- 若对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数,这就是使关键字经过散列函数得到一个“随机的地址”,从而减少冲突。
3. 哈希表思想
- 哈希表的关键思想是使用哈希函数,将键 key 和值 value 映射到对应表的某个区块中。可以将算法思想分为两个部分:
- (1) 向哈希表中插入一个关键字:哈希函数决定该关键字的对应值应该存放到表中的哪个区块,并将对应值存放到该区块中。
- (2) 在哈希表中搜索一个关键字:使用相同的哈希函数从哈希表中查找对应的区块,并在特定的区块搜索该关键字对应的值。
4. 哈希表思想具体实现见例题模拟散列表
5. 哈希函数
- 哈希函数:将哈希表中元素的关键键值映射为元素存储位置的函数。一般来说,哈希函数会满足以下几个条件:
- (1) 哈希函数应该易于计算,并且尽量使计算出来的索引值均匀分布,这能减少哈希冲突。
- (2) 哈希函数计算得到的哈希值是一个固定长度的输出值。
- (3) 如果 Hash(key1) 不等于 Hash(key2),那么 key1、key2 一定不相等。
- (4)如果 Hash(key1) 等于 Hash(key2),那么 key1、key2 可能相等,也可能不相等。
- 在哈希表的实际应用中,关键字的类型除了数字类型,还有可能是字符串类型、浮点数类型、大整数类型,甚至还有可能是几种类型的组合。一般会将各种类型的关键字先转换为整数类型,再通过哈希函数,将其映射到哈希表中。
6. 哈希冲突
- 对不同的关键字可能得到同一散列地址,即 k1 != k2 ,而 f(k1) == f(k2) ,这种现象称为哈希冲突。
二、 哈希表常用方法
- 散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快地定位 。
- 实际工作中需视不同的情况采用不同的哈希函数,通常考虑的因素有:
- (1) 计算哈希函数所需时间 。
- (2) 关键字的长度 。
- (3) 哈希表的大小 。
- (4) 关键字的分布情况 。
- (5) 记录的查找频率 。
1. 直接寻址法
- 取关键字或关键字的某个线性函数值为散列地址。即 H(key) = key 或 H(key) = a * key + b,其中 a 和 b 为常数(这种散列函数叫做自身函数)。若其中 H(key) 中已经有值了,就往下一个找,直到 H(key) 中没有值了,就放进去。
2. 数字分析法
- 分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
3. 平方取中法
- 当无法确定关键字中哪几位分布较均匀时,可以先求出关键字的平方值,然后按需要取平方值的中间几位作为哈希地址。这是因为:平方后中间几位和关键字中每一位都相关,故不同关键字会以较高的概率产生不同的哈希地址。
4. 折叠法
- 将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。数位叠加可以有移位叠加和间界叠加两种方法。移位叠加是将分割后的每一部分的最低位对齐,然后相加;间界叠加是从一端向另一端沿分割界来回折叠,然后对齐相加。
5. 随机数法
- 选择一随机函数,取关键字的随机值作为散列地址,即 H(key) = random(key) ,其中 random 为随机函数,通常用于关键字长度不等的场合。
6. 除留余数法
- 取关键字被某个不大于散列表表长 m 的数 p 除后所得的余数为散列地址。即 H(key) = key mod p ,p ≤ m 。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对 p 的选择很重要,一般取素数或 m ,若 p 选的不好,容易产生同义词(具有相同函数值的关键字对该散列函数来说称做同义词)。
四、哈希表例题——模拟散列表
题目描述
维护一个集合,支持如下几种操作:
I x,插入一个数 x;Q x,询问数 x 是否在集合中出现过;
现在要进行 N 次操作,对于每个询问操作输出对应的结果。
输入格式
第一行包含整数 N,表示操作数量。
接下来 N 行,每行包含一个操作指令,操作指令为 I x,Q x 中的一种。
输出格式
对于每个询问指令 Q x,输出一个询问结果,如果 x 在集合中出现过,则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1 ≤ N ≤ 1e5
−1e9 ≤ x ≤ 1e9
输入样例
5
I 1
I 2
I 3
Q 2
Q 5
输出样例
Yes
No
(一) 具体实现——拉链法
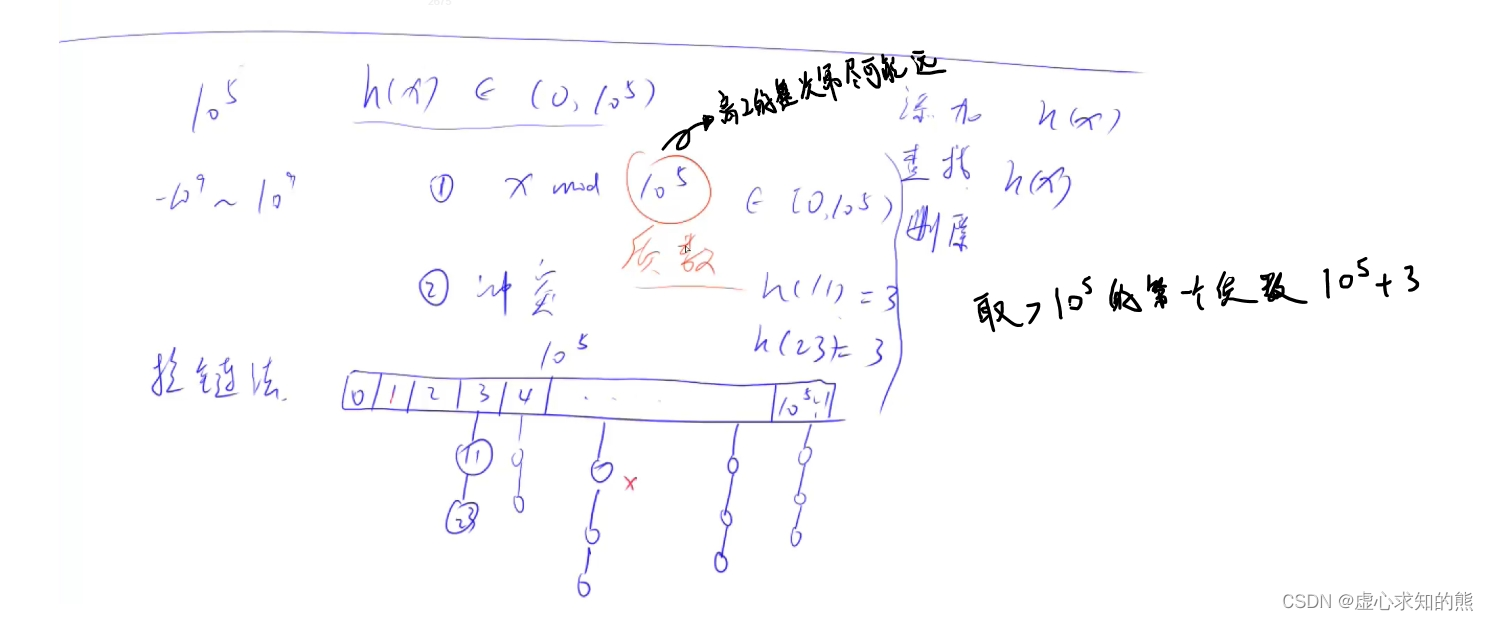
1. 实现思路
- 用一个一维数组,来存放所有的哈希值。每一数字下的链就是一个单链表。
2. 代码注解
- h[];是哈希函数的一维数组。
- e[];是链表中存的值。
- ne[];是指针存的指向的地址。
- idx;是当前指针。
- int k = (x % N + N) % N;对负数的出来,k 是哈希值。
- e[idx] = x;ne[idx] = h[k];h[k] = idx;idx++; 如果不同单链表的 idx 都是从 0 开始单独计数,那么不同链表之间可能会产生冲突。
- 这里的模型是这样的:e[] 和 ne[] 相当于一个大池子,里面是单链表中的节点,会被所有单点表共用,idx 相当于挨个分配池子中的节点的指针。比如如果第 0 个节点被分配给了第一个单链表,那么所有单链表就只能从下一个节点开始分配,所以所有单链表需要共用一个 idx 。
3. 实现代码
#include <bits/stdc++.h>
using namespace std;
const int N = 100003;
int h[N], e[N], ne[N], idx;
void insert(int x)
{
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx;
idx++;
}
bool find(int x)
{
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i])
{
if (e[i] == x)
{
return true;
}
}
return false;
}
int main()
{
int n;
cin >> n;
memset(h, -1, sizeof h);
while (n -- )
{
char op[2];
int x;
cin >> op >> x;
if (*op == 'I')
{
insert(x);
}
else
{
if (find(x))
{
puts("Yes");
}
else
{
puts("No");
}
}
}
system("pause");
return 0;
}
(二) 具体实现——开放寻址法
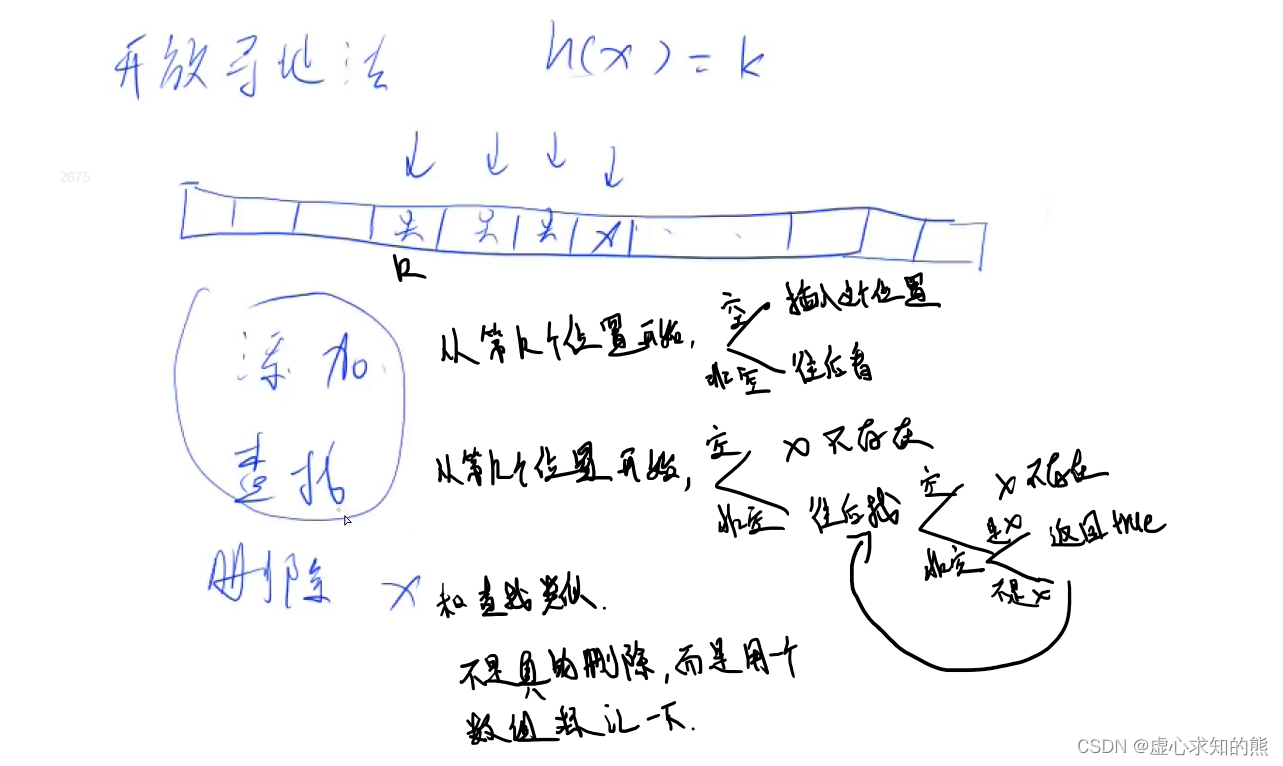
1. 实现思路
2. 代码注解
- memset(h, 0x3f, sizeof h) ;是把所有元素设置成无穷大。第一个参数是一个指针,即要进行初始化的首地址;第二个参数是初始化值,注意,并不是直接把这个值赋给一个数组单元(对int来说不是这样);第三个参数是要初始化首地址后多少个字节。
- 使用 0x3f3f3f3f 的十进制是1061109567,也就是 1e9 级别的(和 0x7fffffff 一个数量级),而一般场合下的数据都是小于 1e9 的,所以它可以作为无穷大使用而不致出现数据大于无穷大的情形。
- const int N = 200003;开放寻找,会出现冲突的情况,一般会开成两倍的空间。
3. 实现代码
#include <bits/stdc++.h>
using namespace std;
const int N = 200003, null = 0x3f3f3f3f;
int h[N];
int find(int x)
{
int t = (x % N + N) % N;
while (h[t] != null && h[t] != x)
{
t ++ ;
if (t == N)
{
t = 0;
}
}
return t;
}
int main()
{
memset(h, 0x3f, sizeof h);
int n;
cin>>n;
while (n -- )
{
char op[2];
int x;
cin>>op>>x;
if (*op == 'I')
{
h[find(x)] = x;
}
else
{
if (h[find(x)] == null)
{
puts("No");
}
else
{
puts("Yes");
}
}
}
system("pause");
return 0;
}
(三) 具体实现—— STL
1. unordered_map 讲解
- unordered_map 是一种关联容器,存储基于键值和映射组成的元素,即 key-value 。允许基于键快速查找元素。在 unordered_map 中,键值唯一标识元素,映射的值是一个与该对象关联的内容的对象。
- unordered_map 的无序体现在内部存储结构为哈希表,以便通过键值快速访问元素。
- 有序的关联容器为 map , map 的有序体现在内部存储结构为红黑树,存储时元素自动按照从小到大的顺序排列。
2. unordered_map 属性
- 关联性:关联容器中的元素由他们的键引用,而不是由他们在容器中的绝对位置引用。
- 无序性:无序容器使用散列表来组织它们的元素,散列表允许通过它们的键快速访问元素。
- Map 映射:每个元素将一个键key与一个映射值value相关联;键意味着标识其主要内容是映射值的元素。
- Key 的唯一性:在容器中没有两个元素有相同的 key 。
- Allocator-aware:容器使用一个分配器对象来动态地处理它的存储需求。
3. 模板参数
template < class Key, // unordered_map::key_type
class T, // unordered_map::mapped_type
class Hash = hash<Key>, // unordered_map::hasher
class Pred = equal_to<Key>, // unordered_map::key_equal
class Alloc = allocator< pair<const Key,T> > // unordered_map::allocator_type
> class unordered_map;
- Key:键值的类型。unordered_map 中的每个元素都是由其键值唯一标识的。
- T:映射值的类型。unordered_map 中的每个元素都用来存储一些数据作为其映射值。
- Hash:一种一元函数对象类型,它接受一个 key 类型的对象作为参数,并根据该对象返回 size_t 类型的唯一值。这可以是一个实现函数调用操作符的类,也可以是一个指向函数的指针(参见构造函数)。默认为 hash。
- Pred:接受两个键类型参数并返回 bool 类型的二进制谓词。表达式 pred (a, b) , pred 是这种类型的一个对象,a 和 b 是键值,返回 true ,如果是应考虑相当于 b 。这可以是一个类实现一个函数调用操作符或指向函数的指针 ( 见构造函数为例 ) 。这默认为 equal_to ,它返回与应用相等操作符 ( a == b ) 相同的结果。
- Allloc:用于定义存储分配模型的 allocator 对象的类型。默认情况下,使用 allocator 类模板,它定义了最简单的内存分配模型,并且与值无关。
4. 实现代码
#include <bits/stdc++.h>
using namespace std;
int n;
int main()
{
unordered_map<int,int> mp;
cin >> n;
while(n --)
{
string op;
int x;
cin >> op >> x;
if(op == "I")
{
mp[x]++;
}
else
{
if(mp[x] > 0)
{
puts("Yes");
}
else
{
puts("No");
}
}
}
system("pause");
return 0;
}
五、哈希表例题——字符串哈希
题目描述
给定一个长度为 n 的字符串,再给定 m 个询问,每个询问包含四个整数 l1,r1,l2,r2,请你判断 [l1,r1] 和 [l2,r2] 这两个区间所包含的字符串子串是否完全相同。
字符串中只包含大小写英文字母和数字。
输入格式
第一行包含整数 n 和 m,表示字符串长度和询问次数。
第二行包含一个长度为 n 的字符串,字符串中只包含大小写英文字母和数字。
接下来 m 行,每行包含四个整数 l1,r1,l2,r2,表示一次询问所涉及的两个区间。
注意,字符串的位置从 1 开始编号。
输出格式
对于每个询问输出一个结果,如果两个字符串子串完全相同则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1 ≤ n,m ≤ 1e5
输入样例
8 3
aabbaabb
1 3 5 7
1 3 6 8
1 2 1 2
输出样例
Yes
No
Yes
具体实现
1. 实现思路
- 字符串前缀哈希法。
- 例如:有一个字符串 str = ”ABCABCDEYXCACWING" 。
- h[0] = 0 。
- h[1] = “A” 的哈希值 。
- h[2] = “AB” 的哈希值 。
- h[3] = “ABC” 的哈希值 。
- h[4] = “ABCA” 的哈希值 。
- 依此类推。
- 当我们想求字母 “ABCD" 的哈希值时,首先他们都是 p 进制的数,一共有四个字母,就看做有四位。第一位是 ”A“ 看成数字 1 ,第二位是 ”B“ 看成数字 2 ,第三位是 ”C“ 看成数字 3 ,第四位是 ”D“ 看成数字 4 。
- 此时,字符串 “ABCD" 就可以看出 p 进制的 (1 2 3 4)p ,对应的十进制的数变为 1 * p * p * p + 2 * p * p + 3 * p +4 ,再对其 mod Q 。
- 通过此方法,便可以将字母字符串映射到 0 到 Q-1 的数字。
- 一般情况下不可以映射成 0 。
- 当 p =131 或 13331 ,Q 是 2 的 64 次方是,在一般情况下,不会发生哈希冲突。在这里,直接使用 unsigned long long 类型存储这个哈希值。

- 假设,我们知道了从 1 到 h[l-1] 和从 1 到 h[r] 的哈希值,现在需要求 h[l] 到 h[r] 的哈希值。
- 左边是高位,右边是低位。
- h[l-1] 乘上 p 的 r-l+1 次方,将 h[l] 向右移动若干位,使其与 h[r] 对齐。再使得 h[r] 减去 h[l-1] 乘上 p 的 r-l+1 次方,便得到了这一段的哈希值。如下图实例:
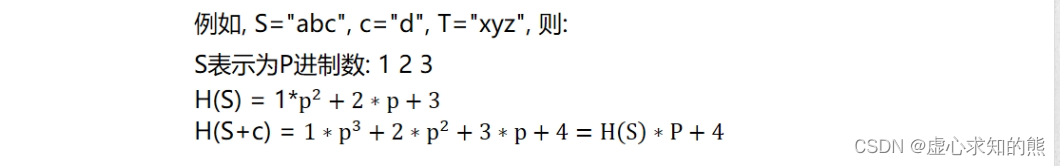
2. 代码注解
- h[]; 存放字符串的前缀值。
- p[]; 存放各个位数的相应权值。
- h[r]-h[l-1]*p[r-l+1]; 这步其实是将h[l-1]左移,其目的事实上是为了将 h[l-1] 的高位与 h[r] 相对齐从而才可以完成计算。
- p[0]=1; 最开始的权值必须赋值为 1 。
- p[i]=p[i-1]*P; 计算每个位上的相应权值。
- h[i]=h[i-1]*P+str[i]; 计算字符串前缀值,最新加入的数的权值为 p 的 0 次 所以直接加上 str[i] 即可。
3. 实现代码
#include <bits/stdc++.h>
using namespace std;
typedef unsigned long long ULL;
const int N = 100010;
const int P = 131;
int n, m;
char str[N];
ULL h[N], p[N];
ULL get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
int main()
{
cin>>n>>m;
cin>>str+1;
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * P + str[i];
p[i] = p[i - 1] * P;
}
while (m -- )
{
int l1, r1, l2, r2;
cin>>l1>>r1>>l2>>r2;
if (get(l1, r1) == get(l2, r2))
{
puts("Yes");
}
else
{
puts("No");
}
}
system("pause");
return 0;
}
















 4121
4121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











