






1)咱们前面学习过的查找,都是要进行比较的,他的最快的时间复杂度就是O(logN)
2)不经过任何比较,一次直接从表中得到得到要搜索的元素,如果构造一种数据结构,通过函数是元素的存储位置和他的关键码中之间建立映射的关系,那么在查找过程中就很容易得到元素(链表的长度不会很长,控制在长度范围内)
3)增删查改的时间复杂度是O(1)
1.Hashmap<String,String> map=new HashMap<>(),此时的数组容量为0,当我们第一次put的时候,容量才真的有了,默认容量是16;
2 数组的最大长度是2^30;
3 默认的负载因子为0.75;
4 变成红黑树的前提是当前数组的大小超过64,链表长度超过8;

1)(1-9的下标)1,4,14,24,9查找成功的平均长度是:1+1+2+3+4+1/6=2;
2)此时我们想再插入一个元素,例如插入14,但是14%10=4,我们要放到4号下标,下面4号位置已经有数据了
3)哈希冲突或哈希碰撞:对于两个关键字的A和B(A!=B),即不同的关键字通过相同的哈希函数计算出相同的哈希地址,也就是找到了在数组中相同的位置,之前这个位置已经有数据了,又来了数据通过相同的哈希函数也计算到了这个位置
4)咱们的哈希表的底层的数组的容量往往是小于实际要进行存储的关键字的数量的,这就导致一个问题,冲突的发生是必然的
1)负载因子的定义:负载因子越大,冲突性就越高,当负载因子超过0.75时,那就扩容
2)当我们填充的元素个数增加的时候,负载因子会不断变大,我们此时想要负载因子变小只能增加散列表的长度,每当我们向散列表中增加元素的时候,我们都要检查负载因子的大小,一旦负载因子超过了0.75,就需要进行扩容
3)负载因子越大,表明填入表中的元素变多
一个节点有三个域,Key,Value,Next(下一个结点的地址)
1)当进行put操作的时候,根据传过来的Key来进行计算数组的下标,来进行找到元素所存放的位置
2)此时我们的数组的index位置是一个地址,用来存放一个链表,此时我们还需要进行遍历这个链表看看当前的链表中有没有Key值和我们当前的Key值重复,如果重复,我们就更新val的值
3)新创建出一个Node,进行头插法或者尾插法,尾差法就是遍历这个数组,找到尾巴,把节点插入进去(还要注意区分是不是第一次插入和不是第一次插入),但是头插法不用进行区分
4)我们进行插入元素成功了,还要进行,判断哈希表是否到达了负载因子,如果到达了那么就需要进行扩容,我们就需要新创建出一个数组为原来的二倍,数组中的每一个位置进行重新哈希;
4.1)扩容和重新哈希都是尾插法:
public class MyHashMap{ public ListNode[] nodes; public double load; public int usedSize; public MyHashMap(int count,double load){ this.load=load; this.nodes=new ListNode[count]; this.usedSize=0; } public void put(int key,String value){ //0.先进行判断负载因子是否已经超过了0.75 if(judgeLoad(usedSize)>=0.75){ ReSize(); } //1.先计算这个数字应该存放到数组的哪一个位置 int index=key%nodes.length; if(nodes[index]==null){ //2.如果哈希到的数组位置没有节点,这个nodes[index]==null,就直接设置该节点 ListNode newNode=new ListNode(key,value); nodes[index]=newNode; }else{ //3.如果哈希到的数组的下面的链表已经存在着该节点了,那么直接更新节点的value值,然后直接进行返回 ListNode current=nodes[index]; while(current.next!=null){ if(current.key==key){ current.value=value; return; } current=current.next; } //4.将这个节点插入到数组的位置的链表的尾巴节点 ListNode newNode=new ListNode(key,value); current.next=newNode; } //5.更新元素个数 usedSize++; } private void ReSize() { //1.首先以二倍形式进行扩容操作 ListNode[] newNodes=new ListNode[2* nodes.length]; //2.遍历原来的每一个数组中的每一条链表都进行重新哈希 for(int i=0;i<nodes.length;i++){ //3.遍历数组中的每一个链表 ListNode current=nodes[i]; while(current!=null) { ListNode CurNext = current.next; int newIndex = current.key % newNodes.length; ListNode newCurrent = newNodes[newIndex]; if(newCurrent == null) { newNodes[newIndex] = current; current.next = null; }else{ //找到新插入位置的尾巴节点 while (newCurrent.next != null) { newCurrent = newCurrent.next; } newCurrent.next = current; current.next = null; } current = CurNext; } } this.nodes=newNodes; } private double judgeLoad(int usedSize) { return usedSize*(1.0)/ nodes.length; } }4.2)扩容和哈希都是头插法:
4.3)改成泛型版本:
package DemoData; public class MyHashMap<K,V>{ public ListNode[] nodes; public double load; public int usedSize; public MyHashMap(int count,double load){ this.load=load; this.nodes=new ListNode[count]; this.usedSize=0; } public void put(K key,V value){ //0.先进行判断负载因子是否已经超过了0.75 if(judgeLoad(usedSize)>=0.75){ ReSize(); } //1.先计算这个数字应该存放到数组的哪一个位置 int hashcode=key.hashCode(); int index=hashcode%nodes.length; if(nodes[index]==null){ //2.如果哈希到的数组位置没有节点,这个nodes[index]==null,就直接设置该节点 ListNode<K,V> newNode=new ListNode<>(key,value); nodes[index]=newNode; }else{ //3.如果哈希到的数组的下面的链表已经存在着该节点了,那么直接更新节点的value值,然后直接进行返回 ListNode<K,V> current=nodes[index]; while(current!=null){ if(current.key.equals(key)){ current.value=value; return; } current=current.next; } //4.进行头插法 ListNode<K,V> newNode=new ListNode<>(key,value); newNode.next=nodes[index]; nodes[index]=newNode; } //5.更新元素个数 usedSize++; } private void ReSize() { //1.首先以二倍形式进行扩容操作 ListNode[] newNodes=new ListNode[2* nodes.length]; //2.遍历原来的每一个数组中的每一条链表都进行重新哈希 for(int i=0;i<nodes.length;i++){ //3.遍历数组中的每一个链表 ListNode<K,V> current=nodes[i]; while(current!=null) { ListNode<K,V> CurNext = current.next; int hashcode=current.key.hashCode(); int newIndex = hashcode% newNodes.length; ListNode<K,V> newCurrent = newNodes[newIndex]; if(newCurrent == null) { newNodes[newIndex] = current; current.next = null; }else{ //头插法扩容 current.next=newNodes[newIndex]; newNodes[newIndex]=current; } current = CurNext; } } this.nodes=newNodes; System.out.println(nodes.length); } private double judgeLoad(int usedSize) { return usedSize*(1.0)/ nodes.length; } }


1)我们在向HashMap中写入自定义类型的时候,一定要针对这个自定义类型重写hashCode和equals方法,当HashMap<Person, String> map=new HashMap<>();希望把id相同的Person放到哈希表的相同位置;
2)我们是用hashcode来确定这个k的位置上,使用equals比较哪一个k和我们当前这个k是相同的
package Demo; import java.util.Objects; class Person{ public int age; public String name; public Person(String name,int age){ this.name=name; this.age=age; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Person person = (Person) o; return age == person.age && Objects.equals(name, person.name); } @Override public int hashCode() { return Objects.hash(age, name); } } public class HelloWorld{ public static void main(String[] args) { Person person1=new Person("李佳伟",10); Person person2=new Person("李佳伟",10); //我们认为person1和person2是同一个人,应该放在数组的同一个位置 按理说他们得到的hashcode%array.length应该是相同的,但是运行的时候 //发现他们的哈希值不一样,但是我们重写hashcode之后,得到的hashcode是相同的 这样我们就可以认为两个逻辑一样的人,一定会存放到同一个位置 //当自定义类型作为Key值的时候,一定要重写我们的hashcode,否则就会出现本以上两个一样的人 最终你的代码在逻辑上认为他不是一个人了 System.out.println(person1.hashCode()); System.out.println(person2.hashCode()); } }
package Demo; import java.util.Objects; class Person{ public int age; public String name; public Person(String name,int age){ this.name=name; this.age=age; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Person person = (Person) o; return age == person.age && Objects.equals(name, person.name); } @Override public int hashCode() { return Objects.hash(age, name); } } class MyHashMap<K,V>{ public int UsedSize=0; public Node<K,V>[] array=(Node<K, V>[])new Node[10]; static class Node<K,V>{ public K k; public V v; public Node next; public Node(K k,V v) { this.k=k; this.v=v; } } public void put(K k,V v) { int index=k.hashCode()%array.length;//得到这个值对应的数组下标,必须重写hashcode //否则两个逻辑上相同的值会得到不同的哈希值,就会被放到数组种不同的位置 Node current=array[index]; while(current!=null){ if(current.k.equals(k))//不能使用== //现在k是一个引用类型,使用==默认比较的是地址,所以我们使用equals,但是直接使用equals比较的还是两个引用的地址《 //所以我们要重写equals方法,来进行比较他们具体的内容 { current.v=v; return; } } //我们是头插法来进行插入元素 Node<K,V> node=new Node<>(k,v); node.next=array[index]; array[index]=node; UsedSize++; //判断是否负载因子超过了0.75,如果超过,就进行扩容 if(UsedSize/array.length>0.75){ CreateBigSizeArray(array); } } private void CreateBigSizeArray(Node<K,V>[] array) { Node[] newArray=new Node[2* array.length]; for(int i=0;i<array.length;i++){//遍历每一个哈希桶,也就是说遍历数组的每一个元素 Node current=array[i];//遍历数组下的每一个链表 while(current!=null){ Node child=current.next; int index=current.v.hashCode()%newArray.length; current.next=array[index]; array[index]=current; current=child; } } } } public class HelloWorld{ public static void main(String[] args) { MyHashMap<Person,String> map=new MyHashMap<>(); map.put(new Person("李佳伟",90),"bit"); map.put(new Person("李嘉欣",100),"kig"); System.out.println(map); } }
1)public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>,Cloneable,Serializable(是可序列化的)
AbstractMap是一个普通的抽象类,Serializable是可序列化的,说明可以把一个对象变成字符串
2)static final int DEFAULT_INITIAL_CAPACITY=1<<4,说明他的默认容量是16,必须是2的次幂
3)static final int MAXIMUM_CAPACITY=1<<30,说明他的最大长度是2^30;
4)static final float DEFAUIT_LOAD_FACTOR=0.75f,默认的负载因子
5)static final TREEINF_THRESHOLD=8,这是树化的条件(链表长度超过8)
6)static final int UNTREEIFY_THRESHOLD=6,不树化
这是桶的链表还原阈值:即红黑树转化成链表的值,当进行扩容之后,此时的HashMap的值会进行重新计算,在进行重新计算存储位置后当原有的红黑树数量小于6之后,会将红黑树转化成链表
7)static final int min_treeinfy_capacity=64
8)Node在哈希表中是一个内部类
9)HashMap一共有三个构造方法
1))无参构造方法
2))传输一个初始容量
3))传输一个初始容量和指定负载因子
位运算算效率高
public V put(K key,V value)
{
return putVal(hash(key),key,value,false,true);//第四个参数表示是老元素的值不会保留,会进行覆盖
}
static final int hash(Object Key)
{
int h;
return (key==null?0:(h==key.hashcode())^(h>>>16);
//得到的哈希地址已经是32位了,为了混合哈希值的高位和低位,高半区和低半区做异或,混合原始哈希码的高位和地位,增加低位的随机性,掺杂了高位的部分特征,混合之后的低位核心目的是为了让hash值的散列度更高,尽可能减少hash表的hash冲突,从而提升数据查找的性能,并且混合后的值也保持了高位的特征
}
这个哈希函数的作用就是根据key的哈希值来进行计算这个元素在数组中的位置,求解这个哈希值的过程就是哈希算法,异或就是相同为0,不同为1
1)V get(object k)根据K查找对应的value
2)V getOrDefault(Object K,V defaultValue)根据K查找对应的V,查不到就用我们制定的默认值来进行代替
3) V put(K k,V v)存放键值对
4)boolean containsKey(Object K)
5)boolean containsValue(Object V)判断是否存在Key和Value
6)int size()返回键值对的数量
7)boolean isEmpty()判断是否为空
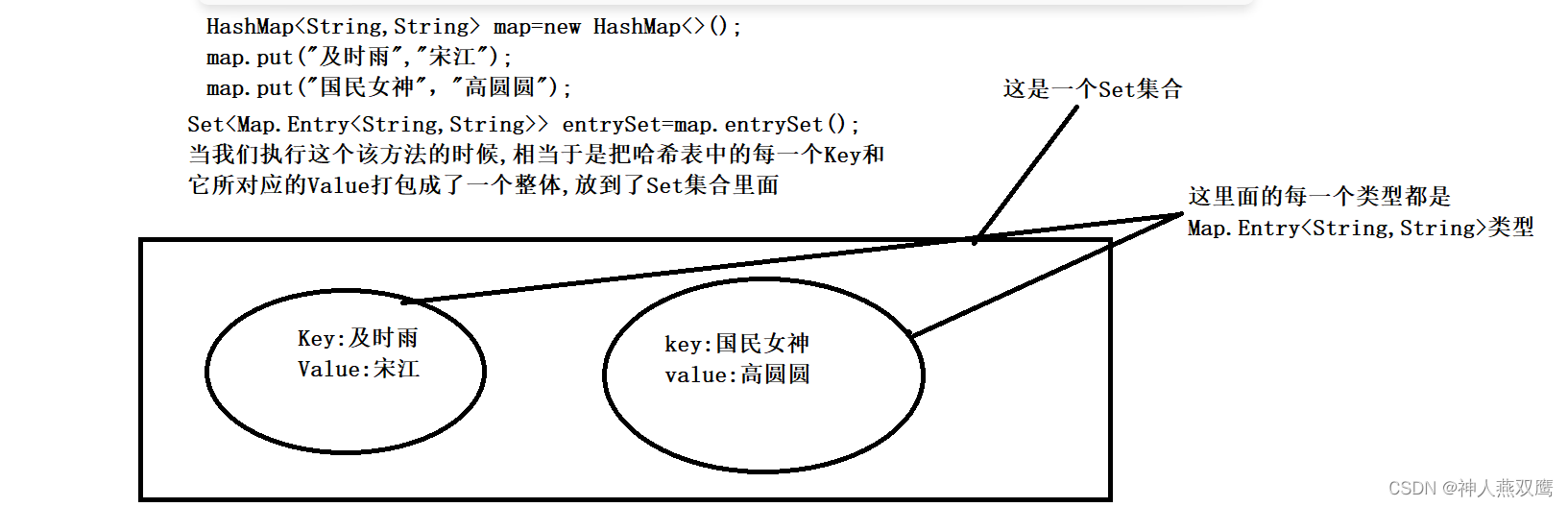
8)Set<Map.Entry> entrySet();把他转化成Set集合
Map<String,String> map=new HashMap<>(); map.put("及时雨","宋江"); map.put("国民女神","高圆圆"); Set<Map.Entry<String,String>> set=map.entrySet(); //1)当我们调用这个方法之后,会把哈希表中的每一对key和value包装成一个整体,相当于把两个元素放到一个大盒子里面,变成一个元素 //2)然后内存就会把每一个大盒子放到Set里面,这个大盒子就是Map.Entry(String,String)类型 for(Map.Entry<String,String> sb:set) { System.out.println(sb.getKey()); System.out.println(sb.getValue()); }
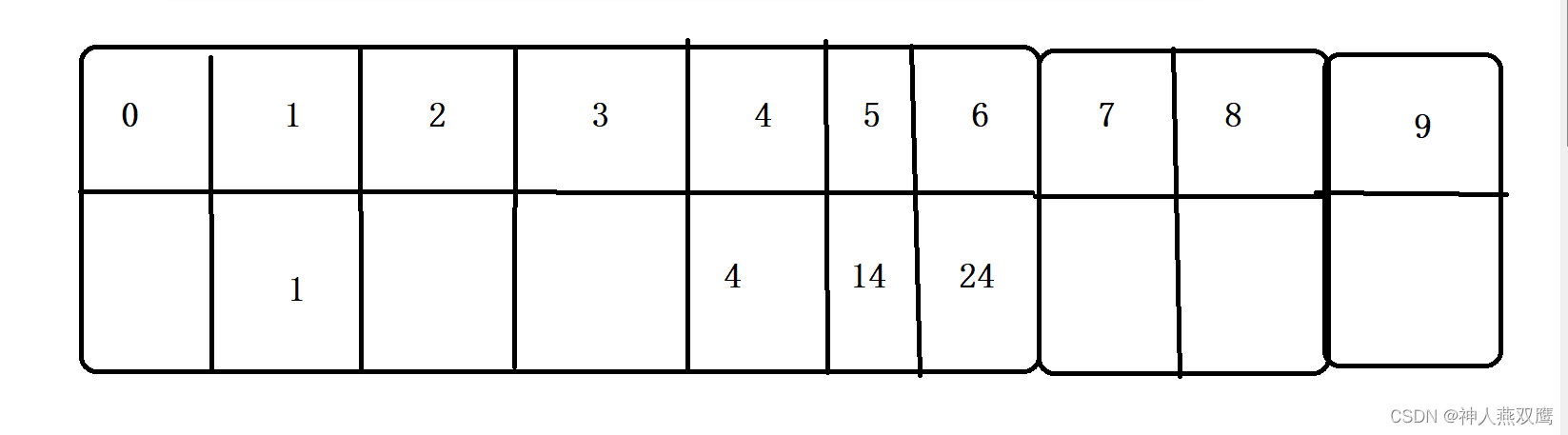
已经知道哈希函数hash(Key)=Key%array.length,请您求一下查找成功的平均长度和查找不成功的平均长度
假设现在上面的数据是以线性探测的方式来进行存放的,现在让你求:
现在找1:直接就能找到----->次数是1
现在找4:直接就可以找到---->次数是1
现在找14:先得到4的下标,发现不是14向后找,这里面用了两次
现在找24::先得到4的下标,发现不是24向后找,这里面用了3次
现在查找9:找9只是查找了1次
总共找的次数:1+1+2+3+1=8
1)查找成功的平均长度:查找成功的次数/有效数据的长度(一共数组里面有几个数)=8/5;
2)查找不成功的平均长度:
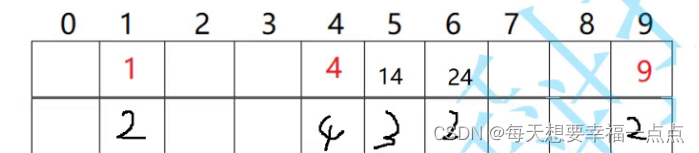
已经存在的数据:查找的这个数位置开始前向后走几步到空格?2+4+3+2+2=13
没有存在的数据就是1;
比如说现在查找1不成功的次数,先查找到了1
再来进行查看从查找到1开始走几步到了空格
0-->1
1--->2
2--->1
3---->1
4---->4
14---->3
24----->2
7------>1
8------>1
9------>2
18/10=1.8;
查找不成功的次数/数组的总长度















 1763
1763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









