






1. 什么是范数?
“范数”(Norm)是一个用于衡量向量大小的数学概念。在线性代数中,范数是对向量空间中的向量进行度量的一种方式,通常表示为 ||x||。不同的范数定义了不同的向量度量方法。
2. 常见的范数
l p lp lp-范数的定义
- 根据
l
p
lp
lp -范数的定义,当
p=0,我们就有了 l 0 l0 l0 -范数,即
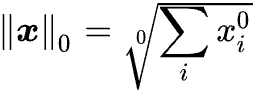
表示向量 x中非0元素的个数。
- 当
p=1, 为L1范数(曼哈顿范数):
- 表示为
||x||₁。 - 计算方式是将向量
x中所有元素的绝对值相加。 - 公式:
||x||₁ = |x₁| + |x₂| + ... + |xn|,即

3. 当 p=2, 为L2 范数(欧几里德范数):
- 表示为
||x||₂。 - 计算方式是将向量
x中所有元素的平方和的平方根。 - 公式:
||x||₂ = √(x₁² + x₂² + ... + xn²),即

4. 为方便统一,一般将任意向量 x 的
l
p
lp
lp-范数定义为:
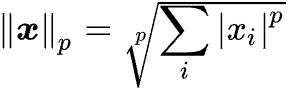
这些范数在不同的应用中有不同的用途。在机器学习和优化问题中,范数经常用于正则化项,帮助控制模型的复杂性或防止过拟合。不同的范数在正则化中起到不同的效果,例如 L1 正则化倾向于产生稀疏解,而 L2 正则化倾向于产生较小的权重。
3. l 1 l1 l1-范数与正则化:稀疏解
a. 什么是正则化?
机器学习中的一个核心问题是设计不仅在训练数据上表现好,并且能在新输入上泛化好的算法。在机器学习中,许多策略显式地被设计来减少测试误差(可能会以增大训练误差为代价),也就是防止过拟合的策略。这些策略被统称为正则化。
-
我们假设损失函数为:

-
正则化项为
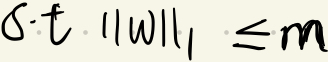
其中
s.t表示其受约束于m值
加入正则项之后我们要做的事情就是在满足惩罚项约束的情况下,使得损失项的值最小
b. 为什么需要正则化?
原因上述也有说到,这里我们形象地进行解释。首先我们先解释一下什么是过拟合:假设我们正在训练一个机器学习模型,我们想让它学会一个二分类问题,将类似下述的字分成两类:
把 拔 挤 拉 拟 | 们 俩 仨 付 仕
在我的期待里,我希望这个模型可以根据字的偏旁进行分类,比如提手旁的分为第一类,单人旁的分为第二类。
那么当我输入扪的时候,我希望它可以被分为第一类。但是现实的情况很可能是这样,由于模型的学习能力太强了,把每个字的每一笔都学习很好,所以当我给出扪的时候,我们可爱的模型可能觉得它更像们,于是就把它分到第二类去啦。
上述的情况就是模型过拟合啦!!那么正则化的作用就是在损失函数中加入一个正则化项,让模型变得笨一点,在训练的过程中,不要标记那么多的特征,只需要把重要的特征标记就好了。如下所示,我们希望模型记住提手旁就好了

为了实现上述目标,我们首先要使得与提手旁相关的权重值不为0,其他不相关的神经元的权重最好为0好使得神经元的值为0。
这里还要进一步解释仅仅靠损失函数是做不到的,因为这样会使得模型学习得很好,每个特征都不会为0.
c. 什么是稀疏解?
使得上述无关特征为0,相关特征不为0的解。在机器学习中,是一个稀疏的向量解,如下所示:

d. 为什么 l 1 l1 l1-范数作为正则项具有稀疏性?
-
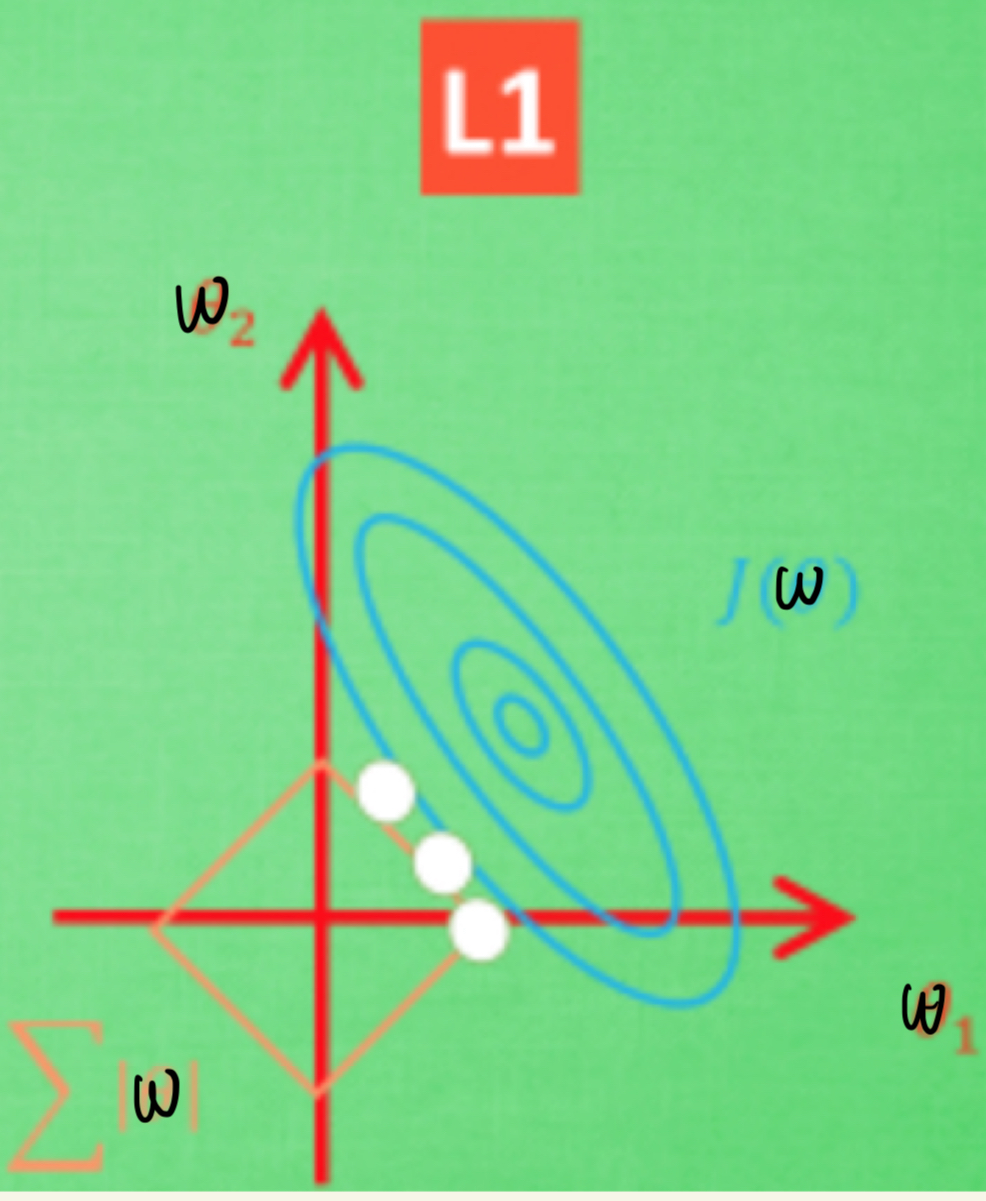
从解空间的角度解释,如下图所示:
-
上述黄线表示正则项受
m值约束的情况下的值,在一个圈上的惩罚值都是相等的; -
蓝色对应的是损失项函数的等高线,可以把下图理解为损失项函数的图像:
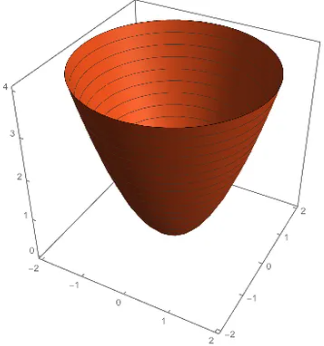
其等高线就是基于
Z轴的切面,在同一等高线上的函数值是相等的,也就是Z值相等。但是越靠近圆心,损失项的损失值越小。 -
那么在满足正则项约束的情况下,我们要找到距离圆心最近的等高线。如上绿图所示,距离圆心最近且满足正则项约束的等高线就是白色切点所在的线,且刚好落在坐标轴上。并不是所有情况下最近的点都刚好在坐标轴上,但是两个图形相切的点落在坐标轴上的概率比较大。如上图所示,其落在坐标轴上
 相应的神经元的值就会变为0,所以权重参数向量就会变得稀疏。
相应的神经元的值就会变为0,所以权重参数向量就会变得稀疏。
-
-
从贝叶斯最大后验概率估计:没看懂,大家可以看这个公式来好好地理解一下!!here
4. 范数作为正则项是如何防止过拟合的?
如图正则化项是具有约束的,在约束条件下,模型参数就不能够想取什么值就取什么值,能够削弱一些明显特征的权重,使得模型没有特别突出的权重,模型便对更多的数据集具有泛化性。
可参考:here
请指正!!!















 5108
5108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









