







开源大数据社区 & 阿里云 EMR 系列直播 第九期
主题:RSS 使用和性能展示
讲师:枢木,开源大数据平台高级开发工程师
内容框架:
RSS 介绍
RSS 使用
RSS 性能
直播回放:扫描文章底部二维码加入钉群观看回放
1
RSS 介绍
Spark Shuffle
产生 numMapper* numReducer 个 block
顺序写、随机读
写时 Spill
单副本,丢数据需 stage 重算
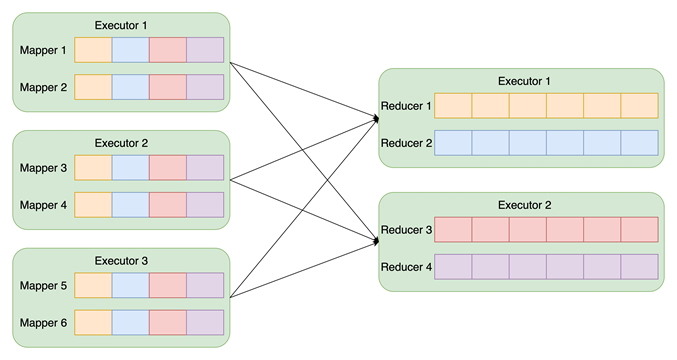
EMR Remote Shuffle Service
追加写、顺序读
无写时 Spill
两副本;副本复制到内存后即完成
副本之间通过内网备份,无需公网带宽
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1646
1646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









