







文章目录
两数之和
难度:简单
一、题目描述:
- 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 的那 两个 整数,并返回它们的数组下标。
- 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
- 你可以按任意顺序返回答案。
示例 1:
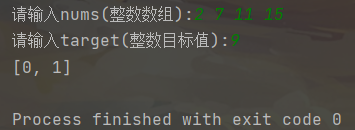
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
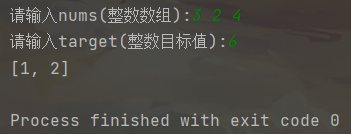
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
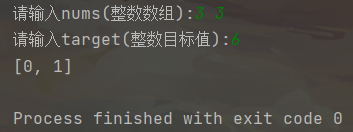
输入:nums = [3,3], target = 6
输出:[0,1]
提示:
- 2 <= nums.length <= 10^3
- -10^9 <= nums[i] <= 10^9
- -10^9 <= target <= 10^9
- 只会存在一个有效答案
来源:力扣(LeetCode)
二、题解:
解法一:朴素解法
def find(nums, target):
length = len(nums)
j = -1
for i in range(length):
if (target - nums[i]) in nums:
if (nums.count(target - nums[i]) == 1) & (target - nums[i] == nums[i]):
continue
else:
j = nums.index(target - nums[i], i + 1)
break
if j > 0:
return [i, j]
else:
return []
def main():
nums = list(map(int, input("请输入nums(整数数组):").strip().split()))
n = int(input("请输入target(整数目标值):"))
print(find(nums, n))
main()
注:对于nums = list(map(int, input("请输入nums(整数数组):").strip().split())),指先删除输入的字符串头尾的空格,然后以空格或者制表符为分隔符。map()在Python 3.x中返回的是迭代器,所以Python 3.x要加list()函数将迭代器转化为列表。
对于list(map(int, input().strip().split()))的补充知识:
-
1、map函数用法
- 描述:map() 函数会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。 - 语法:map(function, iterable, …)
- 参数:function – 函数
iterable – 一个或多个序列 返回值:返回一个迭代器。- 举例:
def square(x): # 计算平方数 return x ** 2 print(map(square, [1, 2, 3, 4, 5])) # 计算列表各个元素的平方 # <map object at 0x100d3d550> # 返回迭代器 print(list(map(square, [1, 2, 3, 4, 5]))) # 使用 list() 转换为列表 # [1, 4, 9, 16, 25] print(list(map(lambda x: x ** 2, [1, 2, 3, 4, 5]))) # 使用 lambda 匿名函数 # [1, 4, 9, 16, 25]
- 描述:map() 函数会根据提供的函数对指定序列做映射。
-
2、 strip()方法:
- 描述:Python strip() 方法用于移除字符串头尾指定的字符(默认为空格)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。 - 语法:str.strip([chars]);
- 补充:
s.strip(rm) 删除s字符串中开头、结尾处,位于 rm删除序列的字符
s.lstrip(rm) 删除s字符串中开头处,位于 rm删除序列的字符
s.rstrip(rm) 删除s字符串中结尾处,位于 rm删除序列的字符 - 参数:chars – 移除字符串头尾指定的字符序列。
- 返回值:返回移除字符串头尾指定的字符序列生成的
新字符串。 - 示例:
str = "*****this is **string** example....wow!!!*****" print(str.strip('*')) # 指定字符串 * # 输出: # this is **string** example....wow!!!
- 描述:Python strip() 方法用于移除字符串头尾指定的字符(默认为空格)或字符序列。
-
3、split()方法
- 描述:split() 通过指定分隔符对字符串进行切片,如果第二个参数 num 有指定值,则分割为 num+1 个子字符串。
- 语法:str.split(str=“”, num=string.count(str))
- 参数:str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num – 分割次数。默认为 -1, 即分隔所有。 - 返回值:
返回分割后的字符串列表。 - 举例:
str = "this is string example....wow!!!" print(str.split()) # 以空格为分隔符 print(str.split('i', 1)) # 以 i 为分隔符 print(str.split('w')) # 以 w 为分隔符 # 输出: # ['this', 'is', 'string', 'example....wow!!!'] # ['th', 's is string example....wow!!!'] # ['this is string example....', 'o', '!!!'] # 亲测str.split()和str.split( )输出结果无区别。
解法二:对解法一的优化
def find(nums, target):
lens = len(nums)
j = -1
for i in range(1, lens):
temp = nums[:i]
if (target - nums[i]) in temp:
j = temp.index(target - nums[i])
break
if j >= 0:
return [j, i]
def main():
nums = list(map(int, input("请输入nums(整数数组):").strip().split()))
n = int(input("请输入target(整数目标值):"))
print(find(nums, n))
main()
注:这里优化了解法一的代码,num2 的查找并不需要每次从 nums 查找一遍,只需要从 num1 位置之前或之后查找即可。为了方便, index 这里选择从 num1 位置之前查找。
对于 temp = nums[:i]的补充知识:
-
1、切片:
- 一个完整的切片表达式包含两个“:”,用于分隔三个参数(start_index、end_index、step),当只有一个“:”时,默认第三个参数step=1。
- 切片操作基本表达式:
object[start_index : end_index : step] - step:正负数均可,其绝对值大小决定了切取数据时的“步长”,
而正负号决定了“切取方向”,正表示“从左往右”取值,负表示“从右往左”取值。当step省略时,默认为1,即从左往右以增量1取值。“切取方向非常重要! - start_index:表示起始索引(包含该索引本身);
该参数省略时,表示从对象“端点”开始取值,至于是从“起点”还是从“终点”开始,则由step参数的正负决定,step为正从“起点”开始,为负从“终点”开始。 - end_index:表示终止索引(不包含该索引本身);
该参数省略时,表示一直取到数据”端点“,至于是到”起点“还是到”终点“,同样由step参数的正负决定,step为正时直到”终点“,为负时直到”起点“。 - 举例:
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] print(a[:]) # 从左往右 # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] print(a[::]) # 从左往右 # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] print(a[::-1]) # 从右往左 # [9, 8, 7, 6, 5, 4, 3, 2, 1, 0] # 代表[start_index:end_index] # 注意:初始值是1而不是0; 6是不包含的,输出的只有1到5 print(a[1:6]) # step=1,从左往右取值,start_index=1到end_index=6同样表示从左往右取值。 # [1, 2, 3, 4, 5] # 代表[start_index:end_index:step] print(a[1:6:-1]) # step=-1,决定了从右往左取值,而start_index=1到end_index=6决定了从左往右取值,两者矛盾。 # [] # 输出为空列表,说明没取到数据。 # 代表[start_index:end_index] print(a[6:1]) # step=1,决定了从左往右取值,而start_index=6到end_index=1决定了从右往左取值,两者矛盾。 # [] # 同样输出为空列表。 # 代表[:end_index] print(a[:6]) # step=1,从左往右取值,从“起点”开始一直取到end_index=6。 # [0, 1, 2, 3, 4, 5] # 代表[:end_index:step] print(a[:6:-1]) # step=-1,从右往左取值,从“终点”开始一直取到end_index=6。 # [9, 8, 7] # 代表[start_index:] print(a[6:]) # step=1,从左往右取值,从start_index=6开始,一直取到“终点”。 # [6, 7, 8, 9] # 代表[start_index::step] print(a[6::-1]) # step=-1,从右往左取值,从start_index=6开始,一直取到“起点”。 # [6, 5, 4, 3, 2, 1, 0]
-
2、range() 函数用法:
- Python3 range() 函数返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表。
Python3 list() 函数是对象迭代器,可以把range()返回的可迭代对象转为一个列表,返回的变量类型为列表。 - 语法:range(stop)
range(start, stop[, step]) - 参数说明:
start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
- Python3 range() 函数返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表。
解法三:字典来模拟哈希查询的过程求解(来自Leecode题解)
def twoSum(nums, target):
hashmap = {}
for ind, num in enumerate(nums):
hashmap[num] = ind
for i, num in enumerate(nums):
j = hashmap.get(target - num)
if j is not None and i != j:
return [i, j]
注:第一个for循环的过程是模拟建立哈希表,第二个for循环是查询。
补充知识:
-
1、Hash(哈希)
- 介绍:Hash :散列,通过关于键值(key)的函数,将数据映射到内存存储中一个位置来访问。这个过程叫做Hash,这个映射函数称做散列函数,存放记录的数组称做散列表(Hash Table),又叫哈希表。
它是基于快速存取的角度设计的,也是一种典型的“空间换时间”的做法。该数据结构可以理解为一个线性表,但是其中的元素不是紧密排列的,而是可能存在空隙。 - Hash的优点:先分类再查找,通过计算缩小范围,加快查找速度。
- 举例:对于集合:{13,19,25,27,17},
(1)若是采用数组或链表结构:
访问其中的一个元素(如18),需要遍历整个集合的元素,时间复杂度为O(n)。
(2)而采用哈希表时:
假如散列函数为H[key] = key % 5;则集合元素对应的hash值分别为{3,4,0,2,2}。
访问元素(18)只需要在Hash值为2的集合中寻找即可.
如果访问没有哈希冲突的元素,例如访问(25),可以直接访问哈希值为(0)的值。 - 故hash时间复杂度最差(
所有的数据都映射到了内存存储中的同一个位置)才为O(n),最优情况(没有冲突的时候)下只需要O(1);一个好的哈希函数(散列函数)的值应尽可能平均分布。 -
由上面的例子,我们可以想象,如果由大量的数据,采用数组或是链表存储时,访问需要遍历,耗费的时间非常多,而Hash表通过哈希计算,可以直接定位到数据所在位置(发生哈希冲突时,哈希值相同,可以定位到较小范围)
大大加快了 查找的速度,节省了大量时间。
- 介绍:Hash :散列,通过关于键值(key)的函数,将数据映射到内存存储中一个位置来访问。这个过程叫做Hash,这个映射函数称做散列函数,存放记录的数组称做散列表(Hash Table),又叫哈希表。
-
2、enumerate() 函数
- 描述:enumerate() 函数用于
将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。 - 语法:enumerate(sequence, [start=0])
- 参数:sequence – 一个序列、迭代器或其他支持迭代对象;start – 下标起始位置。
- 返回值:返回 enumerate(枚举) 对象。
- 示例:
seasons = ['Spring', 'Summer', 'Fall', 'Winter'] print(list(enumerate(seasons))) # [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')] print(list(enumerate(seasons, start=1))) # 小标从 1 开始 # [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]seq = ['one', 'two', 'three'] for i, element in enumerate(seq):# 注意:这里的i 和element均为自定义的,写成a和b也行 print(i, element) # 输出: # 0 one # 1 two # 2 three
- 描述:enumerate() 函数用于
解法四:对解法三的优化(来自Leecode题解)
def twoSum(nums, target):
hashmap = {}
for i, num in enumerate(nums):
if hashmap.get(target - num) is not None:
return [i, hashmap.get(target - num)]
hashmap[num] = i # 这句不能放在if语句之前,解决list中有重复值或target-num=num的情况
注:类似解法二,不需要 mun2 不需要在整个 dict 中去查找。可以在 num1 之前的 dict 中查找,因此就只需要一次循环可解决。
参考:
三、输出结果:
















 867
867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











