







 文章讲述了在使用Transformer模型进行O3浓度反演时遇到的速度慢和内存不足的挑战。作者尝试将模型转移到GPU上以提高速度,但预测阶段仍出现内存不足。通过调整batch_size并未解决问题,最终发现是反演过程中一次性加载全部数据导致的。解决方案是使用for循环逐个处理数据,从而避免内存溢出。
文章讲述了在使用Transformer模型进行O3浓度反演时遇到的速度慢和内存不足的挑战。作者尝试将模型转移到GPU上以提高速度,但预测阶段仍出现内存不足。通过调整batch_size并未解决问题,最终发现是反演过程中一次性加载全部数据导致的。解决方案是使用for循环逐个处理数据,从而避免内存溢出。
1. 前提
利用Transformer模型进行O3浓度的反演
2. 问题
2.1 速度慢
一开始模型是在CPU上面跑的,为了加快速度,我改成了在GPU上跑
方法如下:
1、验证pytorch是否存在GPU版本
在Pycharm命令行输入
import torch
print(torch.cuda.is_available)
# 若输出为True,则存在GPU版本
# 若输出为False,则不存在GPU版本
我的输出为True,说明pytorch是存在GPU版本的
2、将模型从CPU版本转换到GPU版本
- 声明使用GPU(指定具体的卡)
PS:torch.device()是装torch.Tensor的一个空间。
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 'cuda' 这里如果没有指定具体的卡号,系统默认cuda:0
device = torch.device('cuda:2') # 使用2号卡
- 将模型(model)加载到GPU上
model = Transformer() #例子中,采用Transformer模型
model.to(device)
- 将数据和标签放到GPU上【注意!什么数据可以被放入GPU-Tensor类型的数据】
# 只有Tensor类型的数据可以放入GPU中
# 可以一个个【batch_size】进行转换
inputs = inputs.to(device)
labels = labels.to(device)
如果结果还是显示你是在CPU上进行训练,要不就是模型没有加进去,要不就是数据没有加进去
2.2 内存不足
- 在使用CPU时,出现了内存不足的情况
RuntimeError: [enforce fail at C:\cb\pytorch_1000000000000\work\c10\core\impl\alloc_cpu.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate 280410627200 bytes.
- 在使用GPU时,出现了内存不足的情况
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 261.15 GiB (GPU 0; 8.00 GiB total capacity; 487.30 MiB already allocated; 5.71 GiB free; 506.00 MiB reserved in total by PyTorch) If reserved memory is >> allocated memory try sett
我的模型在训练的时候没有问题,在进行预测的时候,总是出现内存不足
(1)一开始我以为是batch_size大小的问题,在从128更改到4后,发现依旧存在问题,这说明不是batch_size大小的问题。
(2)然后,我猜测是反演过程的问题
我在进行模型反演的过程中,直接将全部数据输入到模型model中(大概有10万行),为了验证这个问题,我添加了一个for循环,一个一个数据的反演
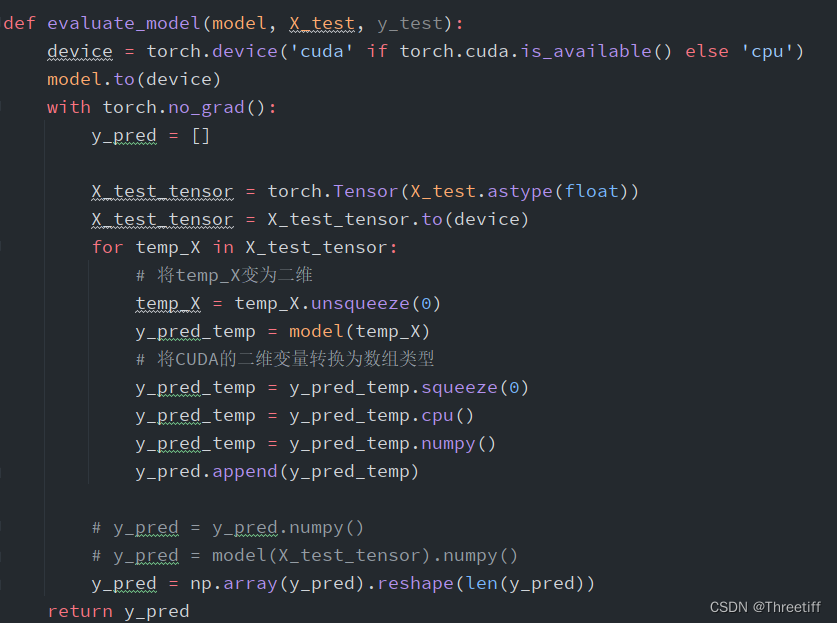
问题解决!
学习链接:

















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









