






1、原理
包括初级学习器和次级学习器
- 初级学习器:个体学习器(用于数据集的初步训练)
- 次级学习器:将初级学习器结合的学习器(将初级学习器得到的训练集进行训练)
2、第一种方法(将全部数据用于训练)
大致如下图:
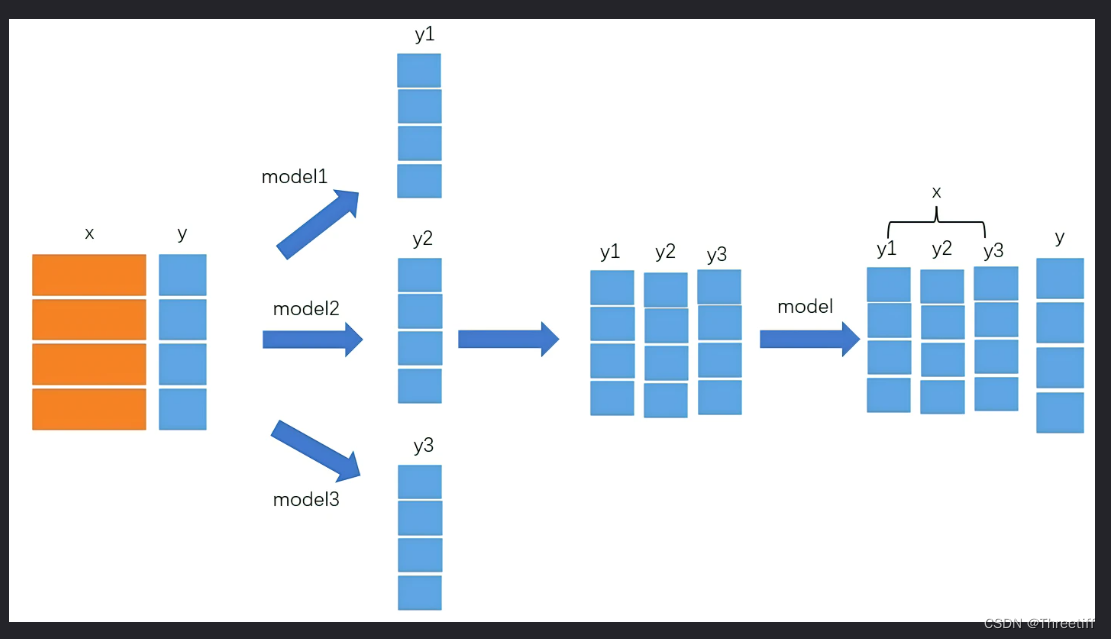
- 1 将X和Y分别输入到三个模型中去(三个模型可以不相同|比如RF、Lightgbm、GDBT)
- 2 对于每一个模型而言:都输出一个预测结果
- 3 将【三个预测结果+真实数据】按照列拼接生成中间训练集
- 4 将中间训练集引入次级学习器(次级学习器不宜太复杂)
- 5 得到最终预测结果
PS:这种方法也可以将数据集分为训练集和测试集,只不过这里没有分
将所有数据作为训练集,最终带入模型
上述这种操作会导致模型过拟合,为了避免过拟合,我们引入KFold
3、第二种方法(引入K折交叉-避免过拟合)
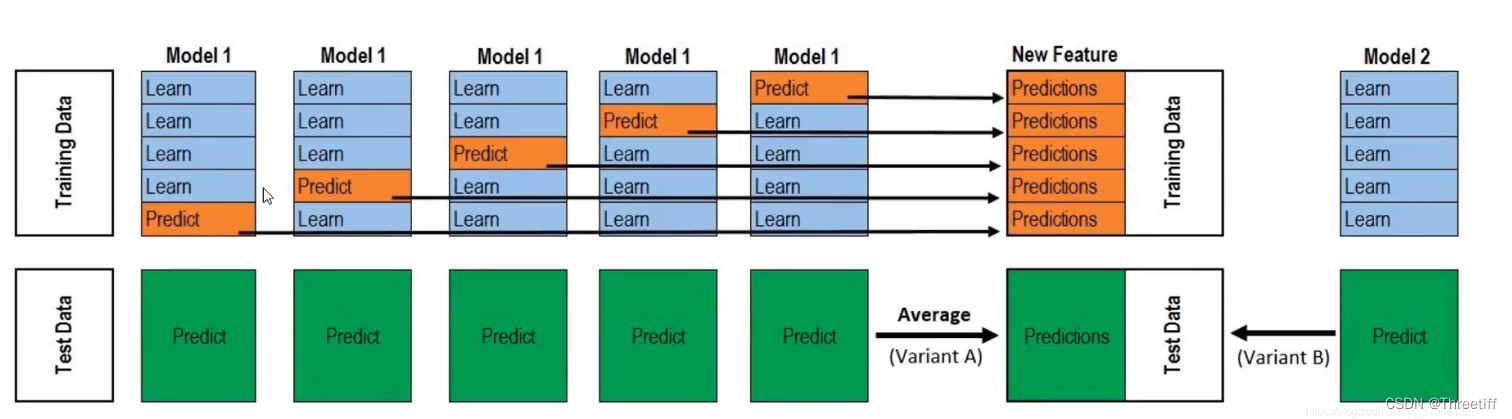
- 1 将数据分类训练集和测试集
- 2 初级学习器的训练
这里我们也假设5个初级学习器|将训练集分为5份(每次选择4份训练,最后一份用来验证)
这里,我们用model1举例:
利用KFlod进行分割,图中的四个蓝块用于学习,黄块用于测试;
5个模型每次测试的数据集不同
将这5个模型的测试数据集拼接得到第一个结果数据集
model2-modl5也是类似的
总之:这样就得到了五个结果数据集(这5个结果数据集的大小相同) - 3 将五个结果数据集和真实标签合并生成中间训练集
- 4 次级学习器的训练:将中间训练集引入次级学习器
- 5 对于test_data:
引入5个初级学习器-得到五个结果数据集-生成中间训练集(将五个结果数据集和数据标签合并)-将中间训练集引入次级学习器-得到结果
注意:
对于这5个模型:KFold的顺序必须要保持一致
并且,五个结果数据集的数据顺序必须和真实标签的数据顺序完全相同
4、总结
第一种方法和第二种方法区别主要在于
KFold是否使用
学习链接:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









