







 本文介绍了Stacking集成学习模型的工作原理和实现代码,通过结合多个基学习器的输出来提高模型的泛化能力。Stacking通过K折交叉验证避免过拟合,使用不同模型的预测值作为新数据输入到第二层模型,从而达到模型融合的效果。作者提供了使用Python的Scikit-Learn库实现Stacking的示例,并展示了在鸢尾花数据集上的应用。
本文介绍了Stacking集成学习模型的工作原理和实现代码,通过结合多个基学习器的输出来提高模型的泛化能力。Stacking通过K折交叉验证避免过拟合,使用不同模型的预测值作为新数据输入到第二层模型,从而达到模型融合的效果。作者提供了使用Python的Scikit-Learn库实现Stacking的示例,并展示了在鸢尾花数据集上的应用。
🌠 『精品学习专栏导航帖』
- 🐳最适合入门的100个深度学习实战项目🐳
- 🐙【PyTorch深度学习项目实战100例目录】项目详解 + 数据集 + 完整源码🐙
- 🐶【机器学习入门项目10例目录】项目详解 + 数据集 + 完整源码🐶
- 🦜【机器学习项目实战10例目录】项目详解 + 数据集 + 完整源码🦜
- 🐌Java经典编程100例🐌
- 🦋Python经典编程100例🦋
- 🦄蓝桥杯历届真题题目+解析+代码+答案🦄
- 🐯【2023王道数据结构目录】课后算法设计题C、C++代码实现完整版大全🐯
2021人工智能领域新星创作者,带你从入门到精通,该博客每天更新,逐渐完善机器学习各个知识体系的文章,帮助大家更高效学习。

一、引言
对于单个模型来说很难拟合复杂的数据,而且对于单模型来说,模型的抗干扰能力较低,所以我们希望可以集成多个模型,结合多个模型的优缺点提高模型的泛化能力。
针对于集成学习一般有两种方式,第一种为Boosting架构,利用基学习器之间串行的方式进行构造强学习器,第二种是Bagging架构,通过构造多个独立的模型,然后通过选举或者加权的方式构造强学习器。
然而还有一种方式就是Stacking,它结合了Boosting和Bagging两种集成方式,它是利用多个基学习器学习原数据,然后将这几个基学习学习到的数据交给第二层模型进行拟合。
说白了就是将第一层模型的输出作为第二层模型的输入。
二、Stacking集成模型
1.Stacking原理
所谓的Stacking就是通过模型对原数据拟合的堆叠进行建模,他首先通过基学习器学习原数据,然后这几个基学习器都会对原数据进行输出,然后将这几个模型的输出按照列的方式进行堆叠,构成了 ( m , p ) (m,p) (m,p) 维的新数据,m代表样本数,p代表基学习器的个数,然后将新的样本数据交给第二层模型进行拟合。
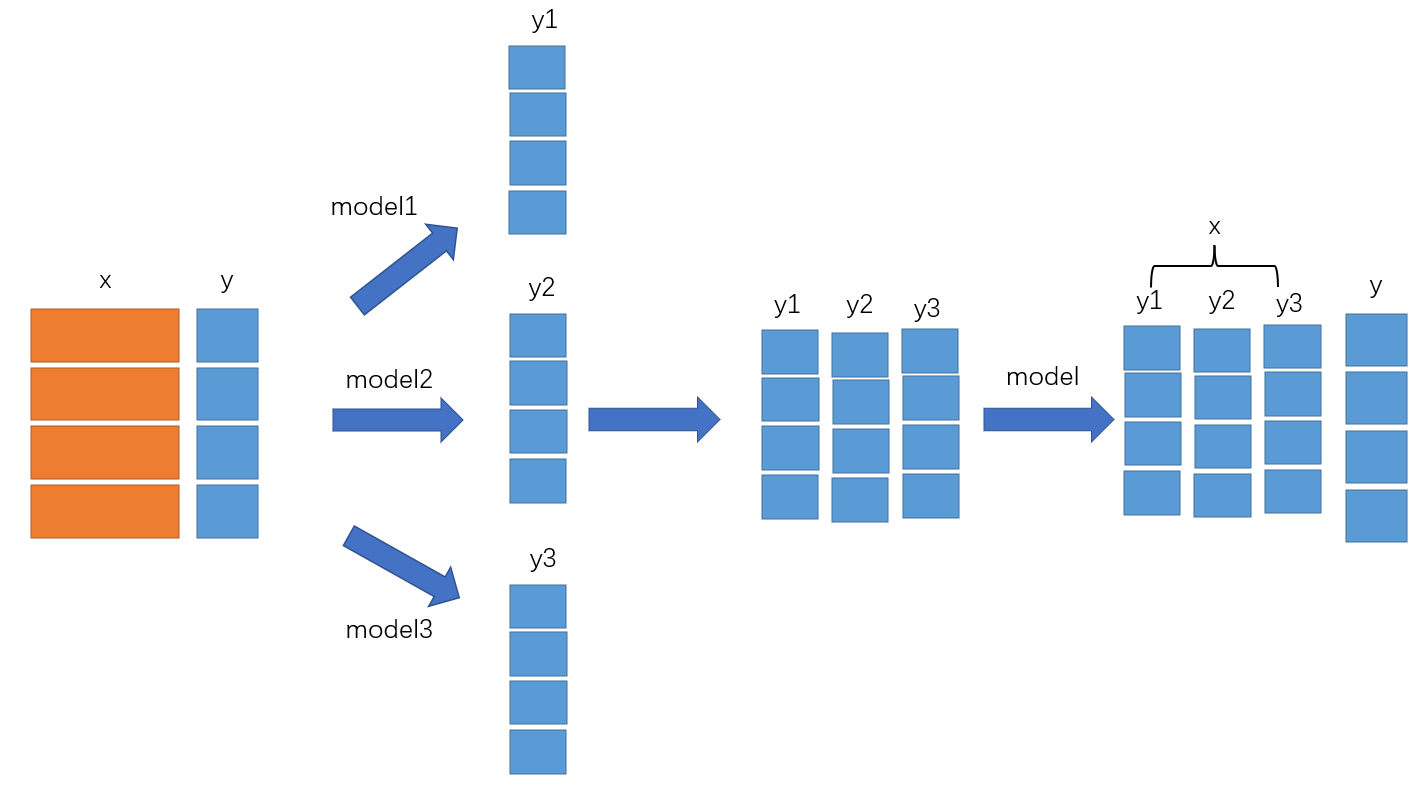
上幅图就是Stacking思想的原理示意图,但是有些时候网上看到的图会有切分训练集和验证集,那是为了防止模型过拟合,所以使用K折交叉验证,没有一次全部训练。
上图的意思就是首先将特征x和标签y分别输入到3个模型中,然后这3个模型分别学习,然后针对于x给出预测值,有时也会给出proba概率,这里我们使用预测值,然后将3个模型的输出值按照列的防止进行堆叠,这就形成了新的样本数据,然后将新的样本数据作为标签x,新数据的标签仍然为原数据的标签y,将新数据的x,y交给第二层的模型进行拟合,这个模型是用来融合前一轮3个模型结果的。
但是这样模型往往会过拟合,所以将上述方法进行改进,使用K折交叉验证的方式,不同的地方就是上面的示意图每个模型训练了所有的数据,然后输出y形成新的数据,使用K折交叉验证,每次只训练k-1折,然后将剩下1折的预测值作为新的数据,这就有效的防止了过拟合。
如果每个模型训练所有的数据,然后再用这个模型去预测y值,那么生成新数据的y非常精确和真实值差不多,为了增强模型的泛化能力,我们每次只训练其中一部分数据,然后用剩余一部分数据进行预测。
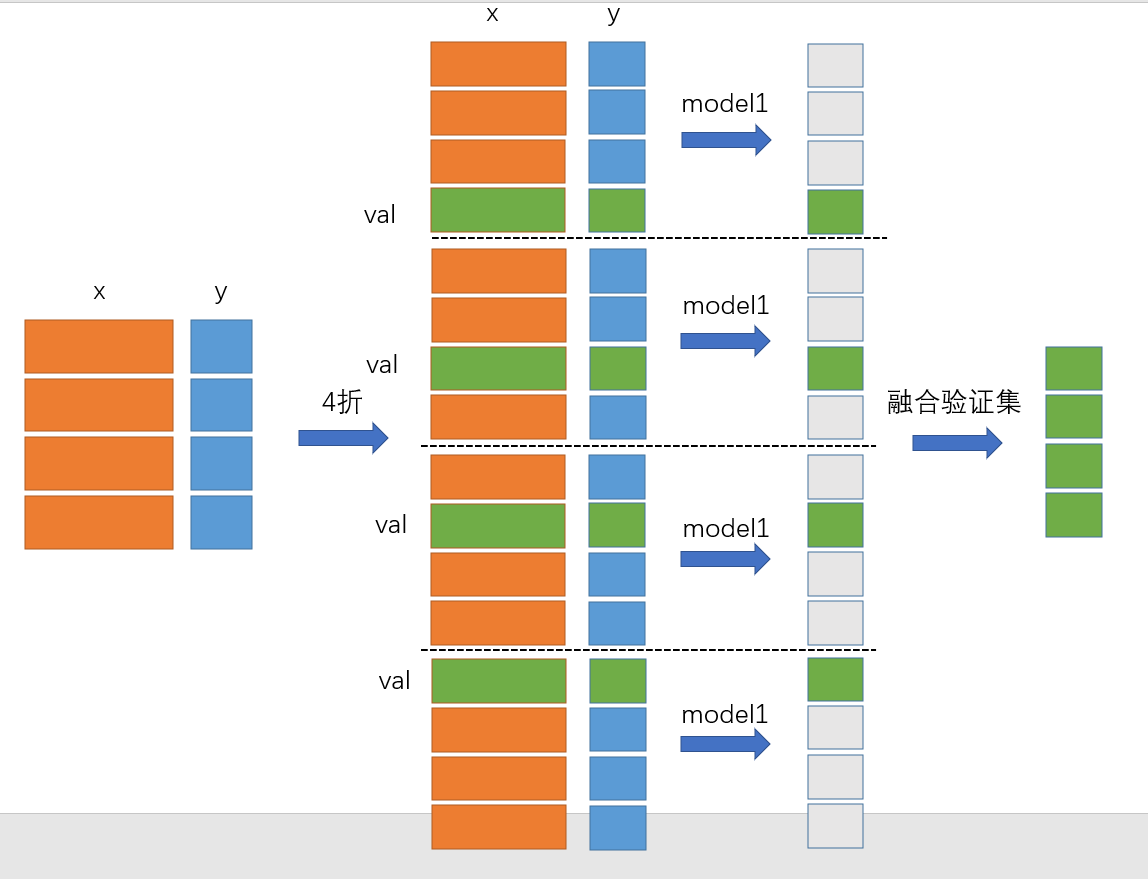
首先利用K折交叉验证,将数据分成4折切分,那么就会形成4组数据集,其中黄色代表训练集,绿色的为验证集,然后将每组的训练集交给模型进行训练,然后对验证集进行预测,就会得到对应验证集的输出,因为4折交叉验证,将数据分成4组,所以我们会形成4个验证集,然后将每个模型对各自组的验证集预测的结果进行按照行的方式堆叠,就会获得完整样本数据的预测值,这只是针对于一个模型,不同学习器同理,每个模型按照这个方式获得预测值,然后再将其按照列合并。
2.实现代码
import numpy as np
from sklearn.model_selection import KFold
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
class MyStacking:
# 初始化模型参数
def __init__(self, estimators, final_estimator, cv=5, method='predict'):
self.cv = cv
self.method = method
self.estimators = estimators
self.final_estimator = final_estimator
# 模型训练
def fit(self, X, y):
# 获得一级输出
dataset_train = self.stacking(X, y)
# 模型融合
self.final_estimator.fit(dataset_train, y)
# 堆叠输出
def stacking(self, X, y):
kf = KFold(n_splits=self.cv, shuffle=True, random_state=2021)
# 获得一级输出
dataset_train = np.zeros((X.shape[0], len(self.estimators)))
for i, model in enumerate(self.estimators):
for (train, val) in kf.split(X, y):
X_train = X[train]
X_val = X[val]
y_train = y[train]
y_val_pred = model.fit(X_train, y_train).predict(X_val)
dataset_train[val, i] = y_val_pred
self.estimators[i] = model
return dataset_train
# 模型预测
def predict(self, X):
datasets_test = np.zeros((X.shape[0], len(self.estimators)))
for i, model in enumerate(self.estimators):
datasets_test[:, i] = model.predict(X)
return self.final_estimator.predict(datasets_test)
# 模型精度
def score(self, X, y):
datasets_test = np.zeros((X.shape[0], len(self.estimators)))
for i, model in enumerate(self.estimators):
datasets_test[:, i] = model.predict(X)
return self.final_estimator.score(datasets_test, y)
if __name__ == '__main__':
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=0.7, random_state=0)
estimators = [
RandomForestClassifier(n_estimators=10),
GradientBoostingClassifier(n_estimators=10)
]
clf = MyStacking(estimators=estimators,
final_estimator=LogisticRegression())
clf.fit(X_train, y_train)
print(clf.score(X_train, y_train))
print(clf.score(X_test, y_test))
写在最后
大家好,我是阿光,觉得文章还不错的话,记得“一键三连”哦!!!




















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











