






文章目录
第一步 尝试提交
code 中 找到一个可以直接提交的代码, (给它点个赞),保存为自己的Notebook,在比赛中提交。
我找的是:Transformer Model Training中文注释版
第二步 观察数据集
note: Parquet 是 Hadoop 生态圈中主流的列式存储格式
/input/asi-signs/train.csv
- path :该样本位置 train_landmark_files/26734/1000035562.parquet
- file_id : 文件ID, unique
- participant_id: 贡献者ID ,unique 26734
- sequence_id : ??? 1000035562
- sign : 该样本标签(位置信息) sticky?>
- sign_ord: sign的二进制版本,自己转换 206?>
第三步 解读代码
数据预处理
PREPROCESS_DATA = True
配置
- seaborn: 一个基于matplotlib的数据可视化库,提供了一个高级接口来绘制美观和有信息量的统计图形。
- Public Leaderboard (LB)——实时显示, Private LB——比赛结束后排名的最终成绩(数据分布可能会变,不要太依赖,以防过拟合)
- gc: 一个模块,提供了一个接口来访问可选的垃圾收集器。
- tqdm: 一个快速和可扩展的Python和CLI进度条。
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_addons as tfa
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sn
from tensorflow import keras
from tqdm.notebook import tqdm
from sklearn.model_selection import train_test_split, GroupShuffleSplit
import glob
import sys
import os
import math
import gc
import sys
import sklearn
import scipy
print(f'Tensorflow V{tf.__version__}')
print(f'Keras V{tf.keras.__version__}')
print(f'Python V{sys.version}')
MatplotLib Global Settings
# MatplotLib Global Settings
# 重置所有参数为默认值
mpl.rcParams.update(mpl.rcParamsDefault)
# 设置 x 轴和 y 轴的刻度标签字体大小为 16
mpl.rcParams['xtick.labelsize'] = 16
mpl.rcParams['ytick.labelsize'] = 16
# 设置坐标轴标签和标题的字体大小为 18 和 24
mpl.rcParams['axes.labelsize'] = 18
mpl.rcParams['axes.titlesize'] = 24
训练配置
# If True, processing data from scratch
# If False, loads preprocessed data
# True,则从头开始处理数据,False,则加载预处理的数据
PREPROCESS_DATA = True
TRAIN_MODEL = True
# True: use 10% of participants as validation set
# False: use all data for training -> gives better LB result更好的leaderboard排名
USE_VAL = False
N_ROWS = 543#设置行数
N_DIMS = 3#设置维度
DIM_NAMES = ['x', 'y', 'z']#设置维度名称
SEED = 42#设置随机数种子
NUM_CLASSES = 250#共250种类别
IS_INTERACTIVE = os.environ['KAGGLE_KERNEL_RUN_TYPE'] == 'Interactive'
#判断是否为交互式环境
VERBOSE = 1 if IS_INTERACTIVE else 2
INPUT_SIZE = 64#输入大小
BATCH_ALL_SIGNS_N = 4
BATCH_SIZE = 256
N_EPOCHS = 100
LR_MAX = 0.001#设置学习率最大值
N_WARMUP_EPOCHS = 0#设置热身轮数
WD_RATIO = 0.05#设置权重衰减比例
MASK_VAL = 4237#设置掩码值
读取训练数据 : train
判断是否为预处理数据环节
如果是交互式环境,就只读取5000行
如果是预处理数据,或者 不是交互式环境 读取所有行
将完整的文件路径存在trian[‘path’]
if IS_INTERACTIVE or not PREPROCESS_DATA:
train = pd.read_csv('/kaggle/input/asl-signs/train.csv').sample(int(5e3), random_state=SEED)
else:
train = pd.read_csv('/kaggle/input/asl-signs/train.csv')
N_SAMPLES = len(train)
train['file_path'] = train['path'].apply(get_file_path)
def get_file_path(path):
return f'/kaggle/input/asl-signs/{path}'
数据预处理
对符号进行数字编码:
添加序数编码符号(为每个符号名称分配编号)
用于符号<->序数编码之间相互转换的字典
train['sign_ord'] = train['sign'].astype('category').cat.codes
SIGN2ORD = train[['sign', 'sign_ord']].set_index('sign').squeeze().to_dict()
ORD2SIGN = train[['sign_ord', 'sign']].set_index('sign_ord').squeeze().to_dict()
统计视频数据
代码会随机采样N个数据集中的视频,读取视频数据并计算不同帧数、缺失帧数和最大帧数。
| ID | value |
|---|---|
| N | 1000(交互环境) or 10000(预处理数据) |
| N_UNIQUE_FRAMES | 存储不同帧数 |
| N_MISSING_FRAMES | 缺失帧数 |
| MAX_FRAME | 最大帧数的数组 |
???怎么计算的??
N = 1000 if (IS_INTERACTIVE or not PREPROCESS_DATA) else 10000
N_UNIQUE_FRAMES = np.zeros(N, dtype=np.uint16) # 初始化 N_UNIQUE_FRAMES 数组
N_MISSING_FRAMES = np.zeros(N, dtype=np.uint16) # 初始化 N_MISSING_FRAMES 数组
MAX_FRAME = np.zeros(N, dtype=np.uint16) # 初始化 MAX_FRAME 数组
PERCENTILES = [0.01, 0.05, 0.25, 0.50, 0.75, 0.95, 0.99, 0.999] # 定义 PERCENTILES 列表
for idx, file_path in enumerate(tqdm(train['file_path'].sample(N, random_state=SEED))): # 遍历 train['file_path'] 中的文件路径
df = pd.read_parquet(file_path) # 读取文件
N_UNIQUE_FRAMES[idx] = df['frame'].nunique() # 计算每个文件中不同帧的数量
N_MISSING_FRAMES[idx] = (df['frame'].max() - df['frame'].min()) - df['frame'].nunique() + 1 # 计算每个文件中缺失帧的数量
MAX_FRAME[idx] = df['frame'].max() # 计算每个文件中最大帧数
创建Landmark Indices 关键点索引
USE_TYPES = ['left_hand', 'pose', 'right_hand']
START_IDX = 468
# 定义原始数据中的嘴唇关键点索引,共40个
LIPS_IDXS0 = np.array([
61, 185, 40, 39, 37, 0, 267, 269, 270, 409,
291, 146, 91, 181, 84, 17, 314, 405, 321, 375,
78, 191, 80, 81, 82, 13, 312, 311, 310, 415,
95, 88, 178, 87, 14, 317, 402, 318, 324, 308,
])
# 定义原始数据中的左手关键点索引,共21个
LEFT_HAND_IDXS0 = np.arange(468,489)
# 定义原始数据中的右手关键点索引,共21个
RIGHT_HAND_IDXS0 = np.arange(522,543)
# 定义原始数据中的左侧姿态关键点索引,共5个
LEFT_POSE_IDXS0 = np.array([502, 504, 506, 508, 510])
# 定义原始数据中的右侧姿态关键点索引,共5个
RIGHT_POSE_IDXS0 = np.array([503, 505, 507, 509, 511])
# 定义左手优先的关键点索引,包括嘴唇、左手和左侧姿态,共66个
LANDMARK_IDXS_LEFT_DOMINANT0 = np.concatenate((LIPS_IDXS0, LEFT_HAND_IDXS0, LEFT_POSE_IDXS0))
# 定义右手优先的关键点索引,包括嘴唇、右手和右侧姿态,共66个
LANDMARK_IDXS_RIGHT_DOMINANT0 = np.concatenate((LIPS_IDXS0, RIGHT_HAND_IDXS0, RIGHT_POSE_IDXS0))
# 定义所有手部关键点索引,包括左手和右手,共42个
HAND_IDXS0 = np.concatenate((LEFT_HAND_IDXS0, RIGHT_HAND_IDXS0), axis=0)
# 定义处理后数据的列数,等于66
N_COLS = LANDMARK_IDXS_LEFT_DOMINANT0.size
# 定义处理后数据中的嘴唇关键点索引,从0到39
LIPS_IDXS = np.argwhere(np.isin(LANDMARK_IDXS_LEFT_DOMINANT0, LIPS_IDXS0)).squeeze()
# 定义处理后数据中的左手关键点索引,从40到60
LEFT_HAND_IDXS = np.argwhere(np.isin(LANDMARK_IDXS_LEFT_DOMINANT0, LEFT_HAND_IDXS0)).squeeze()
# 定义处理后数据中的右手关键点索引,从40到60
RIGHT_HAND_IDXS = np.argwhere(np.isin(LANDMARK_IDXS_LEFT_DOMINANT0, RIGHT_HAND_IDXS0)).squeeze()
# 定义处理后数据中的所有手部关键点索引,从40到81
HAND_IDXS = np.argwhere(np.isin(LANDMARK_IDXS_LEFT_DOMINANT0, HAND_IDXS0)).squeeze()
# 定义处理后数据中的姿态关键点索引,从61到65
POSE_IDXS = np.argwhere(np.isin(LANDMARK_IDXS_LEFT_DOMINANT0, LEFT_POSE_IDXS0)).squeeze()
# 打印出手部关键点索引的长度和处理后数据的列数
print(f'# HAND_IDXS: {len(HAND_IDXS)}, N_COLS: {N_COLS}')
#这段代码是用于定义处理后数据中不同部位的关键点的起始位置,以便于后续的切片或索引操作
# 定义嘴唇关键点的起始位置,为0
LIPS_START = 0
# 定义左手关键点的起始位置,为嘴唇关键点的数量
LEFT_HAND_START = LIPS_IDXS.size
# 定义右手关键点的起始位置,为左手关键点的起始位置加上左手关键点的数量
RIGHT_HAND_START = LEFT_HAND_START + LEFT_HAND_IDXS.size
# 定义姿态关键点的起始位置,为右手关键点的起始位置加上右手关键点的数量
POSE_START = RIGHT_HAND_START + RIGHT_HAND_IDXS.size
# 打印出不同部位的关键点的起始位置
print(f'LIPS_START: {LIPS_START}, LEFT_HAND_START: {LEFT_HAND_START}, RIGHT_HAND_START: {RIGHT_HAND_START}, POSE_START: {POSE_START}')
HAND_IDXS: 21
N_COLS: 66
LIPS_START: 0, LEFT_HAND_START: 40, RIGHT_HAND_START: 61, POSE_START: 61
手动定义各个关键点索引
| 原始数据 | 意义 | 个数 |
|---|---|---|
| LIPS_IDXS0 | 嘴唇 | 40 |
| LEFT_HAND_IDXS0 | 左手 | 21 |
| RIGHT_HAND_IDXS0 | 右手 | 21 |
| LEFT_POSE_IDXS0 | 左侧姿态 | 5 |
| RIGHT_POSE_IDXS0 | 右侧姿态 | 5 |
| LANDMARK_IDXS_LEFT_DOMINANT0 | 左手优先 | 66 |
| LANDMARK_IDXS_RIGHT_DOMINANT0 | 右手优先 | 66 |
| HAND_IDXS0 | 所有手 | 42 |
| 处理后的数据 | 意义 | 个数 |
|---|---|---|
| N_COLS | 数据的列数 | 66 |
| LIPS_IDXS | 嘴唇 | 40 |
| LEFT_HAND_IDXS | 左手 | 20 |
| RIGHT_HAND_IDXS | 右手 | 20 |
| HAND_IDXS | 所有手 | 40 |
| POSE_IDXS | 所有姿态 | 4 |
自定义一个使用TF的数据预处理层
note:
tf.constant 定义一个常量
tf.transpose 转置
python装饰器就是用于拓展原来函数功能的一种函数
- normalisation_correction 这个矩阵用于校正相机的拍摄方向,将左手调整为右手,右手调整为左手。
- pad_edge 用于在给定张量的左侧或右侧填充一定数量的重复元素
- @tf.function 装饰器 装饰了一个 call 方法,用于处理输入数据
- tf.reduce_sum 是按一定方式计算张量中元素之和,axis指定按哪个维度进行加和
- tf.gather 根据 index,在 input 的 dim 维度上收集 value
- tf.cast 将x的数据格式转化成dtype数据类型
- tf.reduce_min 计算张量的各个维度上元素的最小值
call:
- 获取输入数据的帧数(1维度) = N_FRAMES0
- 计算每一帧中手部关键点非 NaN(非空)值的和,并存储在 left_hand_sum 和 right_hand_sum 中。判断左手或右手哪只手是主导手。
- 根据主导手的结果,计算每一帧中主导手的手部关键点非 NaN(非空)值的和,并存储在 frames_hands_non_nan_sum 中。
- 根据 frames_hands_non_nan_sum 中的结果,找到非空帧的索引,并存储在 non_empty_frames_idxs 中。
- 根据 non_empty_frames_idxs 过滤输入数据,并进行一系列归一化和填充操作,最终返回处理后的数据和填充后的帧索引。
- 计算了输入数据的帧数(N_FRAMES)
- **计算左右手各自在数据中的坐标之和,找到了数据中支配性手的标志点???
- 该方法计算了每个帧的支配性手中非 NaN 值的数量,以确定哪些帧需要保留。
- 它使用这些索引从输入数据中收集标志点数据。
- 将帧索引的数据类型从整数转换为浮点数,然后将其规范化为以 0 开始
- 再次计算了经过筛选的数据的帧数(N_FRAMES),然后从这些数据中收集了特定类型的标志点数据**
- 如果数据的帧数小于指定的输入大小(INPUT_SIZE),则使用 -1 进行填充
- 将数据的帧数扩展到指定的输入大小,并将 NaN 值替换为 0。如果数据的帧数大于指定的输入大小,则使用重复数据将其缩小到指定的输入大小,并填充任何缺失的数据。
preprocess_layer = PreprocessLayer()
"""
Tensorflow layer to process data in TFLite
Data needs to be processed in the model itself, so we can not use Python
"""
class PreprocessLayer(tf.keras.layers.Layer):
def __init__(self):
super(PreprocessLayer, self).__init__()
normalisation_correction = tf.constant([
# Add 0.50 to left hand (original right hand) and substract 0.50 of right hand (original left hand)
[0] * len(LIPS_IDXS) + [0.50] * len(LEFT_HAND_IDXS) + [0.50] * len(POSE_IDXS),
# Y coordinates stay intact
[0] * len(LANDMARK_IDXS_LEFT_DOMINANT0),
# Z coordinates stay intact
[0] * len(LANDMARK_IDXS_LEFT_DOMINANT0),
],
dtype=tf.float32,
)
self.normalisation_correction = tf.transpose(normalisation_correction, [1,0])
def pad_edge(self, t, repeats, side):
if side == 'LEFT':
return tf.concat((tf.repeat(t[:1], repeats=repeats, axis=0), t), axis=0)
elif side == 'RIGHT':
return tf.concat((t, tf.repeat(t[-1:], repeats=repeats, axis=0)), axis=0)
@tf.function(
input_signature=(tf.TensorSpec(shape=[None,N_ROWS,N_DIMS], dtype=tf.float32),),
)
def call(self, data0):
# Number of Frames in Video
N_FRAMES0 = tf.shape(data0)[0]
# Find dominant hand by comparing summed absolute coordinates
left_hand_sum = tf.math.reduce_sum(tf.where(tf.math.is_nan(tf.gather(data0, LEFT_HAND_IDXS0, axis=1)), 0, 1))
right_hand_sum = tf.math.reduce_sum(tf.where(tf.math.is_nan(tf.gather(data0, RIGHT_HAND_IDXS0, axis=1)), 0, 1))
left_dominant = left_hand_sum >= right_hand_sum
# Count non NaN Hand values in each frame for the dominant hand
if left_dominant:
frames_hands_non_nan_sum = tf.math.reduce_sum(
tf.where(tf.math.is_nan(tf.gather(data0, LEFT_HAND_IDXS0, axis=1)), 0, 1),
axis=[1, 2],
)
else:
frames_hands_non_nan_sum = tf.math.reduce_sum(
tf.where(tf.math.is_nan(tf.gather(data0, RIGHT_HAND_IDXS0, axis=1)), 0, 1),
axis=[1, 2],
)
# Find frames indices with coordinates of dominant hand
non_empty_frames_idxs = tf.where(frames_hands_non_nan_sum > 0)
non_empty_frames_idxs = tf.squeeze(non_empty_frames_idxs, axis=1)
# Filter frames
data = tf.gather(data0, non_empty_frames_idxs, axis=0)
# Cast Indices in float32 to be compatible with Tensorflow Lite
non_empty_frames_idxs = tf.cast(non_empty_frames_idxs, tf.float32)
# Normalize to start with 0
non_empty_frames_idxs -= tf.reduce_min(non_empty_frames_idxs)
# Number of Frames in Filtered Video
N_FRAMES = tf.shape(data)[0]
# Gather Relevant Landmark Columns
if left_dominant:
data = tf.gather(data, LANDMARK_IDXS_LEFT_DOMINANT0, axis=1)
else:
data = tf.gather(data, LANDMARK_IDXS_RIGHT_DOMINANT0, axis=1)
data = (
self.normalisation_correction + (
(data - self.normalisation_correction) * tf.where(self.normalisation_correction != 0, -1.0, 1.0))
)
# Video fits in INPUT_SIZE
if N_FRAMES < INPUT_SIZE:
# Pad With -1 to indicate padding
non_empty_frames_idxs = tf.pad(non_empty_frames_idxs, [[0, INPUT_SIZE-N_FRAMES]], constant_values=-1)
# Pad Data With Zeros
data = tf.pad(data, [[0, INPUT_SIZE-N_FRAMES], [0,0], [0,0]], constant_values=0)
# Fill NaN Values With 0
data = tf.where(tf.math.is_nan(data), 0.0, data)
return data, non_empty_frames_idxs
# Video needs to be downsampled to INPUT_SIZE
else:
# Repeat
if N_FRAMES < INPUT_SIZE**2:
repeats = tf.math.floordiv(INPUT_SIZE * INPUT_SIZE, N_FRAMES0)
data = tf.repeat(data, repeats=repeats, axis=0)
non_empty_frames_idxs = tf.repeat(non_empty_frames_idxs, repeats=repeats, axis=0)
# Pad To Multiple Of Input Size
pool_size = tf.math.floordiv(len(data), INPUT_SIZE)
if tf.math.mod(len(data), INPUT_SIZE) > 0:
pool_size += 1
if pool_size == 1:
pad_size = (pool_size * INPUT_SIZE) - len(data)
else:
pad_size = (pool_size * INPUT_SIZE) % len(data)
# Pad Start/End with Start/End value
pad_left = tf.math.floordiv(pad_size, 2) + tf.math.floordiv(INPUT_SIZE, 2)
pad_right = tf.math.floordiv(pad_size, 2) + tf.math.floordiv(INPUT_SIZE, 2)
if tf.math.mod(pad_size, 2) > 0:
pad_right += 1
# Pad By Concatenating Left/Right Edge Values
data = self.pad_edge(data, pad_left, 'LEFT')
data = self.pad_edge(data, pad_right, 'RIGHT')
# Pad Non Empty Frame Indices
non_empty_frames_idxs = self.pad_edge(non_empty_frames_idxs, pad_left, 'LEFT')
non_empty_frames_idxs = self.pad_edge(non_empty_frames_idxs, pad_right, 'RIGHT')
# Reshape to Mean Pool
data = tf.reshape(data, [INPUT_SIZE, -1, N_COLS, N_DIMS])
non_empty_frames_idxs = tf.reshape(non_empty_frames_idxs, [INPUT_SIZE, -1])
# Mean Pool
data = tf.experimental.numpy.nanmean(data, axis=1)
non_empty_frames_idxs = tf.experimental.numpy.nanmean(non_empty_frames_idxs, axis=1)
# Fill NaN Values With 0
data = tf.where(tf.math.is_nan(data), 0.0, data)
return data, non_empty_frames_idxs
创建数据集
- 数据进行预处理
1.1 X type = [N_SAMPLES, INPUT_SIZE, N_COLS, N_DIMS]
Y type = [N_SAMPLES]
NON_EMPTY_FRAME_IDXS type = [N_SAMPLES, INPUT_SIZE]
# Preprocess All Data From Scratch
if PREPROCESS_DATA:
preprocess_data()
ROOT_DIR = '.'
else:
ROOT_DIR = '/kaggle/input/gislr-dataset-public'
# Load Data
if USE_VAL:
# Load Train
X_train = np.load(f'{ROOT_DIR}/X_train.npy')
y_train = np.load(f'{ROOT_DIR}/y_train.npy')
NON_EMPTY_FRAME_IDXS_TRAIN = np.load(f'{ROOT_DIR}/NON_EMPTY_FRAME_IDXS_TRAIN.npy')
# Load Val
X_val = np.load(f'{ROOT_DIR}/X_val.npy')
y_val = np.load(f'{ROOT_DIR}/y_val.npy')
NON_EMPTY_FRAME_IDXS_VAL = np.load(f'{ROOT_DIR}/NON_EMPTY_FRAME_IDXS_VAL.npy')
# Define validation Data
validation_data = ({ 'frames': X_val, 'non_empty_frame_idxs': NON_EMPTY_FRAME_IDXS_VAL }, y_val)
else:
X_train = np.load(f'{ROOT_DIR}/X.npy')
y_train = np.load(f'{ROOT_DIR}/y.npy')
NON_EMPTY_FRAME_IDXS_TRAIN = np.load(f'{ROOT_DIR}/NON_EMPTY_FRAME_IDXS.npy')
validation_data = None
# Train
print_shape_dtype([X_train, y_train, NON_EMPTY_FRAME_IDXS_TRAIN], ['X_train', 'y_train', 'NON_EMPTY_FRAME_IDXS_TRAIN'])
# Val
if USE_VAL:
print_shape_dtype([X_val, y_val, NON_EMPTY_FRAME_IDXS_VAL], ['X_val', 'y_val', 'NON_EMPTY_FRAME_IDXS_VAL'])
# Sanity Check
print(f'# NaN Values X_train: {np.isnan(X_train).sum()}')
note:
np.full(shape, fill_value, dtype=None, order=‘C’) 返回一个指定形状、类型和数值的数组.
npy 文件用于存储重建 ndarray 所需的数据、图形、dtype 和其他信息
GroupShuffleSplit 先将待划分的样本集分组,再按照分组划分训练集、测试集。
# Get the full dataset
def preprocess_data():
# Create arrays to save data
X = np.zeros([N_SAMPLES, INPUT_SIZE, N_COLS, N_DIMS], dtype=np.float32)
y = np.zeros([N_SAMPLES], dtype=np.int32)
NON_EMPTY_FRAME_IDXS = np.full([N_SAMPLES, INPUT_SIZE], -1, dtype=np.float32)
# Fill X/y
for row_idx, (file_path, sign_ord) in enumerate(tqdm(train[['file_path', 'sign_ord']].values)):
# Log message every 5000 samples
if row_idx % 5000 == 0:
print(f'Generated {row_idx}/{N_SAMPLES}')
data, non_empty_frame_idxs = get_data(file_path)
X[row_idx] = data
y[row_idx] = sign_ord
NON_EMPTY_FRAME_IDXS[row_idx] = non_empty_frame_idxs
# Sanity check, data should not contain NaN values
if np.isnan(data).sum() > 0:
print(row_idx)
return data
# Save X/y
np.save('X.npy', X)
np.save('y.npy', y)
np.save('NON_EMPTY_FRAME_IDXS.npy', NON_EMPTY_FRAME_IDXS)
# Save Validation
splitter = GroupShuffleSplit(test_size=0.10, n_splits=2, random_state=SEED)
PARTICIPANT_IDS = train['participant_id'].values
train_idxs, val_idxs = next(splitter.split(X, y, groups=PARTICIPANT_IDS))
# Save Train
X_train = X[train_idxs]
NON_EMPTY_FRAME_IDXS_TRAIN = NON_EMPTY_FRAME_IDXS[train_idxs]
y_train = y[train_idxs]
np.save('X_train.npy', X_train)
np.save('y_train.npy', y_train)
np.save('NON_EMPTY_FRAME_IDXS_TRAIN.npy', NON_EMPTY_FRAME_IDXS_TRAIN)
# Save Validation
X_val = X[val_idxs]
NON_EMPTY_FRAME_IDXS_VAL = NON_EMPTY_FRAME_IDXS[val_idxs]
y_val = y[val_idxs]
np.save('X_val.npy', X_val)
np.save('y_val.npy', y_val)
np.save('NON_EMPTY_FRAME_IDXS_VAL.npy', NON_EMPTY_FRAME_IDXS_VAL)
# Split Statistics
print(f'Patient ID Intersection Train/Val: {set(PARTICIPANT_IDS[train_idxs]).intersection(PARTICIPANT_IDS[val_idxs])}')
print(f'X_train shape: {X_train.shape}, X_val shape: {X_val.shape}')
print(f'y_train shape: {y_train.shape}, y_val shape: {y_val.shape}')
X[row_idx] = data
y[row_idx] = sign_ord
NON_EMPTY_FRAME_IDXS[row_idx] = non_empty_frame_idxs
X_train shape: (94477, 64, 66, 3), dtype: float32
y_train shape: (94477,), dtype: int32
NON_EMPTY_FRAME_IDXS_TRAIN shape: (94477, 64), dtype: float32
NaN Values X_train: 0
def get_data(file_path):
# Load Raw Data
data = load_relevant_data_subset(file_path)
# Process Data Using Tensorflow
data = preprocess_layer(data)
return data
# Source: https://www.kaggle.com/competitions/asl-signs/overview/evaluation
#`load_relevant_data_subset 加载相关数据子集
#提取数据集中的x、y、z三列数据,将数据集按照每帧的地标数量进行切分,返回一个三维数组。
#其中第一维表示帧数,第二维表示每帧的地标数量,第三维表示x、y、z三个坐标轴。
def load_relevant_data_subset(pq_path):
data_columns = ['x', 'y', 'z']
data = pd.read_parquet(pq_path, columns=data_columns)
n_frames = int(len(data) / ROWS_PER_FRAME)
data = data.values.reshape(n_frames, ROWS_PER_FRAME, len(data_columns))
return data.astype(np.float32)
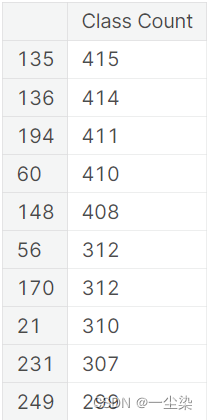
display(pd.Series(y_train).value_counts().to_frame('Class Count').iloc[[0,1,2,3,4, -5,-4,-3,-2,-1]])
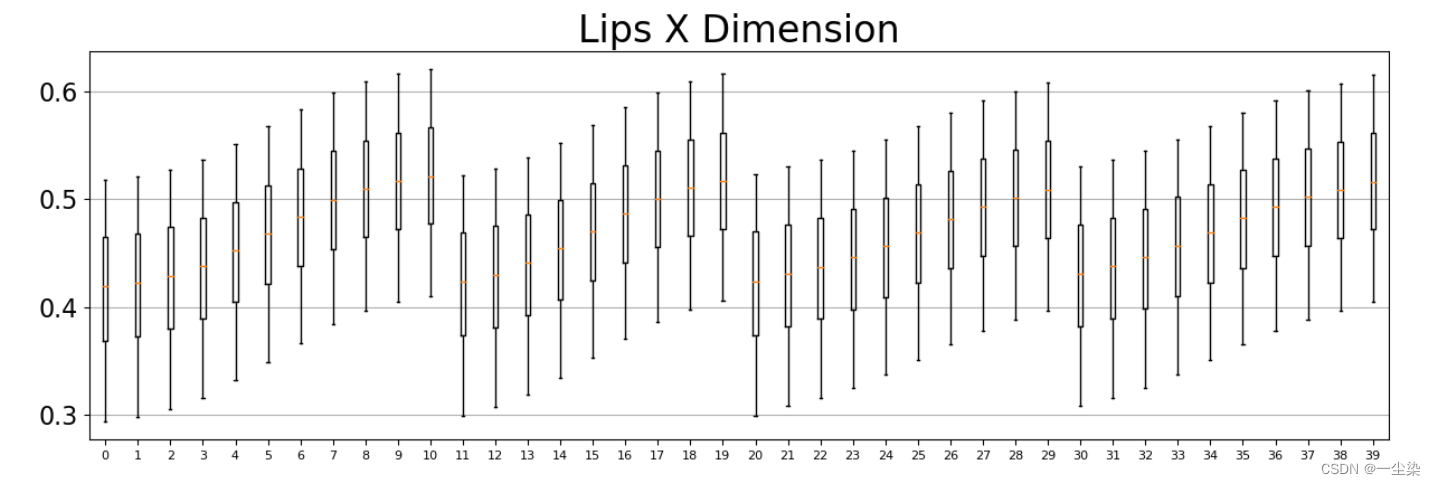
计算嘴唇,手, 姿势的均值和标准差
boxplot()函数绘制箱, 箱图是一中用于统计数据分布的统计图,也可以粗略地看出数据是否具有对称性,分布的分散程度等信息.最下方的横线表示最小值,最上方的横线表示最大值,黑色空心圆圈表示异常值,黑色实心圆圈表示极端值,箱子由下四分位数、中值以及上四分位数组成。
异常值又称离群值,指大于1.5倍的四分位数间距的值。处于1.5倍~3倍四分位数间距的值用空心圆圈表示。极端值属于异常值中的一种。极端值是指大于3倍的四分位数间距的值。
LIPS_MEAN, LIPS_STD = get_lips_mean_std()
def get_lips_mean_std():
# LIPS
LIPS_MEAN_X = np.zeros([LIPS_IDXS.size], dtype=np.float32)
LIPS_MEAN_Y = np.zeros([LIPS_IDXS.size], dtype=np.float32)
LIPS_STD_X = np.zeros([LIPS_IDXS.size], dtype=np.float32)
LIPS_STD_Y = np.zeros([LIPS_IDXS.size], dtype=np.float32)
fig, axes = plt.subplots(3, 1, figsize=(15, N_DIMS*6))
for col, ll in enumerate(tqdm( np.transpose(X_train[:,:,LIPS_IDXS], [2,3,0,1]).reshape([LIPS_IDXS.size, N_DIMS, -1]) )):
for dim, l in enumerate(ll):
v = l[np.nonzero(l)]
if dim == 0: # X
LIPS_MEAN_X[col] = v.mean()
LIPS_STD_X[col] = v.std()
if dim == 1: # Y
LIPS_MEAN_Y[col] = v.mean()
LIPS_STD_Y[col] = v.std()
axes[dim].boxplot(v, notch=False, showfliers=False, positions=[col], whis=[5,95])
for ax, dim_name in zip(axes, DIM_NAMES):
ax.set_title(f'Lips {dim_name.upper()} Dimension', size=24)
ax.tick_params(axis='x', labelsize=8)
ax.grid(axis='y')
plt.subplots_adjust(hspace=0.50)
plt.show()
LIPS_MEAN = np.array([LIPS_MEAN_X, LIPS_MEAN_Y]).T
LIPS_STD = np.array([LIPS_STD_X, LIPS_STD_Y]).T
return LIPS_MEAN, LIPS_STD
Samples
生成器函数 get_train_batch_all_signs 将创建一个无限循环的生成器,它会生成包含所有手语标记的训练批次。为了方便测试,dummy_dataset 是从这个生成器中获取的一个批次,它包含了 X_batch、y_batch 和 NON_EMPTY_FRAME_IDXS_TRAIN 字典,以及一个包含所有手语标记的数量的常量 BATCH_ALL_SIGNS_N。
在上述代码中,X_batch 是一个字典,它包含了 frames 和 non_empty_frame_idxs 字典,它们的形状和数据类型被打印出来。此外,还打印了 y_batch 数组的形状和数据类型。最后,使用 pd.Series(y_batch).value_counts() 函数验证每个手语标记都被包含了 BATCH_ALL_SIGNS_N 次。
dummy_dataset = get_train_batch_all_signs(X_train, y_train, NON_EMPTY_FRAME_IDXS_TRAIN)
X_batch, y_batch = next(dummy_dataset)
for k, v in X_batch.items():
print(f'{k} shape: {v.shape}, dtype: {v.dtype}')
# Batch shape/dtype
print(f'y_batch shape: {y_batch.shape}, dtype: {y_batch.dtype}')
# Verify each batch contains each sign exactly N times
display(pd.Series(y_batch).value_counts().to_frame('Counts'))
这段代码定义了一个生成器函数 get_train_batch_all_signs,用于生成指定数量(n)的所有手语标记的训练批次。
该函数采用手语数据集(X 和 y)、非空帧索引集(NON_EMPTY_FRAME_IDXS)和一批次中所有手语标记的数量(n)作为输入,并生成包含 NUM_CLASSES * n 个样本的训练批次。这个训练批次包含一个 frames 字典和一个 non_empty_frame_idxs 字典,用于存储样本的手语帧和相应的非空帧索引。y_batch 数组包含了所有手语标记的序号。
函数的主要逻辑是循环遍历所有手语标记,选择每个标记中的 n 个样本,并将它们添加到批次数组中。生成器会不停地循环生成这些样本,以便模型可以在整个训练过程中不断获得训练数据。
# Custom sampler to get a batch containing N times all signs
def get_train_batch_all_signs(X, y, NON_EMPTY_FRAME_IDXS, n=BATCH_ALL_SIGNS_N):
# Arrays to store batch in
X_batch = np.zeros([NUM_CLASSES*n, INPUT_SIZE, N_COLS, N_DIMS], dtype=np.float32)
y_batch = np.arange(0, NUM_CLASSES, step=1/n, dtype=np.float32).astype(np.int64)
non_empty_frame_idxs_batch = np.zeros([NUM_CLASSES*n, INPUT_SIZE], dtype=np.float32)
# Dictionary mapping ordinally encoded sign to corresponding sample indices
CLASS2IDXS = {}
for i in range(NUM_CLASSES):
CLASS2IDXS[i] = np.argwhere(y == i).squeeze().astype(np.int32)
while True:
# Fill batch arrays
for i in range(NUM_CLASSES):
idxs = np.random.choice(CLASS2IDXS[i], n)
X_batch[i*n:(i+1)*n] = X[idxs]
non_empty_frame_idxs_batch[i*n:(i+1)*n] = NON_EMPTY_FRAME_IDXS[idxs]
yield { 'frames': X_batch, 'non_empty_frame_idxs': non_empty_frame_idxs_batch }, y_batch
Model Config
| 常量和变量 | 意义 | 值 |
|---|---|---|
| LAYER_NORM_EPS | 设置层归一化的 epsilon 值 | ! 1e-6 |
| LIPS_UNITS | 嘴密集层单元数 | 384 |
| HANDS_UNITS | 手密集层单元数 | 384 |
| POSE_UNITS | 姿势密集层单元数 | 384 |
| UNITS | 最终嵌入 | 512 |
| NUM_BLOCKS | 变换器块数 | |
| MLP_RATIO | MLP 比率;第一个全连接层上升通道倍数; | 2 |
| EMBEDDING_DROPOUT | 嵌入的dropout 比率 | 0.00 |
| MLP_DROPOUT_RATIO | MLP的dropout 比率 | 0.30 |
| CLASSIFIER_DROPOUT_RATIO | 分类器dropout 比率 | 0.10 |
| INIT_HE_UNIFORM | 权重的初始化器 | |
| INIT_ZEROS | 权重的初始化器 | |
| INIT_GLOROT_UNIFORM | 权重的初始化器 | |
| GELU | 激活函数 |
- 模型很重要的性质就是非线性,同时为了模型泛化能力,需要加入随机正则,例如dropout(随机置一些输出为0,其实也是一种变相的随机非线性激活)
- epsilon 值在机器学习中,层归一化是一种归一化技术,用于在神经网络的每个层中标准化输入。这有助于加速训练并提高模型的准确性。它的作用是防止分母为零,从而避免数值计算不稳定。通常设置为 1e-5 或 1e-6。
模型
keras的交叉验证时,例如你用5折,对于fold_0,fold_1…一直到fold_4.都应该有一个独立的模型。所以在每折的开头都需要加上clear_session()。否则上一折的训练集成了这一折的验证集,数据泄露。
tf.keras.backend.clear_session()
model = get_model()
这段代码是一个 TensorFlow 模型的实现。 它有两个输入,分别是 “frames” 和 “non_empty_frame_idxs”。 在这个模型中,frames 是一个包含多个帧的视频数据,而 non_empty_frame_idxs 表示在 frames 中哪些帧是有内容的。 在这段代码中,将通过遮盖(masking)操作来选择具有有效帧的位置,以便只对这些帧进行训练。 此模型使用了 Transformer 架构,它可以通过将多个带有注意力机制的层组合在一起来处理输入。 在这个模型中,每个帧都被嵌入到三个不同的表示中,分别为 LIPS、LEFT HAND 和 POSE,这些表示被用于构建 Transformer 的输入。 在这个模型中,还实现了一些额外的技巧,如随机帧屏蔽、类别丢失(分类时丢失部分特征),以及标签平滑等。 最后,这个模型还包括一个优化器和一些评估指标。优化器使用 AdamW,而评估指标包括稀疏分类精度、稀疏分类前 k 个的精度等。
Encoder部分是N个相同结构的堆叠,每个结构中又可以细分为如下结构:
- 对输入 one-hot 编码的样本进行 embedding(词嵌入)
- 加入位置编码
- 引入多头机制的 Self-Attention
- 将 self-attention 的输入和输出相加(残差网络结构)
- Layer Normalization(层标准化),对所有时刻的数据进行标准化
前馈型神经网络(Feedforword)结构 - 将 Feedforword 的输入和输出相加(残差网络结构)
- Layer Normalization,对所有时刻的数据进行标准化
- 重复N层3-8的结构
Decoder部分同样也是N个相同结构的堆叠,每个结构中又可以细分为如下结构:
- 对输入 one-hot 编码的样本进行 embedding(词嵌入)
- 加入位置编码
- 引入多头机制的 Self-Attention
- 将 self-attention 的输入和输出相加(残差网络结构)
- Layer Normalization(层标准化),
- 对所有时刻的数据进行标准化将上一步得到的只作为value,并和编码器端得到 q和k进行Self-Attenton
- 将 self-attention 的输入和输出相加(残差网络结构)
- Layer Normalization(层标准化),对所有时刻的数据进行标准化
- 前馈型神经网络(Feedforword) 结构
- 将 Feedforword 的输入和输出相加(残差网络结构)
- Layer Normalization,对所有时刻的数据进行标准化
- 重复N层3-11的结构
def get_model():
# Inputs
frames = tf.keras.layers.Input([INPUT_SIZE, N_COLS, N_DIMS], dtype=tf.float32, name='frames')
non_empty_frame_idxs = tf.keras.layers.Input([INPUT_SIZE], dtype=tf.float32, name='non_empty_frame_idxs')
# Padding Mask
mask0 = tf.cast(tf.math.not_equal(non_empty_frame_idxs, -1), tf.float32)
mask0 = tf.expand_dims(mask0, axis=2)
# Random Frame Masking
mask = tf.where(
(tf.random.uniform(tf.shape(mask0)) > 0.25) & tf.math.not_equal(mask0, 0.0),
1.0,
0.0,
)
# Correct Samples Which are all masked now...
mask = tf.where(
tf.math.equal(tf.reduce_sum(mask, axis=[1,2], keepdims=True), 0.0),
mask0,
mask,
)
"""
left_hand: 468:489
pose: 489:522
right_hand: 522:543
"""
x = frames
x = tf.slice(x, [0,0,0,0], [-1,INPUT_SIZE, N_COLS, 2])
# LIPS
lips = tf.slice(x, [0,0,LIPS_START,0], [-1,INPUT_SIZE, 40, 2])
lips = tf.where(
tf.math.equal(lips, 0.0),
0.0,
(lips - LIPS_MEAN) / LIPS_STD,
)
# LEFT HAND
left_hand = tf.slice(x, [0,0,40,0], [-1,INPUT_SIZE, 21, 2])
left_hand = tf.where(
tf.math.equal(left_hand, 0.0),
0.0,
(left_hand - LEFT_HANDS_MEAN) / LEFT_HANDS_STD,
)
# POSE
pose = tf.slice(x, [0,0,61,0], [-1,INPUT_SIZE, 5, 2])
pose = tf.where(
tf.math.equal(pose, 0.0),
0.0,
(pose - POSE_MEAN) / POSE_STD,
)
# Flatten
lips = tf.reshape(lips, [-1, INPUT_SIZE, 40*2])
left_hand = tf.reshape(left_hand, [-1, INPUT_SIZE, 21*2])
pose = tf.reshape(pose, [-1, INPUT_SIZE, 5*2])
# Embedding
x = Embedding()(lips, left_hand, pose, non_empty_frame_idxs)
# Encoder Transformer Blocks
x = Transformer(NUM_BLOCKS)(x, mask)
# Pooling
x = tf.reduce_sum(x * mask, axis=1) / tf.reduce_sum(mask, axis=1)
# Classifier Dropout
x = tf.keras.layers.Dropout(CLASSIFIER_DROPOUT_RATIO)(x)
# Classification Layer
x = tf.keras.layers.Dense(NUM_CLASSES, activation=tf.keras.activations.softmax, kernel_initializer=INIT_GLOROT_UNIFORM)(x)
outputs = x
# Create Tensorflow Model
model = tf.keras.models.Model(inputs=[frames, non_empty_frame_idxs], outputs=outputs)
# Sparse Categorical Cross Entropy With Label Smoothing
loss = scce_with_ls
#SGDW是一种优化器,它是基于SGD的,但是加入了动量的概念。
#动量的作用是在更新参数时,不仅仅减去了当前迭代的梯度,还减去了前t-1迭代的梯度的加权和。
#这样做的好处是可以让参数更新更加平滑,避免了在参数更新过程中出现震荡的情况。
#optimizer = tfa.optimizers.SGDW(
#learning_rate=lr, weight_decay=wd, momentum=0.9)
#optimizer = tf.keras.optimizers.SGD(lr=0.001, momentum=0.0, nesterov=False)
#optimizer = tfa.optimizers.SGDW(learning_rate=0.001, momentum=0.7, weight_decay=0.005)
#Adam Optimizer with weight decay
optimizer = tfa.optimizers.AdamW(learning_rate=1e-3, weight_decay=1e-5, clipnorm=1.0)
#学习率为1e-3,权重衰减为1e-5,梯度裁剪阈值为1.0
# TopK Metrics
metrics = [
tf.keras.metrics.SparseCategoricalAccuracy(name='acc'),
tf.keras.metrics.SparseTopKCategoricalAccuracy(k=5, name='top_5_acc'),
tf.keras.metrics.SparseTopKCategoricalAccuracy(k=10, name='top_10_acc'),
]
model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
return model
class Embedding(tf.keras.Model):
def __init__(self):
super(Embedding, self).__init__()
def get_diffs(self, l):
S = l.shape[2]
other = tf.expand_dims(l, 3)
other = tf.repeat(other, S, axis=3)
other = tf.transpose(other, [0,1,3,2])
diffs = tf.expand_dims(l, 3) - other
diffs = tf.reshape(diffs, [-1, INPUT_SIZE, S*S])
return diffs
def build(self, input_shape):
# Positional Embedding, initialized with zeros
self.positional_embedding = tf.keras.layers.Embedding(INPUT_SIZE+1, UNITS, embeddings_initializer=INIT_ZEROS)
# Embedding layer for Landmarks
self.lips_embedding = LandmarkEmbedding(LIPS_UNITS, 'lips')
self.left_hand_embedding = LandmarkEmbedding(HANDS_UNITS, 'left_hand')
self.pose_embedding = LandmarkEmbedding(POSE_UNITS, 'pose')
# Landmark Weights
self.landmark_weights = tf.Variable(tf.zeros([3], dtype=tf.float32), name='landmark_weights')
# Fully Connected Layers for combined landmarks
self.fc = tf.keras.Sequential([
tf.keras.layers.Dense(UNITS, name='fully_connected_1', use_bias=False, kernel_initializer=INIT_GLOROT_UNIFORM),
tf.keras.layers.Activation(GELU),
tf.keras.layers.Dense(UNITS, name='fully_connected_2', use_bias=False, kernel_initializer=INIT_HE_UNIFORM),
], name='fc')
def call(self, lips0, left_hand0, pose0, non_empty_frame_idxs, training=False):
# Lips
lips_embedding = self.lips_embedding(lips0)
# Left Hand
left_hand_embedding = self.left_hand_embedding(left_hand0)
# Pose
pose_embedding = self.pose_embedding(pose0)
# Merge Embeddings of all landmarks with mean pooling
x = tf.stack((
lips_embedding, left_hand_embedding, pose_embedding,
), axis=3)
x = x * tf.nn.softmax(self.landmark_weights)
x = tf.reduce_sum(x, axis=3)
# Fully Connected Layers
x = self.fc(x)
# Add Positional Embedding
max_frame_idxs = tf.clip_by_value(
tf.reduce_max(non_empty_frame_idxs, axis=1, keepdims=True),
1,
np.PINF,
)
normalised_non_empty_frame_idxs = tf.where(
tf.math.equal(non_empty_frame_idxs, -1.0),
INPUT_SIZE,
tf.cast(
non_empty_frame_idxs / max_frame_idxs * INPUT_SIZE,
tf.int32,
),
)
x = x + self.positional_embedding(normalised_non_empty_frame_idxs)
return x
"Landmark"表示人脸的关键点,"Embedding"表示将这些关键点信息映射到低维向量空间的过程。因此,“Landmark Embedding"的中文意思可以理解为"将人脸关键点信息嵌入到低维向量空间中”。
Landmark Embedding是一种将人脸关键点信息转换为低维向量表示的方法。在人脸识别和人脸表情识别等任务中,Landmark Embedding通常用于提取人脸特征表示。
具体来说,Landmark Embedding通过对人脸图像中的关键点坐标进行处理,将其映射到一个低维空间中的向量表示。这个向量表示可以包含关于人脸形状、姿态和表情等信息,可以用于比较不同人脸之间的相似性或差异性。相比于直接使用像素信息或高维特征向量表示,Landmark Embedding可以提高人脸识别和表情识别的准确度和鲁棒性。
Dense层:全连接层
class LandmarkEmbedding(tf.keras.Model):
def __init__(self, units, name):
super(LandmarkEmbedding, self).__init__(name=f'{name}_embedding')
self.units = units
def build(self, input_shape):
# Embedding for missing landmark in frame, initizlied with zeros
self.empty_embedding = self.add_weight(
name=f'{self.name}_empty_embedding',
shape=[self.units],
initializer=INIT_ZEROS,
)
# Embedding
self.dense = tf.keras.Sequential([
tf.keras.layers.Dense(self.units, name=f'{self.name}_dense_1', use_bias=False, kernel_initializer=INIT_GLOROT_UNIFORM),
tf.keras.layers.Activation(GELU),
tf.keras.layers.Dense(self.units, name=f'{self.name}_dense_2', use_bias=False, kernel_initializer=INIT_HE_UNIFORM),
], name=f'{self.name}_dense')
def call(self, x):
return tf.where(
# Checks whether landmark is missing in frame
tf.reduce_sum(x, axis=2, keepdims=True) == 0,
# If so, the empty embedding is used
self.empty_embedding,
# Otherwise the landmark data is embedded
self.dense(x),
)
这是一个Python的Transformer模型,它是一个继承自tf.keras.Model的类。它有一个构造函数,其中num_blocks是一个整数,表示Transformer块的数量。在build函数中,它创建了多个Multi Head Attention和Multi Layer Perception对象,并将它们存储在类变量中。在call函数中,它迭代输入数据并将其传递给每个Transformer块。每个块都包含一个Multi Head Attention和一个Multi Layer Perception层。这个模型的目的是为了实现自然语言处理任务,如机器翻译、文本摘要等。
class Transformer(tf.keras.Model):
def __init__(self, num_blocks):
super(Transformer, self).__init__(name='transformer')
self.num_blocks = num_blocks
def build(self, input_shape):
self.ln_1s = []
self.mhas = []
self.ln_2s = []
self.mlps = []
# Make Transformer Blocks
for i in range(self.num_blocks):
# Multi Head Attention
self.mhas.append(MultiHeadAttention(UNITS, 8))
# Multi Layer Perception
self.mlps.append(tf.keras.Sequential([
tf.keras.layers.Dense(UNITS * MLP_RATIO, activation=GELU, kernel_initializer=INIT_GLOROT_UNIFORM),
tf.keras.layers.Dropout(MLP_DROPOUT_RATIO),
tf.keras.layers.Dense(UNITS, kernel_initializer=INIT_HE_UNIFORM),
]))
def call(self, x, attention_mask):
# Iterate input over transformer blocks
for mha, mlp in zip(self.mhas, self.mlps):
x = x + mha(x, attention_mask)
x = x + mlp(x)
return x
这段代码是一个MultiHeadAttention的实现。它将输入张量x分别通过多个Dense层进行线性变换,然后将变换后的张量分别作为Q,K,V传入scaled_dot_product函数中,计算出多头注意力机制的输出。最后将多头注意力机制的输出拼接起来,再通过一个Dense层进行线性变换,得到最终的输出multi_head_attention。scaled_dot_product函数是计算Q.K^T的函数,其中Q,K,V分别为query,key,value矩阵,attention_mask是用于掩码的张量。softmax函数是用于计算softmax值的函数。
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self,d_model,num_of_heads):
super(MultiHeadAttention,self).__init__()
self.d_model = d_model
self.num_of_heads = num_of_heads
self.depth = d_model//num_of_heads
self.wq = [tf.keras.layers.Dense(self.depth) for i in range(num_of_heads)]
self.wk = [tf.keras.layers.Dense(self.depth) for i in range(num_of_heads)]
self.wv = [tf.keras.layers.Dense(self.depth) for i in range(num_of_heads)]
self.wo = tf.keras.layers.Dense(d_model)
self.softmax = tf.keras.layers.Softmax()
def call(self,x, attention_mask):
multi_attn = []
for i in range(self.num_of_heads):
Q = self.wq[i](x)
K = self.wk[i](x)
V = self.wv[i](x)
multi_attn.append(scaled_dot_product(Q,K,V, self.softmax, attention_mask))
multi_head = tf.concat(multi_attn,axis=-1)
multi_head_attention = self.wo(multi_head)
return multi_head_attention
scaled dot-product attention是Transformer模型中的一种Attention机制,它是一种计算Attention权重的方法。在这种方法中,Query和Key的点积被除以一个缩放因子,然后通过softmax函数进行归一化处理,最后与Value相乘得到Attention输出。
def scaled_dot_product(q,k,v, softmax, attention_mask):
#calculates Q . K(transpose)
qkt = tf.matmul(q,k,transpose_b=True)
#caculates scaling factor
dk = tf.math.sqrt(tf.cast(q.shape[-1],dtype=tf.float32))
scaled_qkt = qkt/dk
softmax = softmax(scaled_qkt, mask=attention_mask)
z = tf.matmul(softmax,v)
#shape: (m,Tx,depth), same shape as q,k,v
return z














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









