







@[toc]
简介
介绍
简介:推荐系统经过对年的发展,在电商、资讯、音乐等应用中成为了核心组件之一。
背景:信息的过载与用户对于需求不够明确。
概念:用户没有明确的需求且服务于用户的商品信息过载,则系统能过通过算法对商品进行有规则的排序。
推荐系统与搜索引擎的区别
| 搜索引擎 | 推荐系统 | |
|---|---|---|
| 行为方式 | 主动 | 被动 |
| 意图 | 明确 | 模糊 |
| 个性化 | 弱 | 强 |
| 流量分布 | 马太效应 | 长尾效应 |
| 目标 | 快速满足 | 持续服务 |
| 评估指标 | 简明 | 复杂 |
马太效应:一种强者愈强、弱者愈弱的现象。
长尾效应:从人们需求的角度来看,大多数的需求会集中在头部 —— 流行,而分布在尾部的需求是个性化的,零散的小量的需求。而这部分差异化的、少量的需求会在需求曲线上面形成一条长长的“尾巴” —— 长尾效应。
作用
- 高效连接用户和物品, 发现长尾商品;
- 留住用户和内容生产者, 实现商业目标。
工作原理
- 社会化推荐 向朋友咨询, 社会化推荐, 让好友给自己推荐物品;
- 基于内容的推荐 打开搜索引擎, 输入要购买的商品, 在看返回结果中还有什么商品是没有看过的;
- 基于流行度的推荐 查看购物排行榜;
- 基于协同过滤的推荐 找到和自己历史兴趣相似的用户, 看看他们最近在看什么电影。
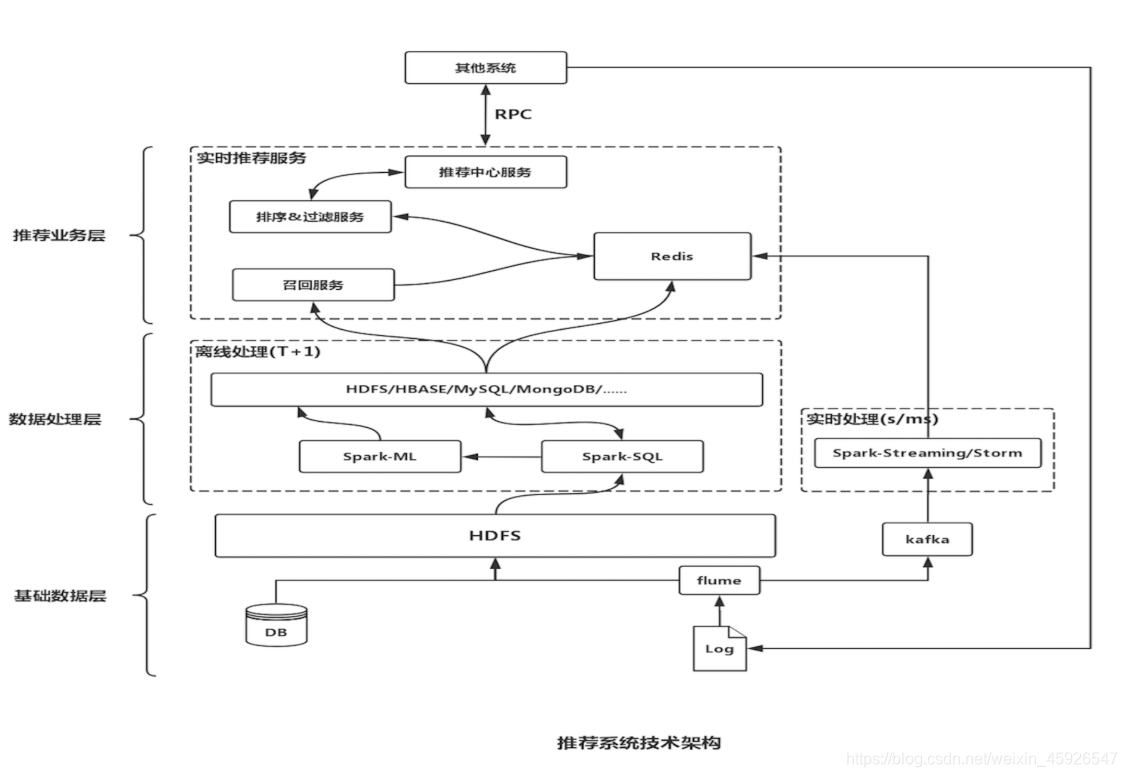
推荐系统的整体架构
架构图
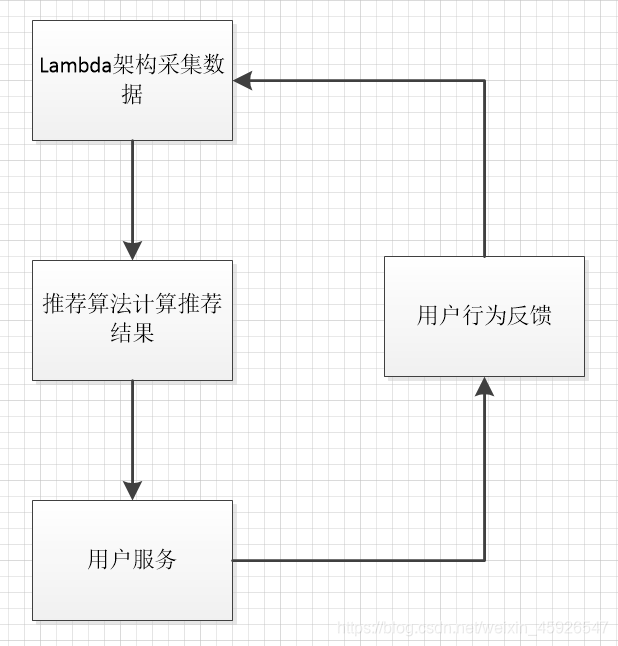
Lambda架构
由Twitter工程师Nathan Marz(storm项目发起人)提出。Lambda系统架构提供了一个结合实时数据和Hadoop预先计算的数据环境和混合平台, 提供一个实时的数据视图
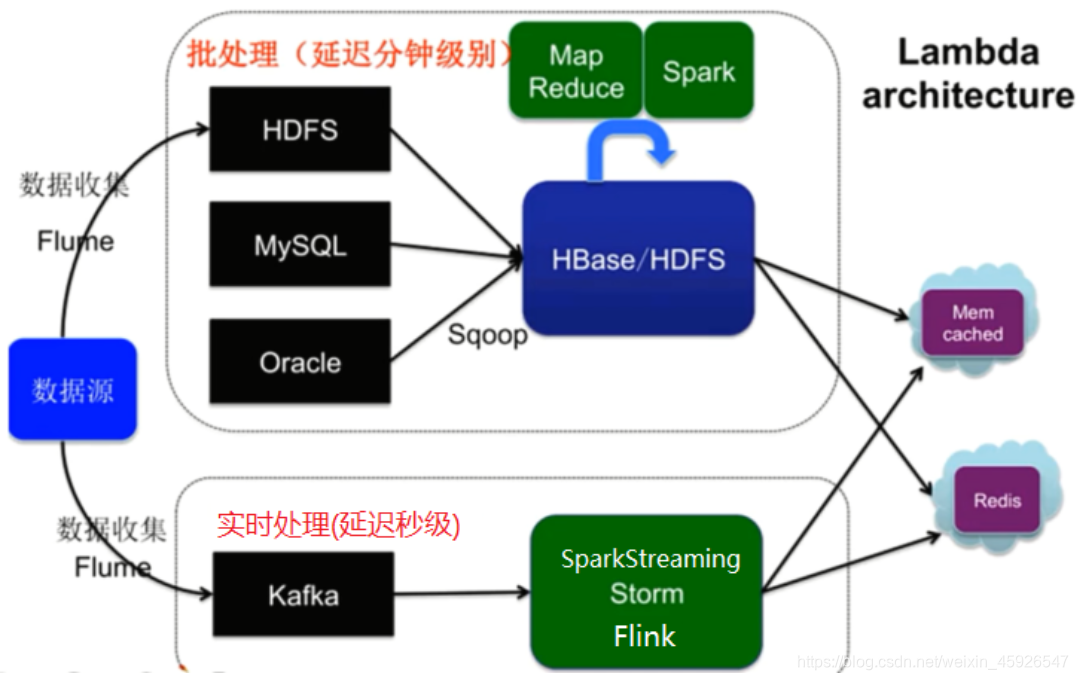
分层架构
批处理层
- 数据不可变, 可进行任何计算, 可水平扩展
- 高延迟 几分钟~几小时(计算量和数据量不同)
- 日志收集 Flume
- 分布式存储 Hadoop hdfs
- 分布式计算 Hadoop MapReduce & spark
- 视图存储数据库 --> [nosql(HBase/Cassandra), Redis/memcache, MySQL]
实时处理层
流式处理, 持续计算
- 存储和分析某个窗口期内的数据
- 最终正确性
- 实时数据收集 flume & kafka
- 实时数据分析 spark streaming/storm/flink
服务层
- 支持随机读
- 需要在非常短的时间内返回结果
- 读取批处理层和实时处理层结果并对其归并
lambda架构图
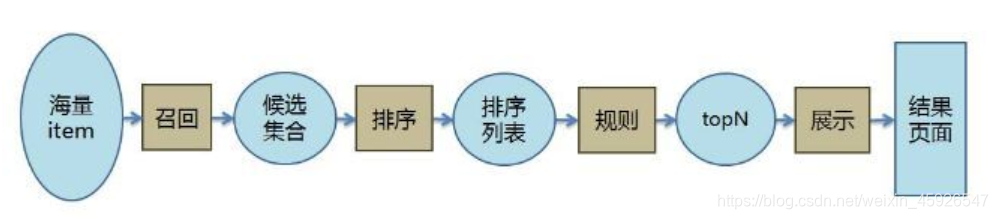
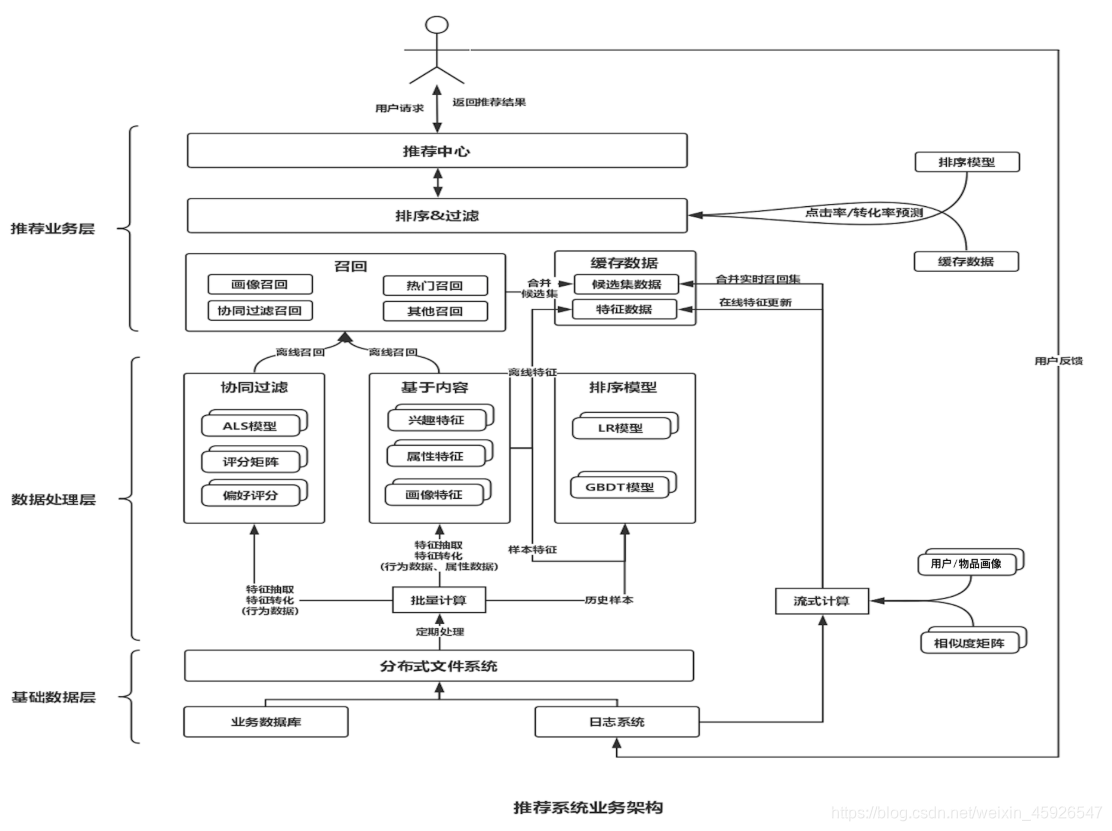
推荐算法架构
召回阶段
- 召回决定了最终推荐结果的天花板
- 常用算法: 协同过滤(基于用户 基于物品的);基于内容 (根据用户行为总结出自己的偏好 根据偏好 通过文本挖掘技术找到内容上相似的商品);基于隐语义
排序阶段
- 召回决定了最终推荐结果的天花板, 排序逼近这个极限, 决定了最终的推荐效果
- CTR预估 (点击率预估 使用LR算法) 估计用户是否会点击某个商品 需要用户的点击数据
策略调整
整体架构
推荐算法
推荐模型构建流程 数据清洗
数据清洗
数据来源
- 显性数据: Rating 打分 ; Comments 评论/评价
- 隐形数据:Order history 历史订单;Cart events 加购物车;Page views 页面浏览;Click-thru 点击; Search log 搜索记录
数据量/数据能否满足要求
特征工程
从数据中筛选特征
- 一个给定的商品,可能被拥有类似品味或需求的用户购买
- 使用用户行为数据描述商品
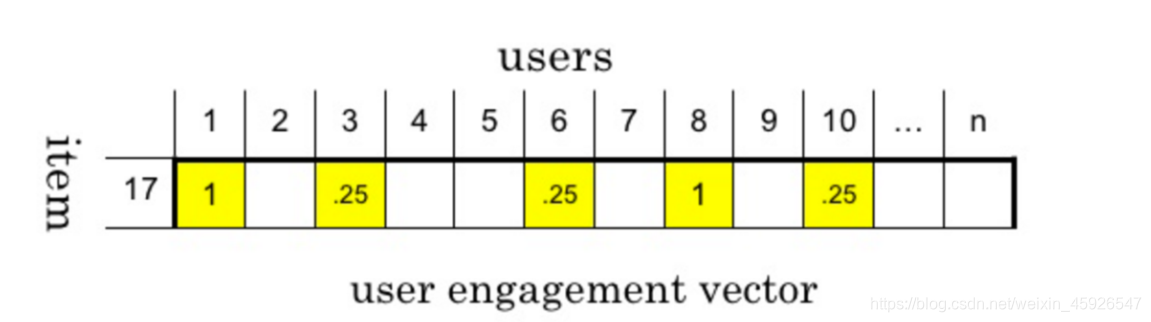
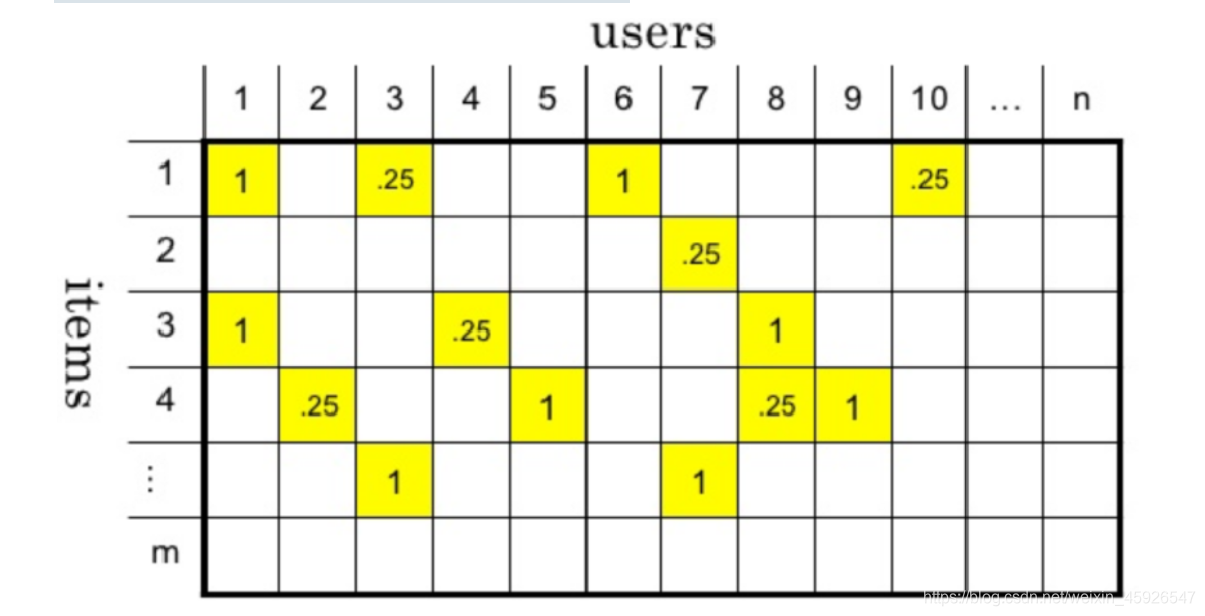
用数据表示特征
- 将所有用户行为合并在一起 ,形成一个user-item 矩阵
选择算法
产生推荐结果
协同过滤推荐算法(最为经典)
算法思想
物以类聚,人以群分
基本的协同过滤推荐算法基于该俩种假设
- “跟你喜好相似的人喜欢的东西你也很有可能喜欢” :基于用户的协同过滤推荐(User-based CF)
- “跟你喜欢的东西相似的东西你也很有可能喜欢 ”:基于物品的协同过滤推荐(Item-based CF)
实现协同过滤推荐有以下几个步骤
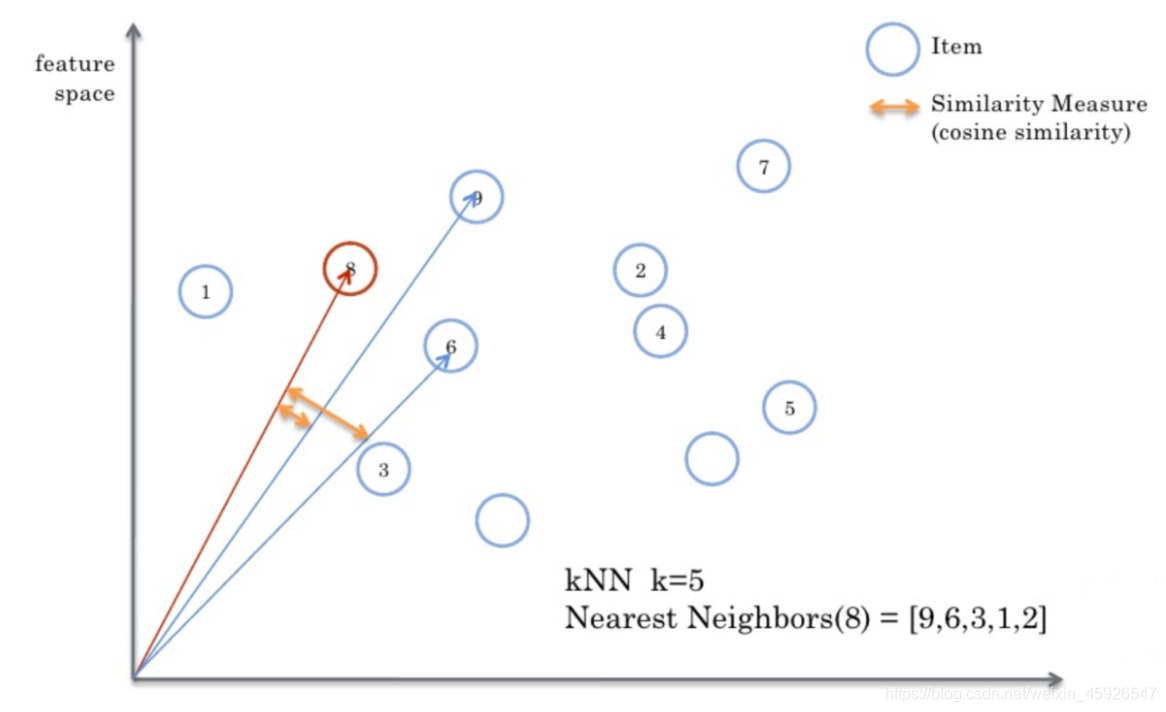
找出最相似的人或物品:TOP-N相似的人或物品:通过计算两两的相似度来进行排序,即可找出TOP-N相似的人或物品
根据相似的人或物品产生推荐结果:利用TOP-N结果生成初始推荐结果,然后过滤掉用户已经有过记录的物品或明确表示不感兴趣的物品
相似度计算

相似度的计算方法
数据分类
- 实数值(物品评分情况)
- 布尔值(用户的行为 是否点击 是否收藏)
欧氏距离:是一个欧式空间下度量距离的方法. 两个物体, 都在同一个空间下表示为两个点, 假如叫做p,q, 分别都是n个坐标, 那么欧式距离就是衡量这两个点之间的距离. 欧氏距离不适用于布尔向量之间
欧氏距离的值是一个非负数, 最大值正无穷, 通常计算相似度的结果希望是[-1,1]或[0,1]之间,一般可以使用
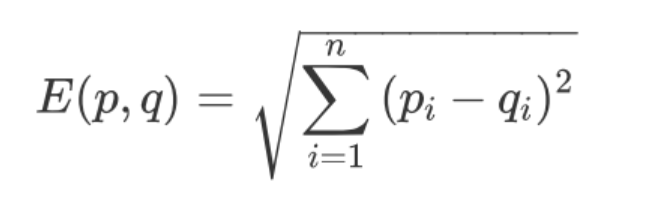

杰卡德相似度&余弦相似度&皮尔逊相关系数
余弦相似度
- 度量的是两个向量之间的夹角, 用夹角的余弦值来度量相似的情况
- 两个向量的夹角为0是,余弦值为1, 当夹角为90度是余弦值为0,为180度是余弦值为-1
- 余弦相似度在度量文本相似度, 用户相似度 物品相似度的时候较为常用
- 余弦相似度的特点, 与向量长度无关,余弦相似度计算要对向量长度归一化, 两个向量只要方向一致,无论程度强弱, 都可以视为’相似’
皮尔逊相关系数Pearson
- 实际上也是一种余弦相似度, 不过先对向量做了中心化, 向量a b 各自减去向量的均值后, 再计算余弦相似度
- 皮尔逊相似度计算结果在-1,1之间 -1表示负相关, 1表示正相关
- 度量两个变量是不是同增同减
- 皮尔逊相关系数度量的是两个变量的变化趋势是否一致, 不适合计算布尔值向量之间的相关度
杰卡德相似度 Jaccard
- 两个集合的交集元素个数在并集中所占的比例, 非常适用于布尔向量表示
- 分子是两个布尔向量做点积计算, 得到的就是交集元素的个数
- 分母是两个布尔向量做或运算, 再求元素和
- 余弦相似度适合用户评分数据(实数值), 杰卡德相似度适用于隐式反馈数据(0,1布尔值)(是否收藏,是否点击,是否加购物车)
余弦相似度
皮尔逊相关系数

计算出用户1和其它用户之间的相似度
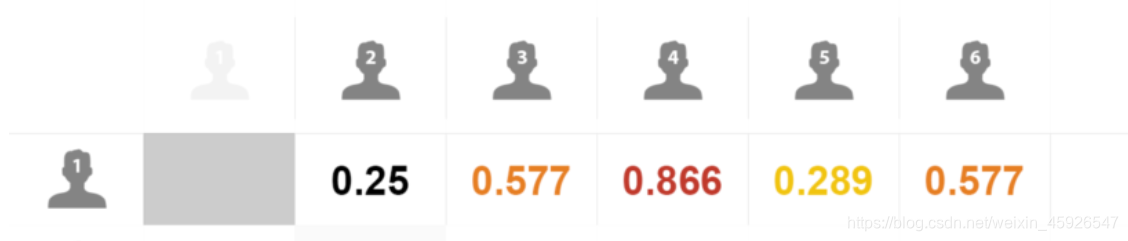
按照相似度大小排序, K近邻 如K取4: 1
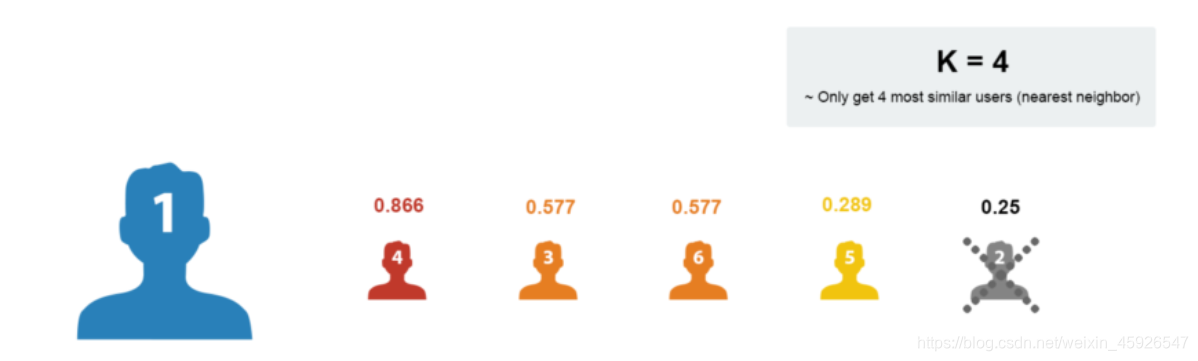
取出近邻用户的购物清单
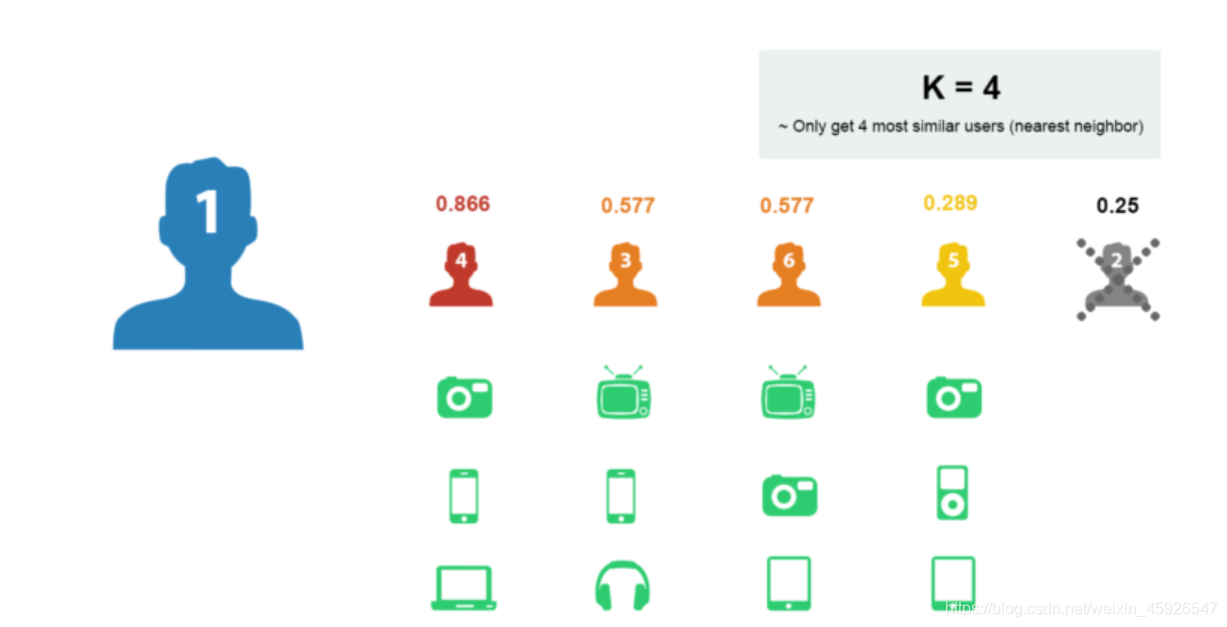
去除用户1已经购买过的商品
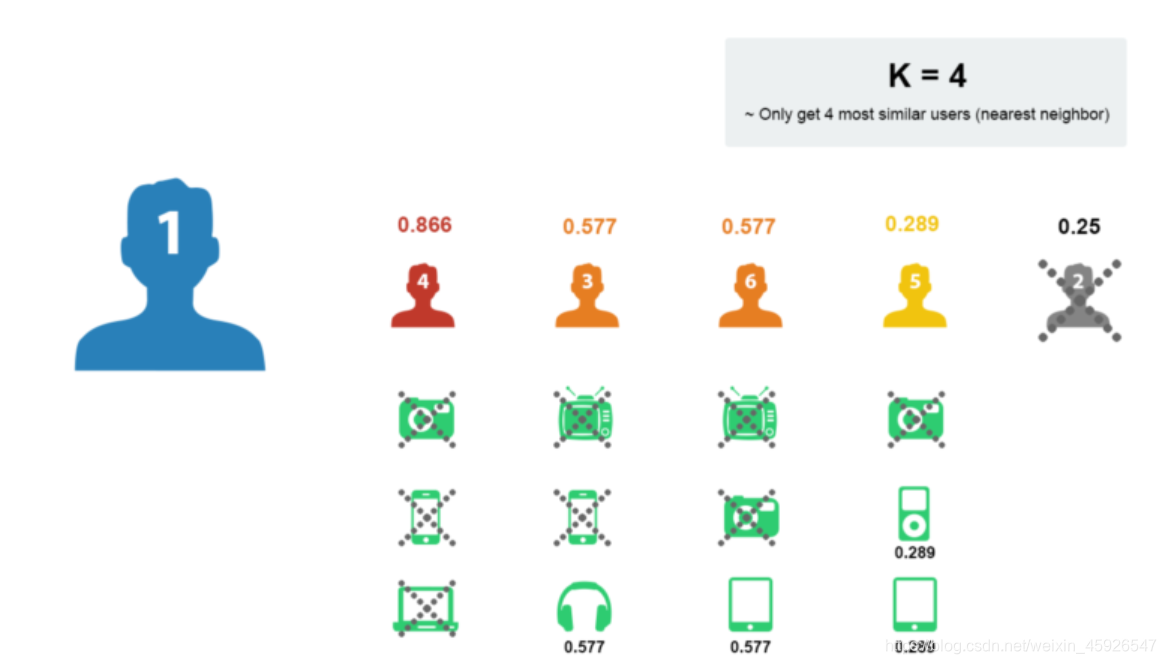
在剩余的物品中根据评分排序
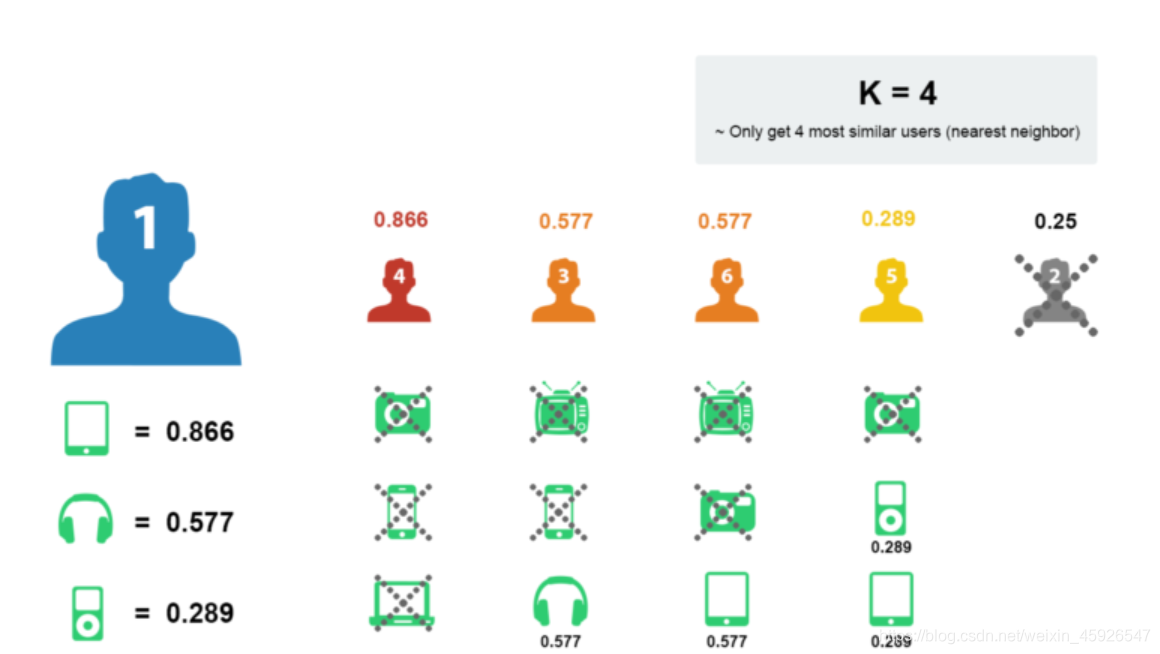
物品相似度计算
余弦相似度对绝对值大小不敏感带来的问题
- 用户A对两部电影评分分别是1分和2分, 用户B对同样这两部电影进行评分是4分,5分 用余弦相似度计算,两个用户的相似度达到0.98
- 可以采用改进的余弦相似度, 先计算向量每个维度上的均值, 然后每个向量在各个维度上都减去均值后,在计算余弦相似度, 用调整的余弦相似度计算得到的相似度是-0.1
基于模型的方法
思想:
通过机器学习算法,在数据中找出模式,并将用户与物品间的互动方式模式化;基于模型的协同过滤方式是构建协同过滤更高级的算法
近邻模型的问题
物品之间存在相关性, 信息量并不随着向量维度增加而线性增加;矩阵元素稀疏, 计算结果不稳定,增减一个向量维度, 导致近邻结果差异很大的情况存在
算法分类
基于图的模型;基于矩阵分解的方法
基于图的模型
基于邻域的模型看做基于图的模型的简单形式
原理
- 将用户的行为数据表示为二分图
- 基于二分图为用户进行推荐
- 根据两个顶点之间的路径数、路径长度和经过的顶点数来评价两个顶点的相关性
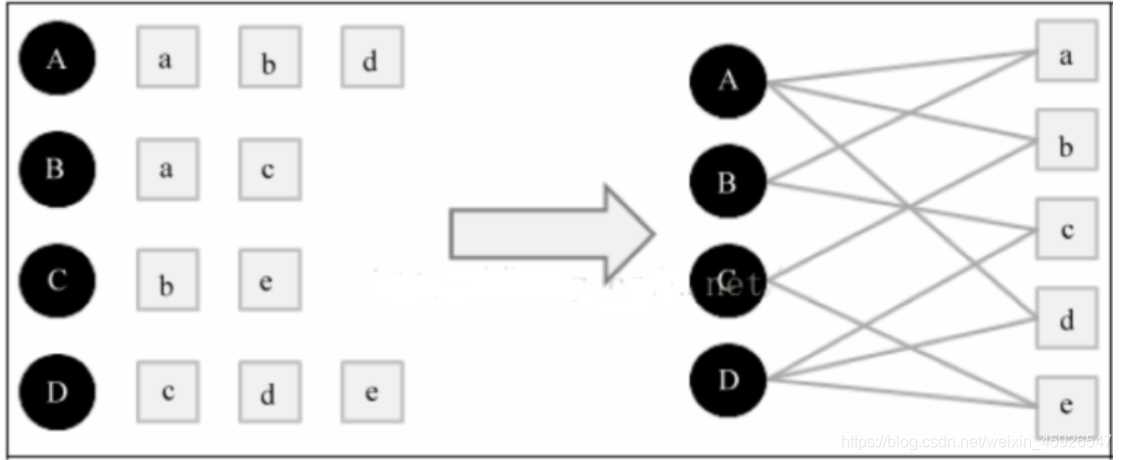
基于矩阵分解的模型
原理
- 根据用户与物品的潜在表现,我们就可以预测用户对未评分的物品的喜爱程度
- 把原来的大矩阵, 近似分解成两个小矩阵的乘积, 在实际推荐计算时不再使用大矩阵, 而是使用分解得到的两个小矩阵
- 用户-物品评分矩阵A是M X N维, 即一共有M个用户, n个物品 我们选一个很小的数 K (K<< M, K<<N)
- 通过计算得到两个矩阵U V U是M * K矩阵 , 矩阵V是 N * K
U m ∗ k V n ∗ k T 约 等 于 A m ∗ n U_{m*k} V^{T}_{n*k} 约等于 A_{m*n} Um∗kVn∗kT约等于Am∗n 类似这样的计算过程就是矩阵分解基于矩阵分解的方法
- ALS交替最小二乘:- ALS-WR(加权正则化交替最小二乘法): alternating-least-squares with weighted-λ –regularization; 将用户(user)对商品(item)的评分矩阵分解为两个矩阵:一个是用户对商品隐含特征的偏好矩阵,另一个是商品所包含的隐含特征的矩阵。在这个矩阵分解的过程中,评分缺失项得到了填充,也就是说我们可以基于这个填充的评分来给用户做商品推荐了。
- SVD奇异值分解矩阵
推荐系统评估
显示反馈和隐式反馈
| 显式反馈 | 隐式反馈 | |
|---|---|---|
| 例子 | 电影/书籍评分是否喜欢这个推荐 | 播放/点击 评论 下载 购买 |
| 准确性 | 高 | 低 |
| 数量 | 少 | 多 |
| 获取成本 | 高 | 低 |
常用评估指标
准确性、信任度、 满意度、实时性、覆盖率、鲁棒性、 多样性、可扩展性、新颖性、商业⽬标、惊喜度、⽤户留存
准确性 (理论角度) Netflix 美国录像带租赁
评分预测:RMSE MAE
topN推荐:召回率 精准率
准确性 (业务角度)
覆盖度
信息熵对于推荐越大越好; 覆盖率
多样性&新颖性&惊喜性
- 多样性:推荐列表中两两物品的不相似性。(相似性如何度量?
- 新颖性:未曾关注的类别、作者;推荐结果的平均流⾏度
- 惊喜性:历史不相似(惊)但很满意(喜)
- 往往需要牺牲准确性
- 使⽤历史⾏为预测⽤户对某个物品的喜爱程度
- 系统过度强调实时性
Exploitation & Exploration 探索与利用问题
- Exploitation(开发 利用):选择现在可能最佳的⽅案
- Exploration(探测 搜索):选择现在不确定的⼀些⽅案,但未来可能会有⾼收益的⽅案
- 在做两类决策的过程中,不断更新对所有决策的不确定性的认知,优化
长期的⽬标
EE问题实践
- 兴趣扩展: 相似话题, 搭配推荐
- 人群算法: userCF 用户聚类
- 平衡个性化推荐和热门推荐比例
- 随机丢弃用户行为历史
- 随机扰动模型参数
EE可能带来的问题
- 探索伤害用户体验, 可能导致用户流失
- 探索带来的长期收益(留存率)评估周期长, KPI压力大
- 如何平衡实时兴趣和长期兴趣
- 如何平衡短期产品体验和长期系统生态
- 如何平衡大众口味和小众需求
评估方法
- 问卷调查: 成本高
- 离线评估: 只能在用户看到过的候选集上做评估, 且跟线上真实效果存在偏差;只能评估少数指标;速度快, 不损害用户体验
- 在线评估: 灰度发布 & A/B测试 50% 全量上线
- 实践: 离线评估和在线评估结合, 定期做问卷调查















 9923
9923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











