










文章目录
PyG(PyTorch Geometric)是一个基于PyTorch的图神经网络框架,包含图神经网络训练中的数据集处理、多GPU训练、多个经典的图神经网络模型、多个常用的图神经网络训练数据集而且支持自建数据集,主要包含以下几个模块
- torch_geometric:主模块
- torch_geometric.nn:搭建图神经网络层
- torch_geometric.data:图结构数据的表示
- torch_geometric.loader:加载数据集
- torch_geometric.datasets:常用的图神经网络数据集
- torch_geometric.transforms:数据变换
- torch_geometric.utils:常用工具
- torch_geometric.graphgym:常用的图神经网络模型
- torch_geometric.profile:监督模型的训练
1. 介绍
1.1 图数据处理
图对节点和边进行建模。PyG 用 torch_geometric.data.Data 可以描述保存图结构数据,默认情况下包含以下属性:
- data.x:节点特征矩阵 [num_nodes, num_node_features]
- data.edge_index:COO格式的图节点连接信息,类型为torch.long [2,num_edges](具体包含两个列表,每个列表对应位置上的数字表示相应节点之间存在边连接)
- data.edge_attr:图的边特征矩阵 [num_edges, num_edge_features]
- data.y:标签信息,根据具体任务,维度是不一样的,如果是在节点上的分类任务,维度为[num_edges,类别数],如果是在整个图上的分类任务,维度为[1,类别数]
- data.pos:节点的位置信息 [num_nodes, num_dimensions],一般用于图结构数据的可视化
以上属性不是必要的,但是Data 对象也不限于这些属性。
- 例如,data.face:以保存具有形状和类型的张量中3D网格的三角形的连通性 [3, num_faces] torch.long类型
我们使用PyG表示下面这个图
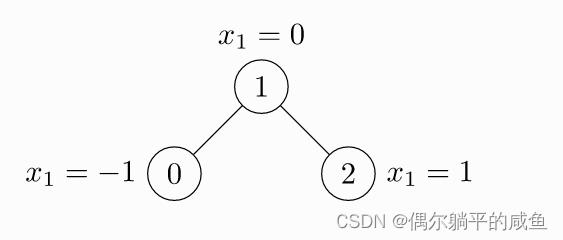
import torch
from torch_geometric.data import Data
# 边的连接信息 注意,无向图的边要定义两次
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
# edge_index = torch.tensor([[0, 1],[1, 0],
# [1, 2],[2, 1]], dtype=torch.long)
# 节点的属性信息
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
# 实例化为一个图结构的数据
data = Data(x=x, edge_index=edge_index)
# data = Data(x=x, edge_index=edge_index.t().contiguous())
1.2 常用的图神经网络数据集
PyG包含大量常见的基准数据集,例如
- Planetoid数据集(Cora,Citeseer,Pubmed)
- 来自 http://graphkernels.cs.tu-dortmund.de 的图形分类数据集
- QM7和QM9数据集
- 3D网格/点云数据集,如FAUST,ModelNet10/40和ShapeNet等
接下来拿ENZYMES数据集(包含600个图,每个图分为6个类别,图级别的分类)举例如何使用PyG的公共数据集
from torch_geometric.datasets import TUDataset
# 导入数据集
dataset = TUDataset(
# 指定数据集的存储位置 如果指定位置没有相应的数据集 PyG会自动下载
root='/tmp/ENZYMES',
# 要使用的数据集名称
name='ENZYMES')
# 数据集的长度
print(len(dataset))
# 数据集的类别数
print(dataset.num_classes)
# 数据集中节点属性向量的维度
print(dataset.num_node_features)
# 600个图,我们可以根据索引选择要使用哪个图
data = dataset[0]
# 是否为无向图
data.is_undirected()
# 随机打乱数据集的一种方法
perm = torch.randperm(len(dataset))
dataset = dataset[perm]
# 随机打乱数据集的另一种方法
dataset = dataset.shuffle()
1.3 使用batch加载数据集
PyG 通过创建稀疏块对角邻接矩阵并在节点维度中串联特征和标签矩阵,将数据集为我们指定的batch以批处理方式进行训练,且允许在一个批处理中的图拥有不同数量的节点和边。
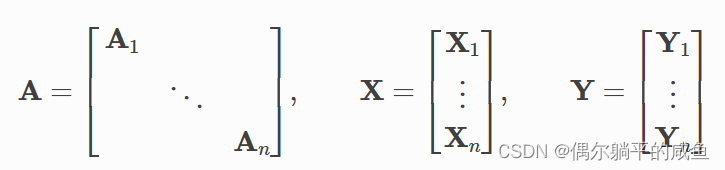
PyG中的torch_geometric.loader.DataLoader已经实现了过程,可以直接调用。例如:
from torch_geometric.datasets import TUDataset
from torch_geometric.loader import DataLoader
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES', use_node_attr=True)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for batch in loader:
batch
>>> DataBatch(batch=[1082], edge_index=[2, 4066], x=[1082, 21], y=[32])
batch.num_graphs
>>> 32
# 计算每个图的节点维度中的平均节点特征
x = scatter_mean(data.x, data.batch, dim=0)
x.size()
>>> torch.Size([32, 21])
batch是一个列向量,它将每个节点映射到批处理中图索引:
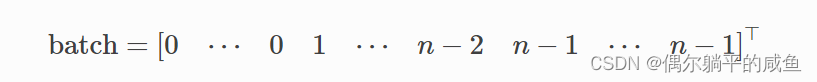
1.4 数据转换Data Transforms
Transforms是图转换和图增强的常用方法。
PyG 自带的转换需要 Data 对象作为输入,并返回新的转换后的 Data 对象。
可以使用torch_geometric.transforms.Compose将转换链接在一起,torchvision pre_transform transform。
例如,我们对ShapeNet 数据集(包含 17000 个 3D 形状点云和每个点来自16个形状类别的标签)应用转换
import torch_geometric.transforms as T
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],
# 我们可以通过变换从点云生成最近邻图,从而将点云数据集转换为图形数据集:
pre_transform=T.KNNGraph(k=6),
# 将每个节点位置转换一个小数
transform=T.RandomJitter(0.01))
dataset[0]
>>> Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
可以在torch_geometric.transforms上找到PyG中已实现转换的所有方法。
2. 建立消息传递MessagePassing网络
空域图卷积可以看作是相邻节点(和边)之间进行信息传递、融合的过程,计算公式可以一般化为
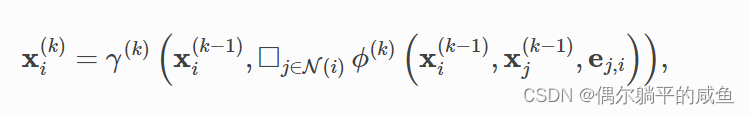

2.1 MessagePassing 基类
PyG 提供了 MessagePassing 基类,用户只需定义函数 message() 和 update() 以及聚合方式 aggr=“add”/“mean”/“max”。
- MessagePassing(aggr=“add”, flow=“source_to_target”, node_dim=-2):
定义聚合方式"add"“mean”“max” 、消息传递的流方向"source_to_target"“target_to_source” 以及该属性沿哪个轴传播node_dim - MessagePassing.propagate(edge_index, size=None, **kwargs):
开始传播消息的初始调用,接收边索引以及构造消息和更新节点嵌入所需的所有附加数据。
注意,propagate() 不仅限于在方形的邻接矩阵[N,N] 中交换消息,还可以通过作为附加参数传递来交换形状size=[N,M]的一般稀疏赋值矩阵(例如,二分图)中的消息。
size如果设置为 None,则假定赋值矩阵为正方形矩阵[N,N]。
对于具有两组独立节点和索引的二分图,并且每个组保存自己的信息,可以通过将信息作为元组传递来标记这种拆分,例如。x=(x_N, x_M) - MessagePassing.message(…):
为节点i构造消息,区分方向flow=“source_to_target”&flow=“target_to_source”。此外,传递给的张量可以映射到相应的节点,并通过附加或附加到变量名称。我们通常称为聚合信息的中心节点,并称为相邻节点,因为这是最常见的表示法。
更新节点嵌入,类似于每个节点。将聚合的输出作为第一个参数和最初传递给 propagate() 的任何参数。
对于以上计算过程,PyG利用MessagePassing进行实现。接下来以两篇经典图神经网络论文为例,介绍MessagePassing的使用。
Kipf和Welling的GCN层
Wang等人的EdgeConv层
2.2 GCN实现
在第一篇论文中,作者提出的GCN
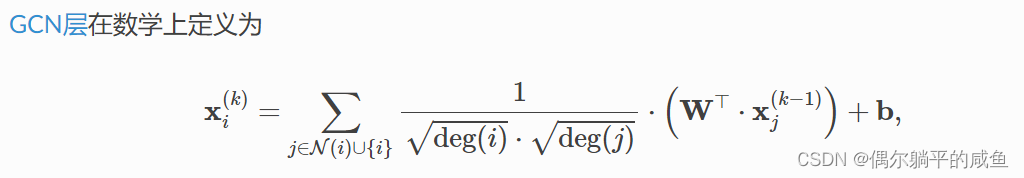
其中,相邻节点特征先进行线性变换,按其度数规范化,最后将所有信息相加,再将偏置向量应用于聚合输出得到当前节点的特征表示。
此公式可分为以下步骤:
①将自环添加到邻接矩阵。②线性变换节点特征矩阵。③计算归一化系数。
④规范化中的节点特征。⑤汇总相邻节点特征(add聚合)。⑥偏置向量相加。
步骤 ①-③ 通常在消息传递发生之前计算。步骤 ④-⑤ 可以使用 MessagePassing 基类处理。完整层实现如下所示:
import torch
from torch.nn import Linear, Parameter
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
# 定义GCN空域图卷积神经网络
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super().__init__(aggr='add') # "Add" 聚合操作 (Step 5).
self.lin = Linear(in_channels, out_channels, bias=False) # W'T
self.bias = Parameter(torch.Tensor(out_channels)) # 偏置项
self.reset_parameters()
def reset_parameters(self):
self.lin.reset_parameters()
self.bias.data.zero_()
def forward(self, x, edge_index):
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0)) # ①添加自环
x = self.lin(x) # ②线性变换
row, col = edge_index
deg = degree(col, x.size(0), dtype=x.dtype)
deg_inv_sqrt = deg.pow(-0.5)
deg_inv_sqrt[deg_inv_sqrt == float('inf')] = 0
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col] # ③ 标准化参数
# ④-⑤传递聚合信息 propagate会自动调用self.message函数,并将参数传递给它
out = self.propagate(edge_index, x=x, norm=norm)
out += self.bias # 使用偏置项
return out
def message(self, x_j, norm):
return norm.view(-1, 1) * x_j
2.3 Edge Convolution的实现
在第二篇论文中,边卷积层处理图形或点云,并在数学上定义为
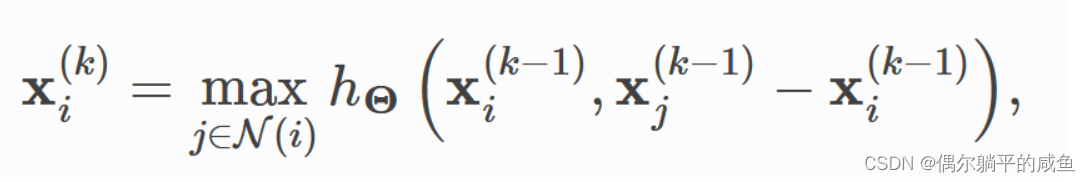
h
θ
h_{\theta}
hθ表示MLP,类似于GCN层,我们使用 MessagePassing 类实现该层,使用’sum‘聚合函数。
import torch
from torch.nn import Sequential as Seq, Linear, ReLU
from torch_geometric.nn import MessagePassing
class EdgeConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super().__init__(aggr='max') # "Max" aggregation.
self.mlp = Seq(Linear(2 * in_channels, out_channels),
ReLU(),
Linear(out_channels, out_channels))
def forward(self, x, edge_index):
return self.propagate(edge_index, x=x)
def message(self, x_i, x_j): # 信息汇聚函数
tmp = torch.cat([x_i, x_j - x_i], dim=1)
return self.mlp(tmp)
在 message() 函数中,我们用于转换每个边的目标节点特征和相对源节点特征。
边卷积实际上是一种动态卷积,它使用特征空间中的最近邻重新计算每个图层的图形。幸运的是,PyG附带了一个名为torch_geometric.nn.pool.knn_graph()的GPU加速批量k-NN图生成方法:
from torch_geometric.nn import knn_graph
class DynamicEdgeConv(EdgeConv):
def __init__(self, in_channels, out_channels, k=6):
super().__init__(in_channels, out_channels)
self.k = k
def forward(self, x, batch=None):
edge_index = knn_graph(x, self.k, batch, loop=False, flow=self.flow)
return super().forward(x, edge_index)
conv = DynamicEdgeConv(3, 128, k=6)
x = conv(x, batch)
3.创建自己的数据集
PyG将自建数据集分为两个文件夹:raw_dir、processed_dir。
row_dir是原始的数据集,processed_dir是PyG处理之后的数据集
对于数据集PyG有三种过滤方法—transform、pre_transform、pre_filter。
- transform:读取数据,然后对其进行变换
- pre_transform/pre_filter:对于整个数据集进行变换,然后将变换之后的数据进行存储
PyG为数据集提供了两个抽象类:
- torch_geometric.data.InMemoryDataset:能够完全放入内存中的
- torch_geometric.data.Dataset:不能够完全放入内存中的
- torch_geometric.data.InMemoryDataset 继承自 torch_geometric.data.Dataset,如果整个数据集适合 CPU 内存,则应使用torch_geometric.data.InMemoryDataset。
此外,每个数据集都可以传递transformpre_transformpre_filter函数,用于动态转换数据对象,默认为None。
3.1 创建一个能够完全放入内存中的图数据集InMemoryDataset
包含四种方法(可以在torch_geometric.data中找到下载和提取数据的有用方法。)
- 实现torch_geometric.data.InMemoryDataset.raw_file_names():
告诉PyG数据集放在哪里,即文件下载列表(raw_dir) - 实现torch_geometric.data.InMemoryDataset.processed_file_names():
告诉PyG数据集处理完之后放在哪里(processed_dir) - 实现torch_geometric.data.InMemoryDataset.download()
将原始数据下载到raw_dir中 - 实现torch_geometric.data.InMemoryDataset.process():
如何处理原始数据并将其保存到processed_dir中
通用模板:
import torch
from torch_geometric.data import InMemoryDataset, download_url
# 实现In Memory Dataset的通用模板
class MyDataset(InMemoryDataset):
# 初始化
def __init__(self, root, transfrom=None, pre_transform=None):
# root是数据集的根目录
super(MyDataset, self).__init__(root, transfrom, pre_transform)
# 加载数据集
self.data, self.slices = torch.load(self.processed_paths[0])
def raw_file_names(self) -> Union[str, List[str], Tuple]:
return ['file_1', 'file_2', ...]
def processed_file_names(self) -> Union[str, List[str], Tuple]:
return ['data.pt']
def download(self):
# 将数据集下载到raw_dir文件夹中
download_url(url, self.raw_dir)
def process(self):
data_list = [...]
# 进行数据过滤
if self.pre_filter is not None:
data_list = [data for data in data_list if self.pre_filter(data)]
if self.pre_transform is not None:
data_list = [self.pre_transform(data) for data in data_list]
# self.collate将所有数据组合在一起,加速存储
# data是组合之后的数据
# slices是分割方式,告诉PyG如何将data还原为原先的数据
data, slices = self.collate(data_list)
# 保存数据
torch.save((data, slices), self.processed_paths[0])
3.2 创建无法完全放入(更大的)内存的数据集Dataset
上面需要做的几件事的基础上还需要实现
- torch_geometric.data.Dataset.len():返回数据集中的示例数
- torch_geometric.data.Dataset.get():告诉PyG如何从数据集中获取一个数据
通用模板
import os.path as osp
import torch
from torch_geometric.data import Dataset, download_url
class MyDataset(Dataset):
# 初始化
def __init__(self, root, transform=None, pre_transform=None):
super(MyDataset, self).__init__(root, transform, pre_transform)
def raw_file_names(self) -> Union[str, List[str], Tuple]:
return ['file_1', 'file_2', ...]
def processed_file_names(self) -> Union[str, List[str], Tuple]:
return ['data_1.pt', ...]
def download(self):
path = download_url(url, self.raw_dir)
def process(self):
i = 0
for raw_path in self.raw_paths:
# 读取数据
data = Data(...)
# 过滤数据集
if self.pre_filter is not None and not self.pre_filter(data):
pass
if self.pre_transform is not None:
data = self.pre_transform(data)
# 保存数据
torch.save(data, osp.join(self.processed_dir, 'data_{}.pt'.format(i)))
i += 1
def len(self):
return len(self.processed_file_names)
def get(self,idx):
data = torch.load(osp.join(self.processed_dir, 'data_{}.pt'.format(idx)))
return data
在这里,每个图形数据对象都单独保存在 process() 中,并手动加载到 get() 中。
3.3 常见问题
如何跳过执行download()和process()?
您可以通过不重写download()和process()。
我真的需要使用这些数据集接口吗?
不!您不必使用数据集,例如,当您想要动态创建合成数据而不将其保存时。在这种情况下,只需传递一个包含torch_geometric.data.Data 对象的常规 python 列表,并将它们传递给 torch_geometric.loader.DataLoader:
from torch_geometric.data import Data
from torch_geometric.loader import DataLoader
data_list = [Data(...), ..., Data(...)]
loader = DataLoader(data_list, batch_size=32)
自己的例子
class MyOwnDataset(InMemoryDataset):
def __init__(self, root, transform=None, pre_transform=None, pre_filter=None):
super().__init__(root, transform, pre_transform, pre_filter)
self.data, self.slices = torch.load(self.processed_paths[0])
@property
def raw_file_names(self):
return ['DD_A.txt','DD_graph_indicator.txt','DD_graph_labels.txt','DD_node_labels.txt']
@property
def processed_file_names(self):
return ['data.pt']
def download(self):
pass
return
def process(self):
# Read data into huge `Data` list.
self.data, self.slices = read_tu_data(self.raw_dir,'DD')
if self.pre_filter is not None:
data_list = [self.get(idx) for idx in range(len(self))]
data_list = [data for data in data_list if self.pre_filter(data)]
data, slices = self.collate(data_list)
if self.pre_transform is not None:
data_list = [self.get(idx) for idx in range(len(self))]
data_list = [self.pre_transform(data) for data in data_list]
data, slices = self.collate(data_list)
torch.save((self.data, self.slices), self.processed_paths[0])
path = osp.join(osp.dirname(osp.abspath('')), 'DD')
dataset = MyOwnDataset(path)
data_loader = DataLoader(dataset, batch_size=128)
4. 异构图学习
前面讨论的图可以归为简单图—只包含一种类型的节点以及一种类型的边。
然而在现实中需要对多种类型(类似int、float、str等)的节点以及这些节点之间多种类型的边进行处理,这就需要异构图的概念,在异构图中,不同类型的边 描述不同类型节点之间 不同的关系,异构图神经网络的任务就是在这种图结构上学习出节点或者整个异构图的特征表示。异构图准确定义如下:
异构图(Heterogeneous Graphs):一个异构图G由一组节点 V = v 1 , v 2 , . . . . , v n V=v_1,v_2,....,v_n V=v1,v2,....,vn和一组边 E = e 1 , e 2 , . . . , e m E=e_1,e_2,...,e_m E=e1,e2,...,em组成,其中每个节点和每条边对应着一种类型,用 T v T_v Tv表示节点类型的集合 T e T_e Te表示边类型的集合,一个异构图有两个映射函数,分别将每个节点映射到其对应的类型 Φ v : V → T v Φ_v:V→T_v Φv:V→Tv,每条边映射到其对应的类型 Φ e : E → T e Φ_e:E→T_e Φe:E→Te

4.1 创建异构图
首先,我们可以创建一个torch_geometric.data.HeteroData类型的数据对象,为此我们为每个类型分别定义节点特征张量、边索引张量和边特征张量:
from torch_geometric.data import HeteroData
data = HeteroData()
data['paper'].x = ... # [num_papers, num_features_paper]
data['author'].x = ... # [num_authors, num_features_author]
data['institution'].x = ... # [num_institutions, num_features_institution]
data['field_of_study'].x = ... # [num_field, num_features_field]
data['paper', 'cites', 'paper'].edge_index = ... # [2, num_edges_cites]
data['author', 'writes', 'paper'].edge_index = ... # [2, num_edges_writes]
data['author', 'affiliated_with', 'institution'].edge_index = ... # [2, num_edges_affiliated]
data['paper', 'has_topic', 'field_of_study'].edge_index = ... # [2, num_edges_topic]
data['paper', 'cites', 'paper'].edge_attr = ... # [num_edges_cites, num_features_cites]
data['author', 'writes', 'paper'].edge_attr = ... # [num_edges_writes, num_features_writes]
data['author', 'affiliated_with', 'institution'].edge_attr = ... # [num_edges_affiliated, num_features_affiliated]
data['paper', 'has_topic', 'field_of_study'].edge_attr = ... # [num_edges_topic, num_features_topic]
节点或边张量将在首次访问时自动创建,并由字符串键编制索引。节点类型由单个字符串标识,而边类型则使用字符串的三元组进行标识:边缘类型标识符和边缘类型可以存在的两种节点类型。因此,数据对象允许每种类型的不同特征维度。(source_node_type, edge_type, destination_node_type)
包含按属性名称而不是按节点或边缘类型分组的异构信息的字典可以直接访问,并在以后用作GNN模型的输入:data.{attribute_name}_dict
model = HeteroGNN(…)
output = model(data.x_dict, data.edge_index_dict, data.edge_attr_dict)
















 2738
2738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











