







小鹿
- 一、决策树
- 二、相关概念
-
- 2.1 基尼指数
- 2.2 信息熵
- 三、ID3算法
-
- 3.1 概念
- 3.2 步骤
- 3.3 代码实现
- 四、C4.5算法
-
- 4.1 介绍
- 4.2 步骤
- 4.3 改动代码
- 五、CART算法
-
- 5.1 介绍
- 5.2 步骤
- 5.3 使用sklearn库实现
- 六、总结
- 七、参考
一、决策树
- 决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
- 决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
- 分类树(决策树)是一种十分常用的分类方法。它是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
优点:
- 决策树易于理解和实现,人们在在学习过程中不需要使用者了解很多的背景知识,这同时是它的能够直接体现数据的特点,只要通过解释后都有能力去理解决策树所表达的意义。
- 对于决策树,数据的准备往往是简单或者是不必要的,而且能够同时处理数据型和常规型属性,在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
- 易于通过静态测试来对模型进行评测,可以测定模型可信度;如果给定一个观察的模型,那么根据所产生的决策树很容易推出相应的逻辑表达式。
缺点:
- 对连续性的字段比较难预测。
- 对有时间顺序的数据,需要很多预处理的工作。
- 当类别太多时,错误可能就会增加的比较快。
- 一般的算法分类的时候,只是根据一个字段来分类。
二、相关概念
2.1 基尼指数
- 基尼指数(Gini不纯度)表示在样本集合中一个随机选中的样本被分错的概率。
- 注意:Gini指数越小表示集合中被选中的样本被参错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。当集合中所有样本为一个类时,基尼指数为0.
- 基尼指数的计算方法为:
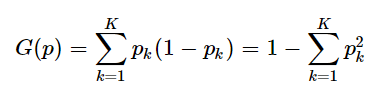
2.2 信息熵
- 所谓信息熵,是一个数学上颇为抽象的概念,在这里不妨把信息熵理解成某种特定信息的出现概率。而信息熵和热力学熵是紧密相关的。根据Charles H. Bennett对Maxwell’s Demon的重新解释,对信息的销毁是一个不可逆过程,所以销毁信息是符合热力学第二定律的。而产生信息,则是为系统引入负(热力学)熵的过程。所以信息熵的符号与热力学熵应该是相反的。
- 一般而言,当一种信息出现概率更高的时候,表明它被传播得更广泛,或者说,被引用的程度更高。我们可以认为,从信息传播的角度来看,信息熵可以表示信息的价值。这样子我们就有一个衡量信息价值高低的标准,可以做出关于知识流通问题的更多推论。
- 计算公式:
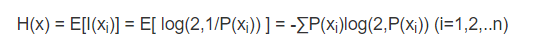
- 其中,x表示随机变量,与之相对应的是所有可能输出的集合,定义为符号集,随机变量的输出用x表示。P(x)表示输出概率函数。变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大.
三、ID3算法
3.1 概念
- ID3算法最早是由罗斯昆(J. Ross Quinlan)于1975年在悉尼大学提出的一种分类预测算法,算法的核心是“信息熵”。ID3算法通过计算每个属性的信息增益,认为信息增益高的是好属性,每次划分选取信息增益最高的属性为划分标准,重复这个过程,直至生成一个能完美分类训练样例的决策树。
3.2 步骤
- step1:计算出初始的信息熵,用上面的计算信息熵的公式
- step2:计算出每个特征的信息熵,这个的计算方法是先按照上面的公式计算出每个特征值的信息熵,再乘以特征值的占比相加就是该特征的熵,再赢开始计算的信息熵减去,就是信息增益,下图以色泽为例

- step3:按照信息增益的大小排序
- step4:选取最大的信息增益的特征,以此特征为划分结点
- step5:将该特征从特征列表删除,返回第四步继续划分,直到没有为止
3.3 代码实现
- 数据格式
色泽,根蒂,敲声,纹理,脐部,触感,好瓜
青绿,蜷缩,浊响,清晰,凹陷,硬滑,是
乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,是
乌黑,蜷缩,浊响,清晰,凹陷,硬滑,是
青绿,蜷缩,沉闷,清晰,凹陷,硬滑,是
浅白,蜷缩,浊响,清晰,凹陷,硬滑,是
青绿,稍蜷,浊响,清晰,稍凹,软粘,是
乌黑,稍蜷,浊响,稍糊,稍凹,软粘,是
乌黑,稍蜷,浊响,清晰,稍凹,硬滑,是
乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,否
青绿,硬挺,清脆,清晰,平坦,软粘,否
浅白,硬挺,清脆,模糊,平坦,硬滑,否
浅白,蜷缩,浊响,模糊,平坦,软粘,否
青绿,稍蜷,浊响,稍糊,凹陷,硬滑,否
浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,否
乌黑,稍蜷,浊响,清晰,稍凹,软粘,否
浅白,蜷缩,浊响,模糊,平坦,硬滑,否
青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,否
- 导入包
import numpy as np
import pandas as pd
import math
import collections
- 导入数据
def import_data():
data = pd.read_csv('..\\source\\watermalon.txt')
data.head(10)
data=np.array(data).tolist()
# 特征值列表
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
# 特征对应的所有可能的情况
labels_full = {}
for i in range(len(labels)):
labelList = [example[i] for example in data]
uniqueLabel = set(labelList)
labels_full[labels[i]] = uniqueLabel
return data,labels,labels_full
- 调用函数获取数据
data,labels,labels_full=import_data()
- 计算初始的信息熵,就是不分类之前的信息熵值
def calcShannonEnt(dataSet):
"""
计算给定数据集的信息熵(香农熵)
:param dataSet:
:return:
"""
# 计算出数据集的总数
numEntries = len(dataSet)
# 用来统计标签
labelCounts = collections.defaultdict(int)
# 循环整个数据集,得到数据的分类标签
for featVec in dataSet:
# 得到当前的标签
currentLabel = featVec[-1]
# # 如果当前的标签不再标签集中,就添加进去(书中的写法)
# if currentLabel not in labelCounts.keys():
# labelCounts[currentLabel] = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9456
9456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









