







前言
虽然最近还是很忙工作,生活各种事。但是还是想抽空写一写这几个月学习分布式系统的小部分感想。
分布式系统的三个目标
对于做完MIT6.824lab后的我来说,对于总结分布式系统还是想从最初的lab1 introduction来起头。在一开始的introduction中,其实就提出了贯穿整个课程,也就是分布式系统设计核心的5个topic。
- Topic: fault tolerance
1000s of servers, big network -> always something broken We’d like to hide these failures from the application.
“High availability”: service continues despite failures Big idea: replicated servers. If one server crashes, can proceed using the other(s). Labs 2 and 3- Topic: consistency
General-purpose infrastructure needs well-defined behavior.E.g. "Get(k) yields the value from the most recent Put(k,v)."Achieving good behavior is hard! “Replica” servers are hard to keep identical.- Topic: performance
The goal: scalable throughput Nx servers -> Nx total throughput via parallel CPU, disk, net.
Scaling gets harder as N grows: Load imbalance. Slowest-of-N latency. Some things don’t speed up with N: initialization, interaction. Labs 1, 4- Topic: tradeoffs
Fault-tolerance, consistency, and performance are enemies. Fault tolerance and consistency require communication
e.g., send data to backup e.g., check if my data is up-to-date communication is often slow and non-scalable
Many designs provide only weak consistency, to gain speed. e.g. Get() does not yield the latest Put()!
Painful for application programmers but may be a good trade-off. We’ll see many design points in the consistency/performance spectrum.- Topic: implementation
RPC, threads, concurrency control, configuration.
The labs…
- 分别是容错,一致性,高性能,权衡关系,以及实现。因此从这也可以看出笔者认为的分布式系统实现的三个目标也就分别是:fault tolerance、consistency、performance。而这个也很像分布式中的CAP理论,C对应着一致性,A可用对应性能,P分区容错性对应容错。
- 而在CAP中一般也是要保证AP或者CP。因为在真正的系统中,就算出现了网络分区或部分节点crash整个系统都要继续运转下去。而在网络分区的状态下,节点之间不能同步状态,那么就需要客户端进行多份数据的复制,然后进行同步。这里笔者简单画了个图:
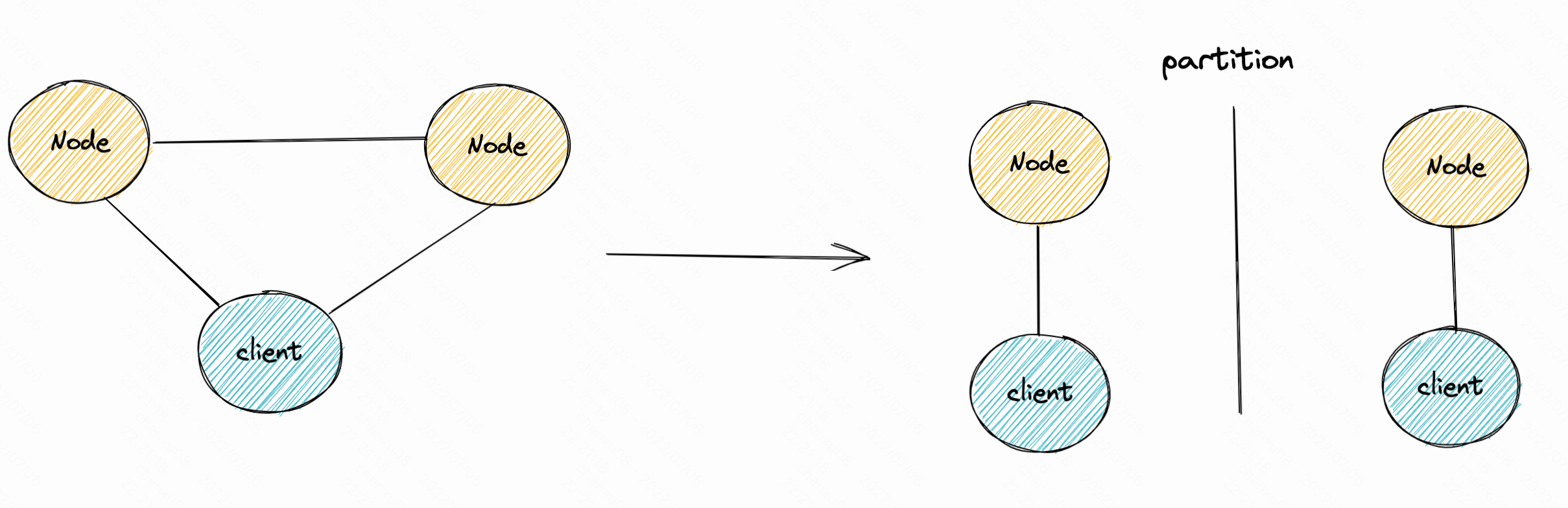
而这样复制,并分别发送RPC同步就会导致系统的得到一致的数据的时间就会变长。因此牺牲了性能而保证了一致性,当然牺牲一致性那就意味着不用同步,那么性能就会更快些,这也是为什么topic4就是权衡。- 而类似的讨论其实还有一个 FLP 不可能性 。 它是指在分布式异步通信中,没有任何算法能保证一致性。因为在分布式系统。而这的假设的情景更多是在最极端的情况,而这也是被推导证明的学术定理。
- 对于FLP第一次很多人听到这个结论或许会很惊讶,因为现实中已经存在了许多利用paxos,raft实现的分布式系统。 这是因为FLP 定理是学术定理,是遵循严格数学证明的,考虑的是最极端的情况,而 Paxos 算法是工程实践,学术上的极端性一般情况下很少发生,即便发生,多试几次可能就成功了。只要多耗费些合适的资源,最后基本就可以得到一个适合的结果。
也因此有句话是这样看待两者关系:
科学告诉你什么是不可能的;工程则告诉你,付出一些代价,我可以把它变成可能。这就是工程的魅力。
对于这句话笔者感觉很对,科学论证的东西可能大部分是非0即1,而工程带来的东西往往只是趋于稳定就行。
共识与一致性
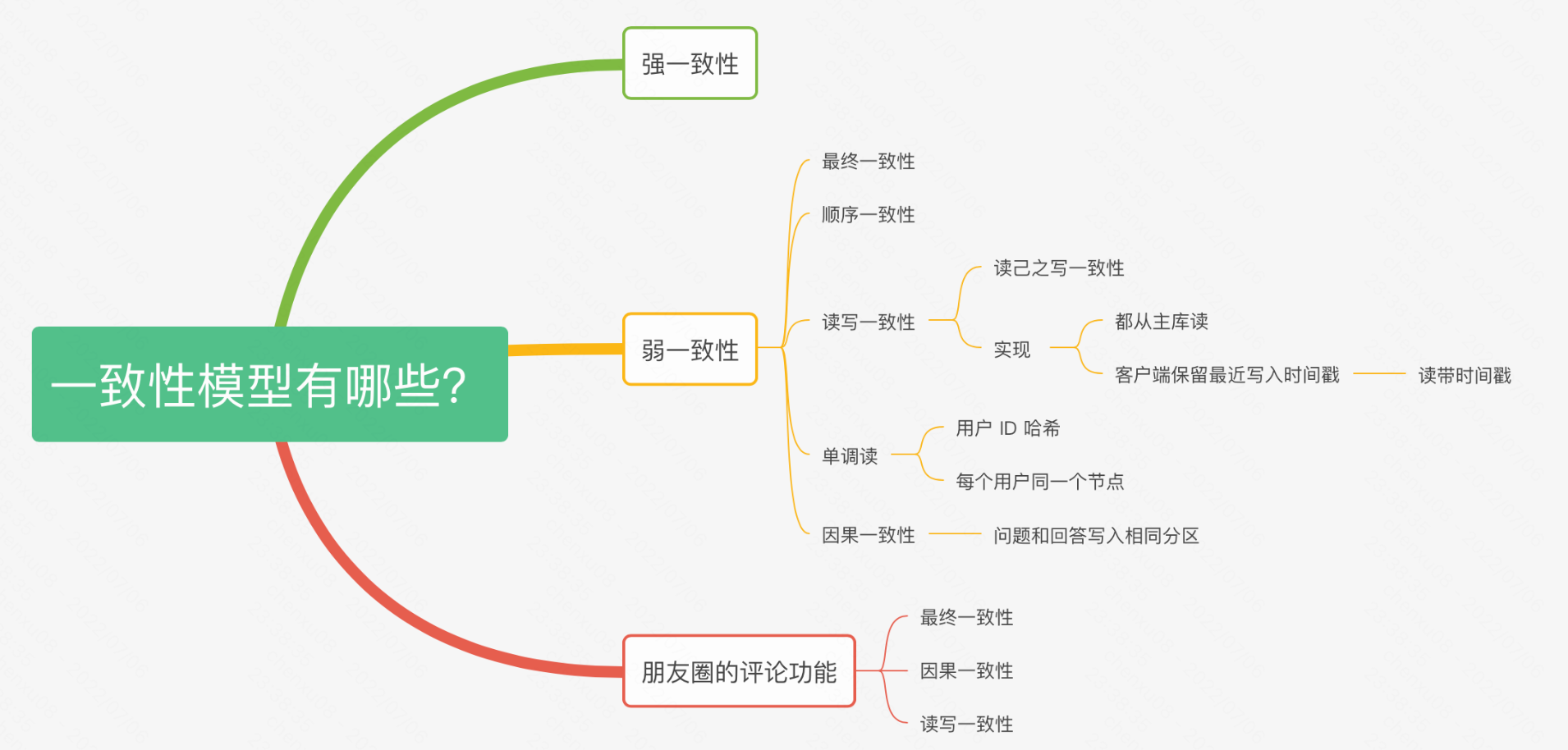
而提到raft、paxos则必然会提到共识的概念。共识的概念与一致性其实是不同的。一致性(Consistency)的含义比共识(consensus)要宽泛,一致性指的是多个副本对外呈现的状态。包括顺序一致性、线性一致性、最终一致性等。而共识特指达成一致的过程,拿raft来说,共识的过程就是leader的日志发送给follows进行同步状态,最后已相同的数据返回给client,在client眼里这些leader、followers就是一个大的状态机。也因此,共识只是一个状态同步的过程,而一致性是共识的目标,共识的结果也不一定会是一致性的(强一致性)。
















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











