









目录
📝论文下载地址
🔨代码下载地址
[GitHub-official-Tensorflow]
[GitHub-unofficial-Pytorch]
👨🎓论文作者
📦模型讲解
[背景介绍]
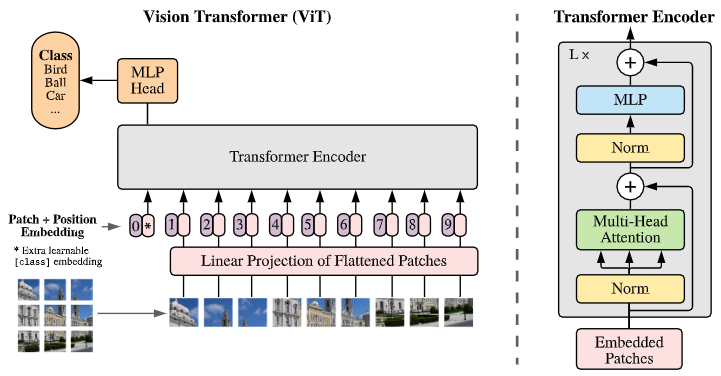
Transformer相关背景见[Transformer]。Transformer在处理计算机视觉任务取得不错的效果,但是始终没能超过卷积神经网络的相关方法。例如,针对图像识别任务的ViT网络,见下图。
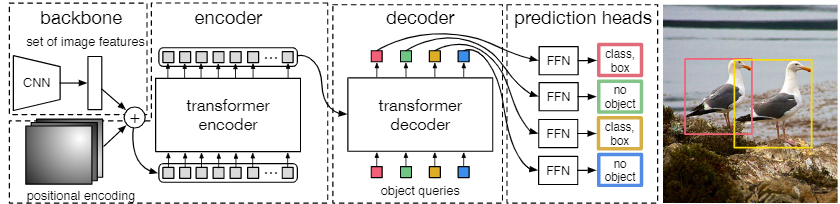
另外,针对图像目标检测任务的DETR网络,见下图。
目前大多数的针对CV的Transformer方法都是首先将输入图像拆分为补丁,补丁的处理方式与 NLP 应用程序中相同。然后使用几个自监督层进行全局的信息交流,提取特征进行分类。直到提出Swin的模型,才使得Transformer方法在CV领域成为SOTA。
[模型解读]
在本节中,作者提出了聚合嵌套的NesT模型,将Transformer用于图像识别任务。
[总体结构]
与Transformer用于NLP任务中相似,将图像看作句子,图像的切片看作单词。这里需要对论文中的一些单位进行实现声明:
I
m
a
g
e
/
图
Image/图
Image/图:表示输入网络(NesT)的整张图像
≈
\approx
≈ NLP中的文章。
B
l
o
c
k
/
块
Block/块
Block/块:表示输入网络(NesT)中某个Transformer的图像块
≈
\approx
≈ NLP中的某个句子。
P
a
t
c
h
/
切
片
Patch/切片
Patch/切片:表示输入Transformer中的图像块(Block)的切片
≈
\approx
≈ NLP中的某一个单词。
简单理解为,一张图像(Image)可以分为至少一个图像块(Block)。每个图像块(Block)可以分为至少一个图像切片(Patch)。在原先CV的Transformer方法,仅仅是一张图像(Image)可以分为至少一个图像切片(Patch)。所以上单位需满足(
S
S
S表示像素数目):
S
I
m
a
g
e
≤
S
B
l
o
c
k
≤
S
P
a
t
c
h
S_{Image} \le S_{Block} \le S_{Patch}
SImage≤SBlock≤SPatch
NesT的总体结构如下图所示,其中展示了3层NesT的网络结构:
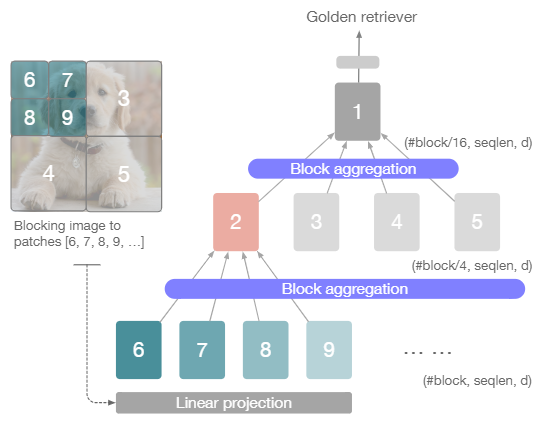
首先对整张图像(Image)分为多个图像块(Block),每一层的NesT都会将整张图像(Image)分为
(
2
i
)
2
(2^i)^2
(2i)2个图像块(Block),
i
i
i为层数开始于0。按照从大到小的顺序将图像块进行编号,第0层的图像块(Block)数目为0编号为1,第1层图像块(Block)的数目为4编号为2、3、4、5,由此类推。每一个图像块都会送入一系列Transformer的级联网络中进行特征提取,此过程与ViT相同,对图像块(Block)分为多个切片(Patch),送入Transformer中。
整个过程的伪代码见下图。

伪代码中对图像(Image)的分为图像块(Block)的顺序是相反的,作者是将图像(Image)先分为图像切片(Patch),再将图像切片(Patch)组合为图像块(Block)。首先对输入图像(input_image)进行切片与嵌入编码(PatchEmbed()),再进行组合(Block())生成图像块x,这里对应的是图像中的Linear projection。不考虑batch维度的情况下,x的维度是(#block,seqlen,d),#block为最浅层(第0层)分为图像块的数目,seqlen为图像块分为patch的数目,每一个patch都会嵌入编码为长度为d的特征。num_hierarchy为NesT的层数,这里共3层取3。所以图示网络中,最深的第3层共16个图像块,所以
#
b
l
o
c
k
=
16
\# block = 16
#block=16。T_i表示Transformer,每一个输入Transformer的x都会加上其位置编码PE_i。所有的图像块在Transformer后的特征都会进行拼接为一个总的特征。
当当前层的层数小于num_hierarchy - 1时会进行聚合(Aggregate())操作,也就是3层的网络在前两层特征提取完成后进行特征聚合(Aggregate())。特征聚合中首先对图像块进行UnBlock()也就是图像分块的相反操作,假设生成的特征z维度为(h,w,d),之后进行卷积归一与步长为2的最大池化操作,生成的特征z的维度为(h/2,w/2,d),最后再对z进行分块。输入聚合操作的特征维度为(#block, seqlen, d)聚合后输出的维度为(#block/4, seqlen, d)。
当当前层为最深层时,不会进行聚合操作。因为当前层只有1个图像块,维度为(1,seqlen,d)。之后与传统的卷积神经网络一样先全局平均池化后接全连接层,输出的维度为(num_classes,)。
网络中图像(Image)、图像块(Block)与图像切片(Patch)满足以下公式:
T
n
×
n
=
H
×
W
/
S
2
T_n \times n = H \times W /S^2
Tn×n=H×W/S2
其中,HW为输入图像(Image)的高宽,分为图像切片(Patch)的维度为
S
×
S
S \times S
S×S,那么等式的右边表示将整张图像分为图像切片的数目。等式的左侧中,
T
n
T_n
Tn表示最浅层(第0层)的图像块数目图示网络中
T
n
=
16
T_n=16
Tn=16,n就是seqlen表示每个图像块分为图像切片的数目,那么等式的左侧其实也表示整张图像分为图像切片的数目。
NesT中的Transformer与原始的Transformer相同,运算过程见下式。其中MSA为多头注意力,输入的qkv均是
x
′
x'
x′,归一化采用的LayerNorm。
multiple
×
{
y
=
x
+
M
S
A
N
e
s
T
(
x
′
,
x
′
,
x
′
)
,
where
x
′
=
L
N
(
x
)
x
=
y
+
F
F
N
(
L
N
(
y
)
)
\text { multiple } \times\left\{\begin{array}{l} y=x+\mathrm{MSA}_{\mathrm{NesT}}\left(x^{\prime}, x^{\prime}, x^{\prime}\right), \text { where } x^{\prime}=\mathrm{LN}(x) \\ x=y+\mathrm{FFN}(\mathrm{LN}(y)) \end{array}\right.
multiple ×{y=x+MSANesT(x′,x′,x′), where x′=LN(x)x=y+FFN(LN(y))
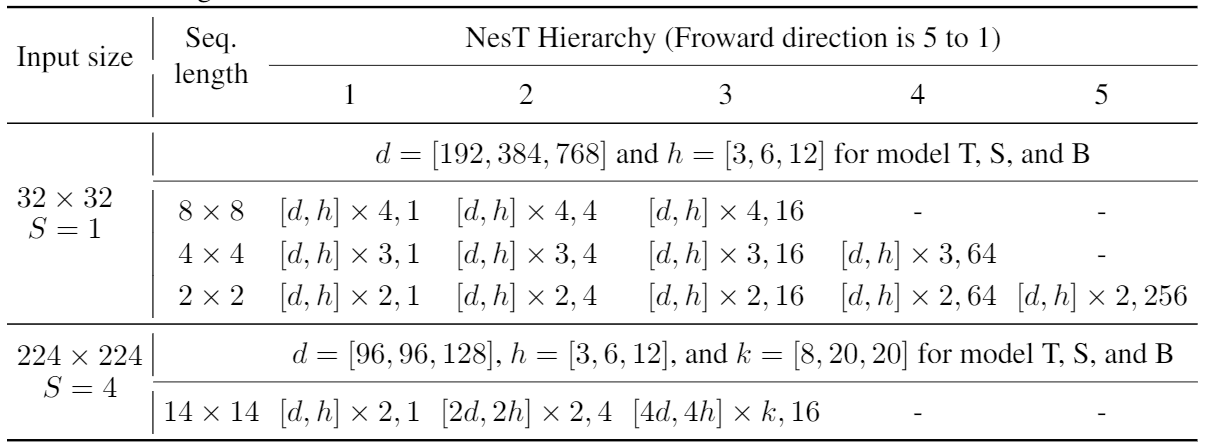
NesT网络的参数具体选取见上表。其中输入大小为32×32中,采用1×1的图像切片,设计3种网络结构,从小到大分别为T(Tiny)、S(Small)、B(Base)。例如Tiny网络,其有3层,每层参数由 [ d , h ] × a , b [d,h]\times a,b [d,h]×a,b表示,从浅到深包含b=16、b=4、b=1个图像块,每个图像块的seqlen为8×8,每个图像块输入a=4个Transformer的级联网络,每个Transformer的head=3,输入的特征尺寸为d=192。
[跨图像块混合信息的区块聚合]
这里作者给出了对于特征区块聚合的更详细的信息,具体的流程如下图所示,这里作者以第0层与第1层之间的特征区块聚合为例。

第0层会将输入图像分为16个图像块分别送入16个多Transformer级联网络中,输出的特征维度为(16,seqlen,d),如下图最左侧上方共16个特征每个特征所对应于原图的位置如最左侧下方所示,这也是UnBlock()的操作,将所分的16个图像块重新组合为原图。之后第一个操作是进行区块层面的卷积,对应第1层4个图像块位置上分别进行卷积核为3,步长为1,padding为1的卷积操作。第二步,在全图层面的卷积,同样是卷积核为3,步长为1,padding为1的卷积操作。归一化操作后,进行步长为2的3×3范围的最大值池化,将特征进行2×2的下采样。最后进行图像分块,按照第1层的4个图像块进行分块。整个过程输出为下图最右侧上方的特征维度为(4,seqlen,d)。
[运用NesT的图像生成]
作者提出了对NesT的另一种应用场景,即将NesT颠倒过来,通过输入噪声获取全尺寸的图像。相对于正常的NesT,只有其中的区块聚合操作需要进行修改。将其中的下采样改为4倍的上采样。整个过程的特征维度变化为 ( b , n d ) → ( b , 1 , n , d ) → ( b , 1 , n , d ) → ( b , 4 , n , d ′ ) , . . . , → ( b , # b l o c k , n , 3 ) (b,nd) \rightarrow (b,1,n,d) \rightarrow (b,1,n,d) \rightarrow (b,4,n,d') ,..., \rightarrow (b,\# block,n,3) (b,nd)→(b,1,n,d)→(b,1,n,d)→(b,4,n,d′),...,→(b,#block,n,3)。Block的数目同样以4倍增长。最终可以将特征进行UnBlock生成 H × W × 3 H\times W\times 3 H×W×3的图像。以此作为生成器,加入判别器即可作为生成对抗网络进行训练进行图像生成。

[通过可视化树对NesT进行可解释性分析]
NesT具有特殊的流程,可以按照树的思想去找图像中对于分类贡献最大的区域。作者提出一种基于遍历树的 GradCAT算法,可以找到对分类最据价值的子节点。

其中 # b l o c k / 4 ( T d − 1 ) = 1 \# block / 4^{(T_d-1)}=1 #block/4(Td−1)=1,对于三层的NesT来说, T d = 3 T_d=3 Td=3。简单来说,在树中从上到下不断选取对分类贡献梯度最高的区域。作者针对 h ^ l \hat h_l h^l进行可视化对比:
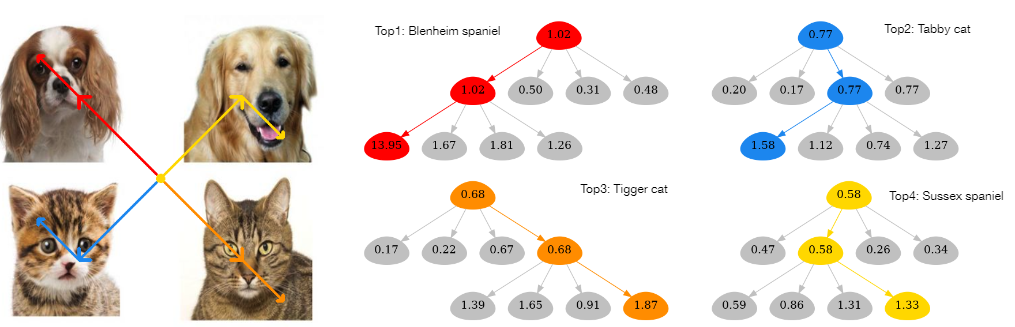
这里输入的图片包含四种动物,分别分布在图像的四个,选取某一类的分类置信度,按照树自上而下选取最大贡献的区域就可以定位图像中对应类别的区域。
[结果分析]
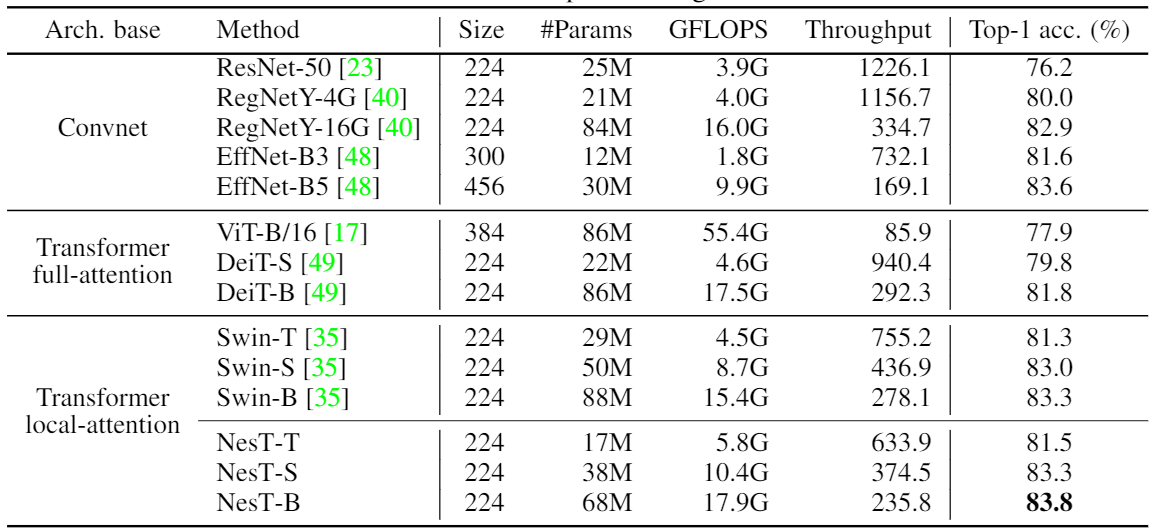
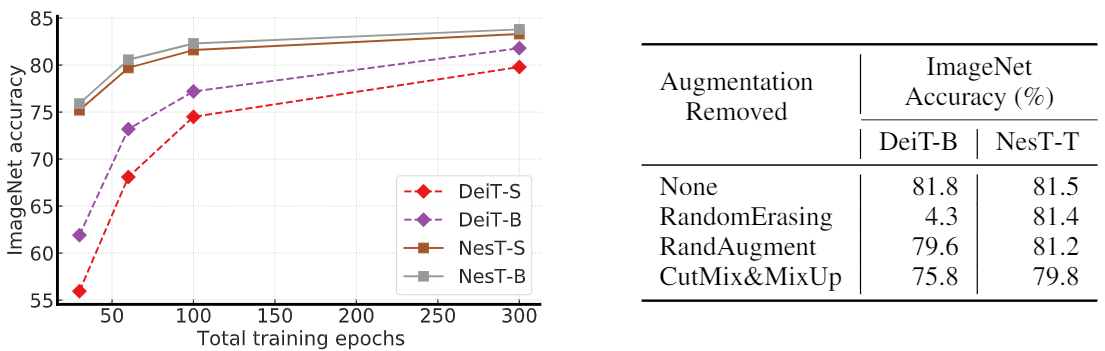
[在ImageNet数据集上与其他方法对比]
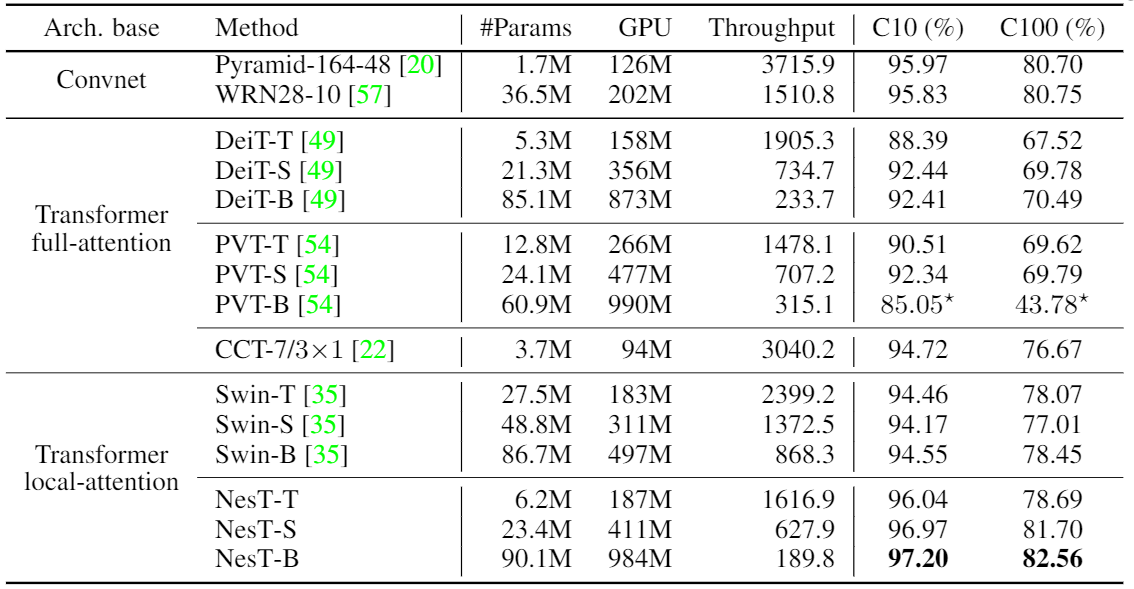
[在CIFAR数据集上与其他方法对比]
[消融实验]
[不同的聚合操作]
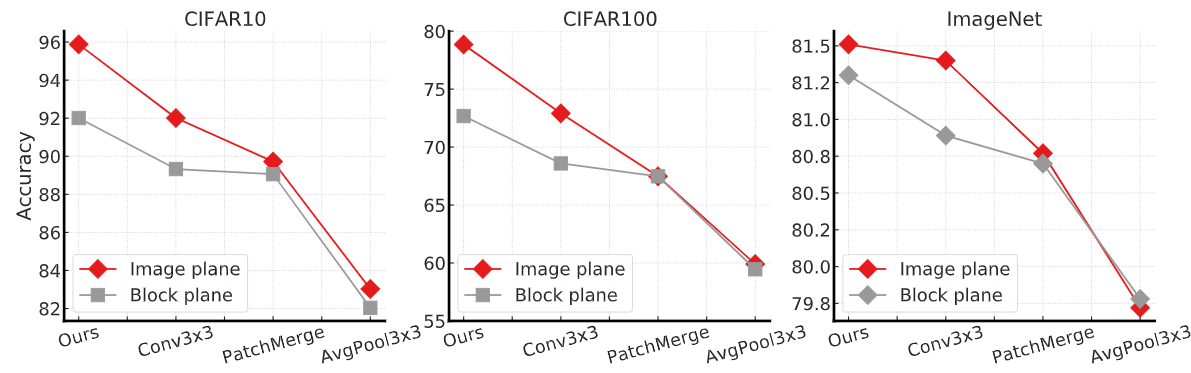
[不同的图像切片大小、网络深度、网络结构]
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









