






1、简介
借助PaddleHub-Serving,可以将PaddleX的Inference Model进行快速部署,以提供在线预测的能力。现在我们开始来安装paddlepaddle、paddleX、paddleHub。
2、安装
2.1、安装Anaconda
-
下载法1:本地下载,再将安装包传到linux服务器上
-
下载法2:直接使用linux命令行下载
-
# 首先安装wget sudo apt-get install wget # Ubuntu sudo yum install wget # CentOS # 然后使用wget从清华源上下载 # 如要下载Anaconda3-2021.05-Linux-x86_64.sh,则下载命令如下: wget https://mirrors.aliyun.com/anaconda/archive/Anaconda3-2021.05-Linux-x86_64.sh # 若您要下载其他版本,需要将最后1个/后的文件名改成您希望下载的版本 #在命令行输入 sh Anaconda3-2021.05-Linux-x86_64.sh #若您下载的是其它版本,则将该命令的文件名替换为您下载的文件名 #按照安装提示安装即可 #查看许可时可输入q来退出
-
2.2、将conda加入环境变量
# 在终端中输入以下命令:
vim ~/.bashrc
# 先按i进入编辑模式
# 在第一行输入:
export PATH="~/anaconda3/bin:$PATH"
#修改完成后,先按esc键退出编辑模式,再输入:wq!并回车,以保存退出
#验证是否能识别conda命令:
#在终端中输入以更新环境变量
source ~/.bash_profile
#再在终端输入,若能显示当前有base环境,则conda已加入环境变量
conda info --envs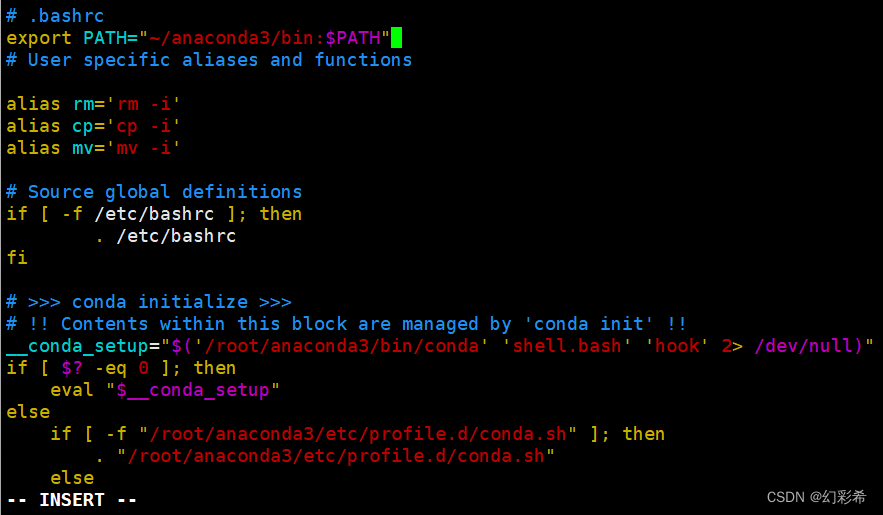
2.3、创建conda环境
# 在命令行输入以下命令,创建名为paddle_env的环境
# 此处为加速下载,使用清华源
conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
# 激活paddle_env环境
conda activate paddle_env2.4、开始安装
Linux:CentOS 8.2
安装paddlepaddle
# 安装CPU 2.4.0 版本,安装paddle时建议使用百度源
pip install paddlepaddle==2.4.0 -i https://mirror.baidu.com/pypi/simple安装成功!
安装paddleHub
pip install paddlehub -i https://mirror.baidu.com/pypi/simple报错:
ERROR: Could not find a version that satisfies the requirement setuptools_scm (from versions: none)
ERROR: No matching distribution found for setuptools_scm解决:pip install setuptools_scm
安装成功!
安装paddleX
pip install paddlex -i https://mirror.baidu.com/pypi/simple报错:
ERROR: Failed building wheel for lap
ERROR: Could not build wheels for lap, which is required to install pyproject.toml-based projects解决:conda install -c conda-forge lap
安装成功!
3、部署
3.1、模型准备
部署模型的格式均为目录下包含model.pdmodel,model.pdiparams和model.yml三个文件。
我准备了垃圾分类的预测模型,把训练导出的模型上传到服务器

3.2、模型转换
首先,我们将PaddleX的Inference Model转换成PaddleHub的预训练模型,使用命令hub convert即可一键转换,对此命令的说明如下:
hub convert --model_dir XXXX \
--module_name XXXX \
--module_version XXXX \
--output_dir XXXX
| 参数 | 用途 |
|---|---|
| --model_dir | PaddleX Inference Model所在的目录 |
| --module_name | 生成预训练模型的名称 |
| --module_version | 生成预训练模型的版本,默认为1.0.0 |
| --output_dir | 生成预训练模型的存放位置,默认为{module_name}_{timestamp} |
因此,我们仅需要一行命令即可完成预训练模型的转换。
hub convert --model_dir /home/hcx/inference_model --module_name waster_classification报错1:
Error: Can not import paddle core while this file exists: /root/anaconda3/envs/paddle_env/lib/python3.8/site-packages/paddle/fluid/libpaddle.so
ImportError: libpython3.8.so.1.0: cannot open shared object file: No such file or directory解决:找到这2个文件地址

将这2个文件添加到Linux环境变量
export LD_LIBRARY_PATH=/root/anaconda3/envs/paddle_env/lib/python3.8/site-packages/paddle/fluid:/root/anaconda3/lib/再次运行模型转换
报错2:
libGL.so.1: cannot open shared object file: No such file or directory解决:pip install opencv-python-headless
转换成功后会打印提示信息,如下:
The converted module is stored in `waster_classification_1691149510.036867`.等待生成成功的提示后,我们就在输出目录中得到了一个PaddleHub的一个预训练模型。
3.3、模型安装
在模型转换一步中,我们得到了一个.tar.gz格式的预训练模型压缩包,在进行部署之前需要先安装到本机,使用命令hub install即可一键安装,对此命令的说明如下:
hub install /home/hcx/waster_classification_1691149510.036867/waster_classification.tar.gz
#等待安装成功
#安装成功后查看模型列表
hub list

3.4、模型部署
下面,我们只需要使用hub serving命令即可完成模型的一键部署,对此命令的说明如下:
hub serving start --modules [Module1==Version1, Module2==Version2, ...] \
--port XXXX
--config XXXX
| 参数 | 用途 |
|---|---|
| --modules | PaddleHub Serving预安装模型,以多个Module==Version键值对的形式列出当不指定Version时,默认选择最新版本 |
| --port | 服务端口,默认为8866 |
| --config | 使用配置文件配置模型 |
等待模型加载后,此预训练模型就已经部署在机器上了。
我们还可以使用配置文件对部署的模型进行更多配置,配置文件格式如下:
{
"modules_info": {
"mobilenetv3_small_hub": {
"init_args": {
"version": "1.0.0"
},
"predict_args": {
"topk": 3,
"warmup_iters": 30,
"repeats": 5
}
}
},
"port": 8866
}| 参数 | 用途 |
|---|---|
| modules_info | PaddleHub Serving预安装模型,以字典列表形式列出,key为模型名称。其中:init_args为模型加载时输入的参数,等同于paddlehub.Module(**init_args)predict_args为模型预测时输入的参数,以mobilenetv3_small_hub为例,等同于mobilenetv3_small_hub.predict(**predict_args) |
| port | 服务端口,默认为8866 |
因此,我们仅需要一行代码即可完成模型的部署,如下:
hub serving start --modules waster_classification
自此,模型部署完成。
3.5、测试
import requests
import json
import cv2
import base64
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tobytes()).decode('utf8')
if __name__ == '__main__':
# 获取图片的base64编码格式
img1 = cv2_to_base64(cv2.imread("./image/glass22.jpg"))
data = {'images': [img1]}
# 指定content-type
headers = {"Content-type": "application/json"}
# 发送HTTP请求
url = "http://服务器地址:8866/predict/waster_classification"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
print(r.json()["results"])结果:[[{'category': 'glass', 'category_id': 1, 'score': 0.8873560428619385}]]














 2796
2796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









