






 文章介绍了CRAFT模型,该模型针对传统文本检测方法在处理自然场景文本时的局限,通过弱监督学习将单词级标注转化为字符级数据,尤其适用于倾斜和弯曲文本的检测。模型采用VGG16为基础,结合上采样和特征拼接生成字符和亲和力分数。训练过程包括合成数据集和真实数据集的GT生成,以及整体训练流程。实验结果显示CRAFT模型在不同数据集上表现良好,但对某些难分字符如孟加拉语和阿拉伯语的识别存在挑战。
文章介绍了CRAFT模型,该模型针对传统文本检测方法在处理自然场景文本时的局限,通过弱监督学习将单词级标注转化为字符级数据,尤其适用于倾斜和弯曲文本的检测。模型采用VGG16为基础,结合上采样和特征拼接生成字符和亲和力分数。训练过程包括合成数据集和真实数据集的GT生成,以及整体训练流程。实验结果显示CRAFT模型在不同数据集上表现良好,但对某些难分字符如孟加拉语和阿拉伯语的识别存在挑战。
论文目录
论文背景
- 传统的目标检测是使用规则的边框表示目标的位置,但这在自然场景下的文本检测,会面临边框无法完全覆盖文本,或文本倾斜、弯曲、大小不一等现象。
- 大多数现有的文本数据集都为单词级别的注释,并无单个字符级别注释,获取字符级别的注释成本过高。
作者基于这两点出发,设计了CRAFT模型,利用弱监督学习将单词级数据标注为字符集数据,再将字符连接作为一个文本,实现了对倾斜弯曲文本的检测。
发展现状与趋势
- 基于回归的文本检测器
- TextBoxes:修改默认边框长宽比以适应文本形状;卷积内核大小从3x3修改为1x5,使其适应大纵横比文本,避免正方形感受野带来的噪声信号。
- DMPNet:使用四边形滑动窗口对文本定位。
- RSDD:利用旋转不变形特征来进行检测。
- 基于分割的文本检测器
- FCN、Holistic-prediction、PixelLink:使用实例分割来估计单词边界区域,用以检测文本。
- SSTD:通过使用注意机制通过减少特征级别的背景干扰来增强文本相关区域。
- TextSnake :采用弯曲的凸多边形框出内容并复原为矩形。
- 端到端的文本检测器
- FOTS 和EAA :结合了流行的检测和识别方法,并以端到端的方式对它们进行训练,通过利用识别结果来提高检测精度。
- Mask TextSpotter :利用其统一模型将识别任务视为语义分割问题。
- 字符级别的文本检测器
- MSER:提取的文本块候选的字符级检测器。MSER识别单个字符,限制了它在某些情况下的检测鲁棒性,例如低对比度,曲率和光反射的场景。
- Seglink:检测小文字块而不是明确的字符级预测,然后将小文字块连接成单词。
研究方法
模型架构
- 本文灵感来自于WordSup模型的弱监督训练框架,可以在只有文本行和单词级标注的数据集上训练出字符级的检测模型,用以生成伪ground truth(GT)。
- 网络结构采用VGG16下采样提取深层次语义特征,并且用类似U-Net上采样和浅层特征进行特征拼接的模式,让模型输出两个通道特征图(热力图)作为区域分数(region score)和亲和力分数(affinity score)
- 使用热力图生成GT,利用后处理方法生成单词级文本框。
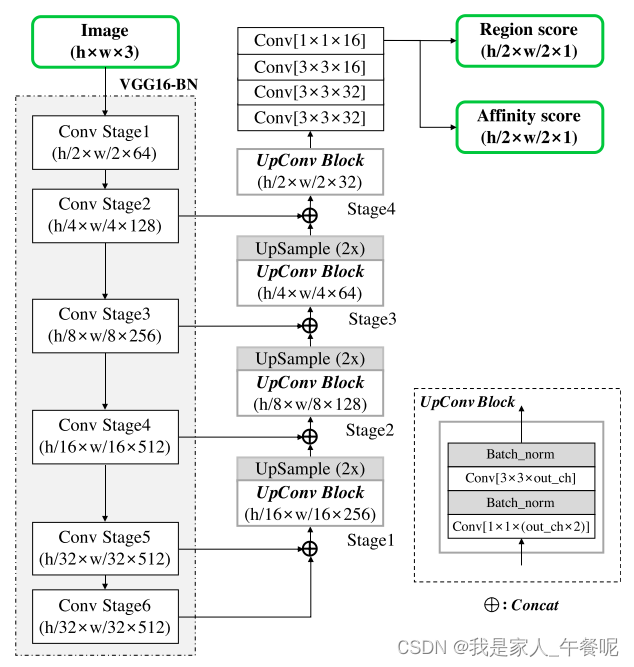
左边模型采用VGG16下采样,输出通道为512。倒数两层通道数进行concat拼接后通道数变为1024进行右边模型的输入。通过UpConvBlock输出通道数为256,再经过双线性插值上采样两倍,通道数变为512与左侧VGG16倒数第三层进行拼接。
但是有一点疑问,拼接后通道数应该为1024,但是代码中此时通道数为512。因此不太理解这里的通道数是怎样变换的,代码中也没有多余的步骤,希望有充分理解该模型结构的朋友可以帮忙解惑。
ground truth(GT)生成
GT的生成分为合成数据集和真实数据集。合成数据集为作者已经标注好的字符级数据集,真实数据集仅有单词级标注和单词长度。
合成数据集GT生成
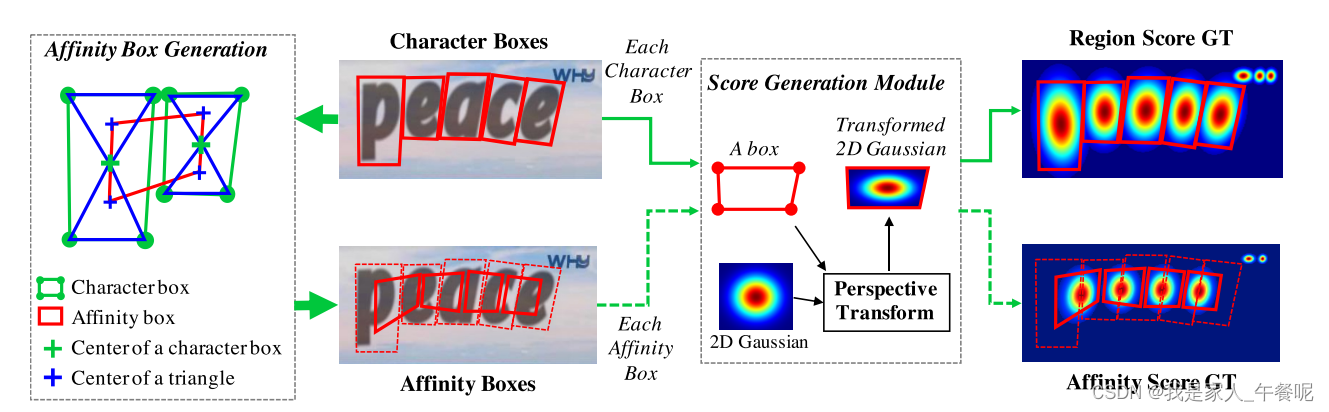
字符级的框是已经存在的,因此只需得到亲和力框。
亲和框是通过相邻字符框定义的。通过连接每个字符框的对角画出对角线,生成两个三角形(称其成为上下三角形)。对于每对相邻字符框,通过将上下三角形的中心设置为框的角来生成亲和框。
GT生成步骤:1、准备一个二维各向同性高斯映射;2、计算高斯映射区域和每个字符框之间的透视变换;3、把高斯图映射到字符框区域。
真实数据集GT生成——弱监督学习
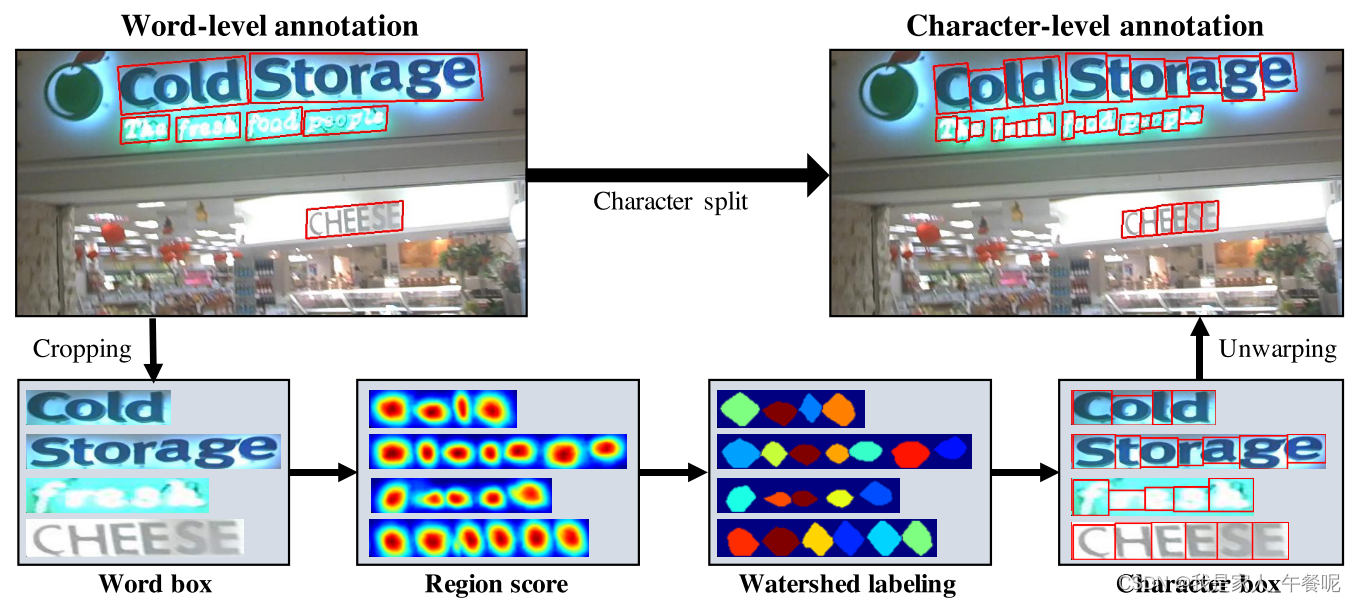

采用弱监督学习的目的是为了将单词级数据裁剪为字符集数据。其中预测区域的分,即通过模型训练得到。
通过弱监督学习得到字符级标注后,再通过之前合成数据集生成GT的过程来生成真实数据集的GT。
但由于真实数据集字符级的标注不一定准确,所以得到的GT其实是伪GT。
整体训练流程
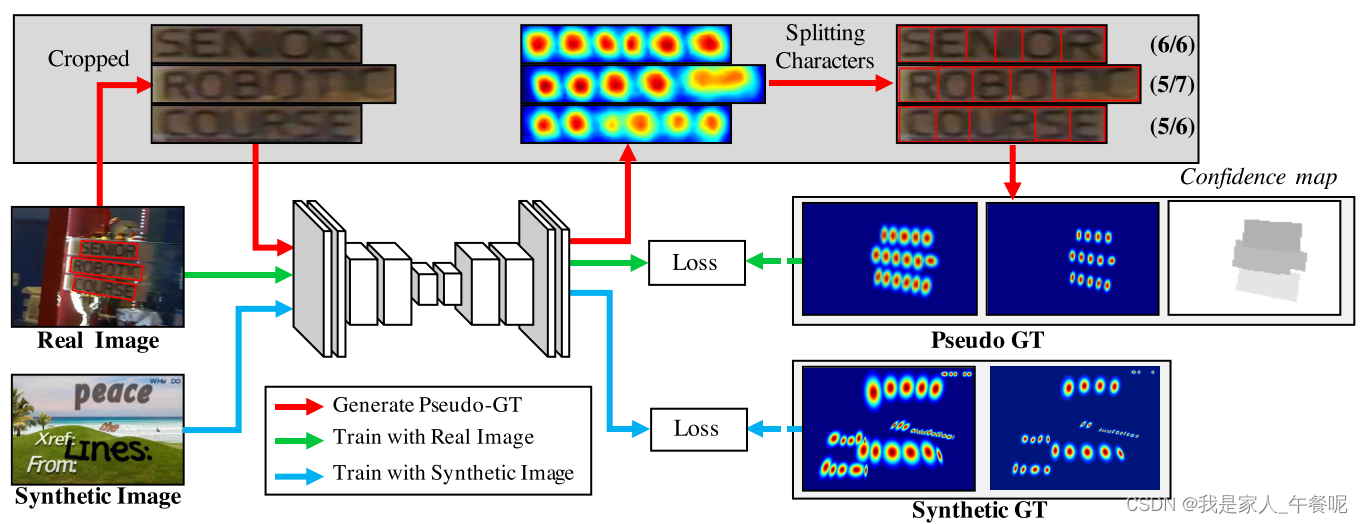 蓝线为合成数据集训练过程,红线为真实数据集字符集分割过程即弱监督学习,绿线为真实数据采集训练过程。
蓝线为合成数据集训练过程,红线为真实数据集字符集分割过程即弱监督学习,绿线为真实数据采集训练过程。
第一阶段:在合成数据集SynthText上迭代50k次,采用每个基准数据集微调模型。
第二阶段:真实数据集使用弱监督学习生成伪GT,与合成数据集1:5进行相同训练。
损失函数
当使用弱监督训练模型时,我们被迫训练不完整的伪GT。 如果使用不准确的区域分数训练模型,则输出可能在字符区域内模糊。为了防止这种情况,作者衡量模型生成的每个伪GT的质量。文本注释中有一个非常有用的线索,即单词长度。 在大多数数据集中,提供了单词的转录,并且单词的长度可用于评估伪GT的置信度。
对于训练数据的单词级注释样本w,置信度sconf (w)为:
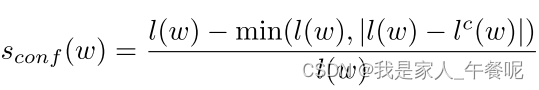
l(w)为样本w的字长, lc(w)为估计的字符长度。
一张图像的像素级置信度Sc( p)为:

R(w)为样本w的边界框区域, p 代表在区域 R ( w ) 中的像素。
整体损失函数计算过程:
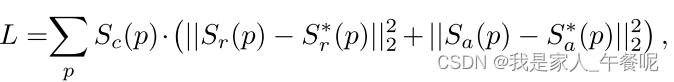
S∗r( p)和 S∗a( p)分别代表区域得分和亲和力得分的伪GT, Sr§和Sa§ 分别表示预测的区域得分和亲和力得分。
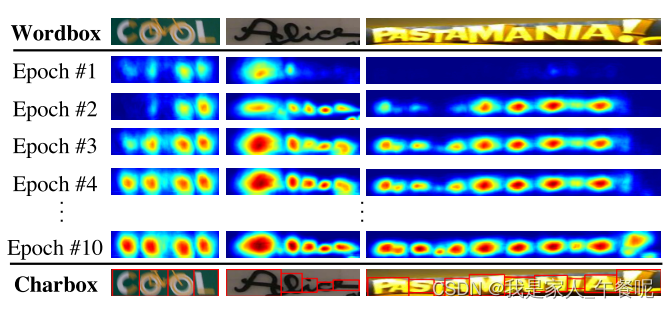
图为训练时的字符区域得分图。在训练的早期阶段,对于自然图像中不熟悉的文本,区域得分相对较低。随着训练的进行,CRAFT模型可以更准确地预测字符,置信度评分sconf (w)也逐渐增加。
如果置信度很低,那说明模型预测出来的文字框的个数和真实文字的个数相差很大,原因可能是模型还很弱或者是这个文本之前没见过。置信度的话就直接给个0.5去训练。
后处理——字符级边框变为单词级边框
常规四边形处理:
1、对得到的区域得分图和亲和力得分图分别进行取二值化阈值计算,将两张图求并集得到一张图。
2、使用连通组件标记CCL进行区域连接。
3、最后使用opencv的MinAreaRect去框出最小的四边形区域。
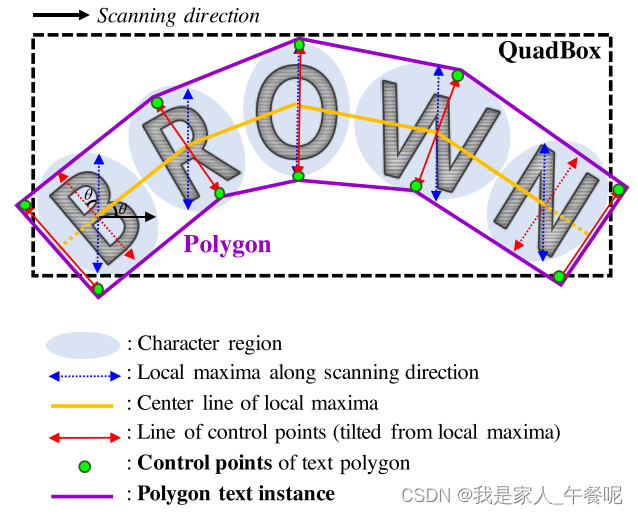
非常规四边形:
1、沿扫描方向找到字符区域的局部最大值线,蓝线。
2、连接全部局部最大线的中点的线作为中心线,黄线。
3、旋转局部最大线以垂直于中心线,反映字符的倾斜角度,红线。
4、局部最大值线的端点是文本多边形的控制点的候选点,绿点。
5、沿着局部最大中心线向外移动两个最外边的倾斜的局部最大值线,形成最终控制点,绿点。
实验结果
在四边形数据集上的结果: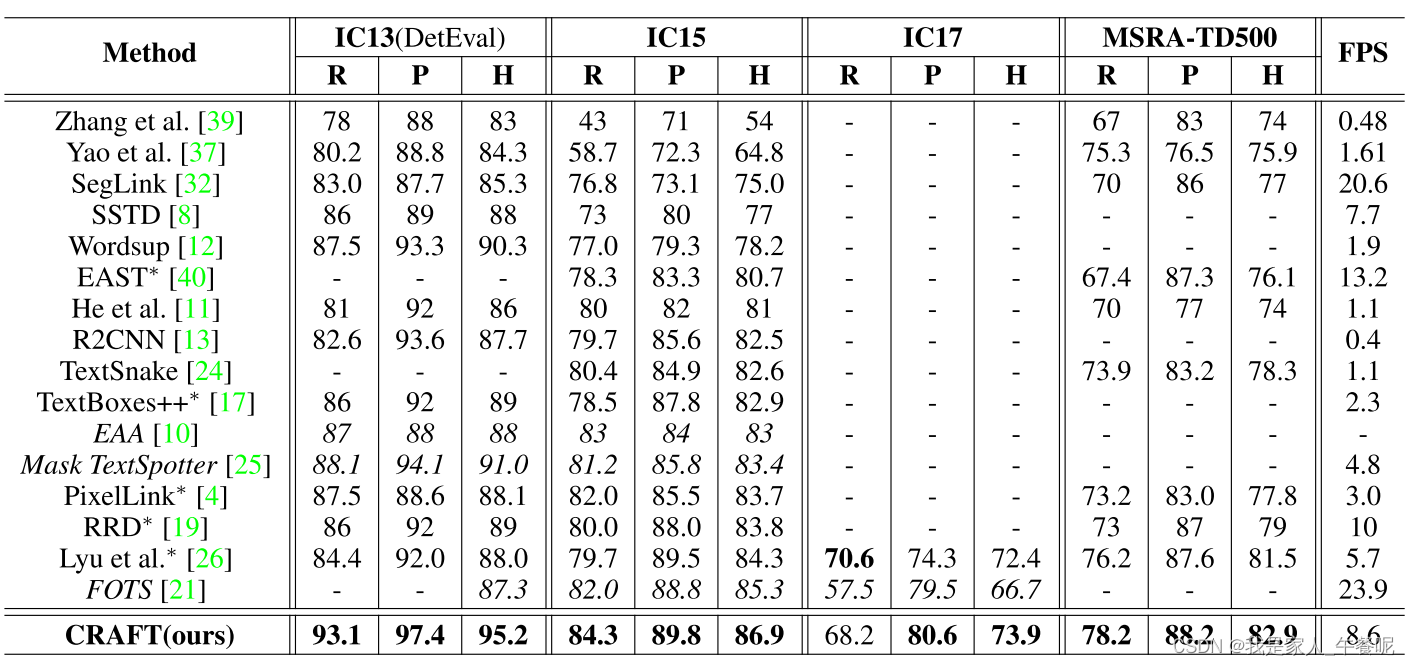
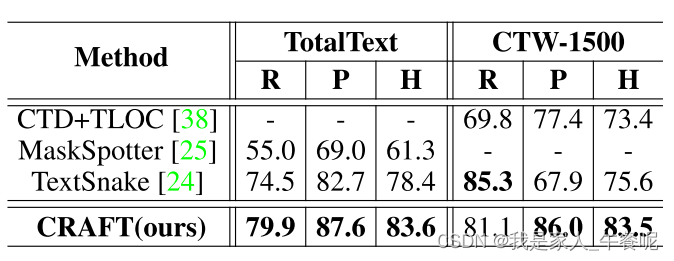
在多边形数据集上的结果:
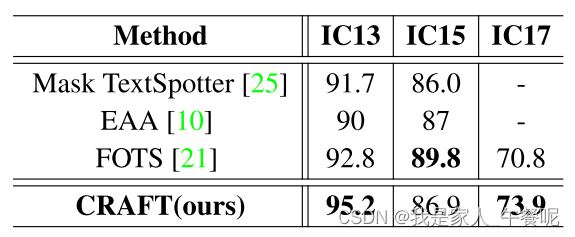
方法优缺点
优点:
- 具有较好的鲁棒性:作者在文本大小多样化的数据集上进行实验,因为方法是基于定位单个字符而不是整个文本,因此在尺度变化方面具有较好的鲁棒性。
- 比端到端方法更优:
- 具有强大的泛化能力。
缺点:
- 由于孟加拉语和阿拉伯语字符很难分割成单独的字符,因此模型不好区分该类字体。

















 2915
2915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









