






接上一章写的HDFS说,Hadoop是一个适合海量数据的分布式存储和分布式计算的一个平台,上一章介绍了分布式存储,这一章介绍一下分布式计算——MapReduce。
一、MapReduce设计理念
map——>映射
Reduce——>归纳
mapreduce是一种必须构建在hadoop之上的大数据离线计算框架。因为mapreduce是给予磁盘IO来计算存储文件的,所以它具有一定的延时性,因此一般用来处理离线数据。
mapreduce的主要计算流程为先将原始数据——>map上,map处理为一个个(key,value)——>Reduce,最后由reduce来归纳输出,这是大致粗略的流程。
二、MapReduce架构特点
MapReduce2.X
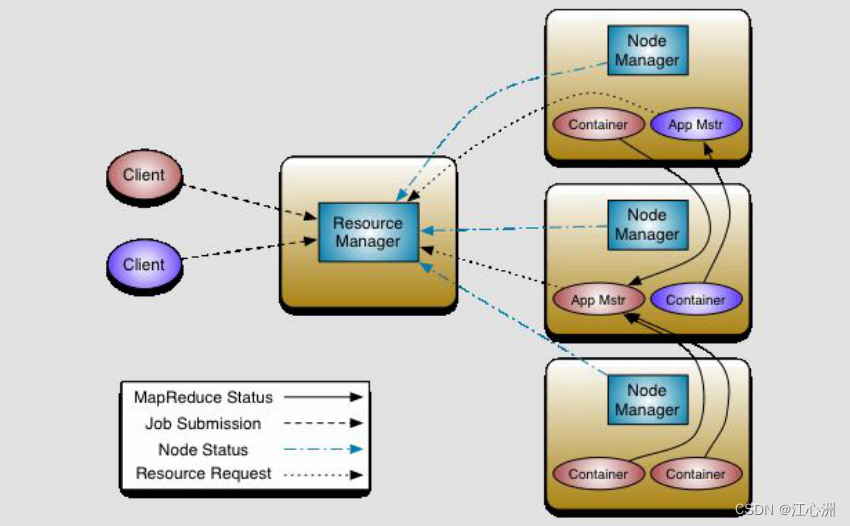
Client:
客户端发送MR任务到集群,其中客户端有很多种类,例如hadoop jar。
ResourceManager:
资源协调框架的管理者,分为主节点和备用节点(防止单点故障,主备切换是基于ZK的管理 PS后面有时候写一篇关于主备节点切换的文章),它时刻与NodeManager保持心跳,接受NodeManager的汇报(NodeManager当前节点的资源情况)。
当有外部框架要使用资源的时候 直接访问ResourceManager即可.
如果是有MR任务,先去ResourceManager根据汇报去分配资源,例如资源在NodeManager1上面,那么NodeManager1负责开辟资源。
YARN(NodeManager):
Yarn,统一管理资源,是hadoop2.0版本后新引入的资源管理系统,以后其他的计算框架可以直接访问yarn获取当前集群的空闲节点。每个DataNode上默认有一个Nodemanager,NodeManager汇报自己的信息到ResourceManager。
ResourceManager:负责整个集群的资源管理和调度。
ApplicationMaster:负责应用程序相关的事物,比如任务调度、任务监控和容错等。
Container:
它是动态分配的,2.X版本中资源的代名词。
ApplicationMaster:
我们本次任务的主导者,负责调度本次被分配的资源Container。当所有的节点任务全部都完成时,applicationMaster告诉ResourceManager请求杀死当前applicationMaster线程,本次任务的所有资源都会被释放。
Task(MapTask--Reduce Task):
开始按照MR的流程执行任务,当任务完成时,applicationMaster接受当前节点的反馈。都执行在Container中。
三、MR的计算流程
在这我们举一个例子:计算1T数据中每个单词出现的次数-->wordcount

例如有一个原始数据File
The books chronicle the adventures of the adolescent wizard Harry Potter and his best friends Ron Weasley and Hermione Granger, all of whom are students at Hogwarts School of Witchcraft and Wizardry.
1T的数据被切分为block块存放在HDFS上,每一个block块为128M。
数据块Block:
block块是HDFS上数据存储的一个单元,同一个文件中的块的大小都是相同的,因为数据存储到HDFS上不可变,所以有可能块的数量和集群的计算能力不匹配,我们需要一个动态调整本次参与计算的节点数量的一个单位。
切片Split:
目的:动态地控制计算单元的数量
切片是一个逻辑概念,在不改变现在数据存储的情况下,可以控制参与计算的节点数目,通过切片大小可以达到控制计算节点数量的目的
有多少个切片就会执行多少个Map任务:
一般切片大小为Block的整数倍(2 1/2),防止多余创建和很多的数据连接,如果Split大小 > Block大小 ,计算节点少了,如果Split大小 < Block大小 ,计算节点多了。默认情况下,Split切片的大小等于Block块的大小,默认128M,如果读取到最后一个block块的时候,与前一个块组合起来的大小小于128M*1.1的话,他们结合生成一个split切片,生成一个map任务。
MapTask:
map默认从所属的切片上读取数据,每次读取一行到内存中,我们可以根据自己书写的分词逻辑(空格,逗号等),计算每个单词出现的次数。这时候会产生(Map<String,Integer>)临时数据,存放到内存中。
the books chronicle the adventures of the adolescent wizard Harry Potter and his best friends Ron Weasley and Hermione Granger all of whom are students at Hogwarts School of Witchcraft and Wizardry
the 1
books 1
chronicle 1
the 1
adventures 1
of 1
...
Wizardry 1
但是内存终归是有限的,如果一个任务都在内存中去随机的占用内存去执行任务可能会造成内存溢出(OOM),可是如果把数据都存放在磁盘中,效率又会太低,由此我们引出环形缓冲区。
环形缓冲区:
可以循环利用这块内存区域,减少数据溢写时map的停止时间,每一个Map可以独享的一个内存区域,在内存中构建一个环形数据缓冲区(kvBuffer),默认大小为100M,设置缓冲区的阈值为80%(设置阈值的目的是为了同时写入和写出),当缓冲区的数据达到80M开始向外溢写到硬盘,溢写的时候还有20M的空间可以被使用效率并不会被减缓,而且将数据循环写到硬盘,不用担心OOM问题。
分区Partition:(环形缓冲区做的)
根据Key直接计算出对应的Reduce,分区的数量和Reduce的数量是相等的,hash(key) % partation(reduce的数量) = num,默认分区的算法是Hash然后取余,Object的hashCode()—equals(),如果两个对象equals,那么两个对象的hashcode一定相等,如果两个对象的hashcode相等,但是对象不一定equlas。
排序Sort:(环形缓冲区做的,快速排序,对前面分区后编号进行排序,使得相同编号的在一起)
对要溢写的数据进行排序(QuickSort),按照先Partation后Key的顺序排序–>相同分区在一起,相同Key的在一起,我们将来溢写出的小文件也都是有序的。
溢写Split:
将内存中的数据循环写到硬盘,不用担心OOM问题,每次会产生一个80M的文件,如果本次Map产生的数据较多,可能会溢写多个文件。
合并Merge:
因为溢写会产生很多有序(分区 key)的小文件,而且小文件的数目不确定,后面向reduce传递数据带来很大的问题,所以将小文件合并成一个大文件,将来拉取的数据直接从大文件拉取即可
合并小文件的时候同样进行排序(归并 排序),最终产生一个有序的大文件。
拉取Fetch:
我们需要将Map的临时结果拉取到Reduce节点
第一种方式:两两合并
第二种方式:相同的进一个reduce
第三种对第二种优化,排序
第四种对第三种优化:如果一个reduce处理两种key,而key分布一个首一个尾,解决不连续的问题,给个编号,这个编号怎么算呢,`回到分区,排序`
相同的Key必须拉取到同一个Reduce节点
但是一个Reduce节点可以有多个Key
未排序前拉取数据的时候必须对Map产生的最终的合并文件做全序遍历
而且每一个reduce都要做一个全序遍历
如果map产生的大文件是有序的,每一个reduce只需要从文件中读取自己所需的即可
合并Merge:
因为reduce拉取的时候,会从多个map拉取数据,那么每个map都会产生一个小文件,这些小文件(文件与文件之间无序,文件内部有序),为了方便计算(没必要读取N个小文件),需要合并文件,归并算法合并成2个(qishishilia),相同的key都在一起。
归并Reduce:
将文件中的数据读取到内存中,一次性将相同的key全部读取到内存中,直接将相同的key得到结果–>最终结果。
写出Output:
每个Reduce将自己计算的最终结果都会存放在HDFS上。
















 722
722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









