







一、seaborn简介
Matplotlib虽然已经是比较优秀的绘图库了,但是它有个今人头疼的问题,那就是API使用过于复杂,它里面有上千个函数和参数,属于典型的那种可以用它做任何事,却无从下手。
Seaborn基于Matplotlib核心库进行了更高级的API封装,可以轻松地画出更漂亮的图形,而Seaborn的漂亮主要体现在配色更加舒服,以及图形元素的样式更加细腻。
二、连续变量绘图
1、数据的变量分布
- 对于单变量的数据来说 采用直方图或核密度曲线是个不错的选择,对应着 distplot() 函数
- 对于双变量来说,可采用多面板图形展现,比如散点图、二维直方图、核密度估计图形等,对应着jointplot() 函数
2、单变量图形
seaborn.distplot(a, bins=None, hist=True, kde=True, rug=False, color=None)
a:表示要观察的数据,可以是 Series、一维数组或列表。
bins:用于控制条形的数量,可以是 Series或整数
hist:接收布尔类型,表示是否绘制(标注)直方图。
kde:接收布尔类型,表示是否绘制高斯核密度估计曲线。
rug:接收布尔类型,表示是否在支持的轴方向上绘制rugplot。
np.random.seed(0) # 生成种子,以防结果不相同
arr = np.random.normal(0, 1, 100)
ax = sns.distplot(arr, bins = 10, hist = True, kde = True, rug = True)
通常,采用直方图可以比较直观地展现样本数据的分布情况,不过,直方图存在一些问题,它会因为条柱数量的不同导致直方图的效果有很大的差异。为了解决这个问题,可以绘制核密度估计曲线进行展现。
3、多变量图形
seaborn.jointplot(x, y, data=None, kind=‘scatter’, stat_func=None, color=None, height=, ratio=5, space=0.2)
x:在x轴需要展示的变量
y:在y轴需要展示的变量
data:需要展示的数据
kind:表示绘制图形的类型,默认为scatter(散点图),可为hex(二维直方图),kde(核密度曲线)
stat_func:用于计算有关关系的统计量并标注图,想要使用这个参数必须降低seaborn版本
color:表示绘图元素的颜色
height:用于设置图的大小(正方形)
ratio:表示中心图与侧边图的比例。该参数的值越大,则中心图的占比会越大
space:用于设置中心图与侧边图的间隔大小
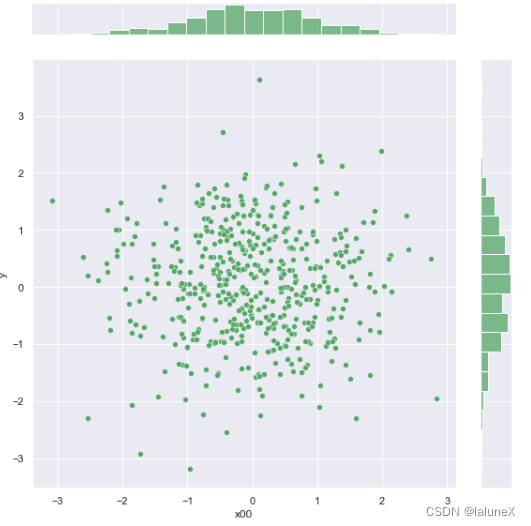
①散点图
dataframe_obj = pd.DataFrame({"x00": np.random.randn(500),"y": np.random.randn(500)})
ax = sns.jointplot(x="x00", y="y", data=dataframe_obj, kind = 'scatter', size = 8, color = 'g', ratio = 8, space = 0.8)
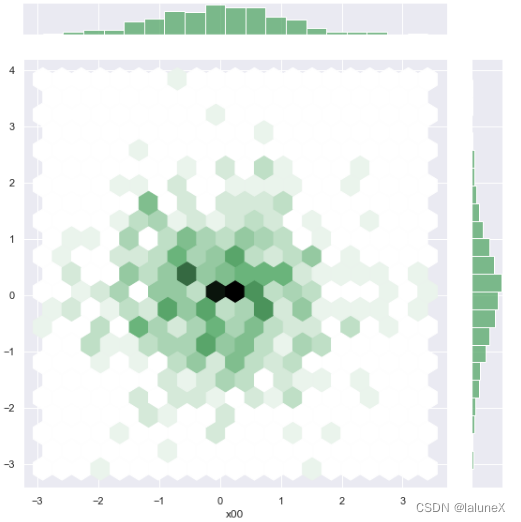
②二维直方图
二维直方图类似于“六边形”图,主要是因为它显示了落在六角形区域内的观察值的计数,适用于较大的数据集。从六边形颜色的深浅,可以观察到数据密集的程度,另外,图形的上方和右侧仍然给出了直方图
背景。
ax = sns.jointplot(x="x00", y="y", data=dataframe_obj, kind = 'hex', size = 8, color = 'g', ratio = 8, space = 0.8)
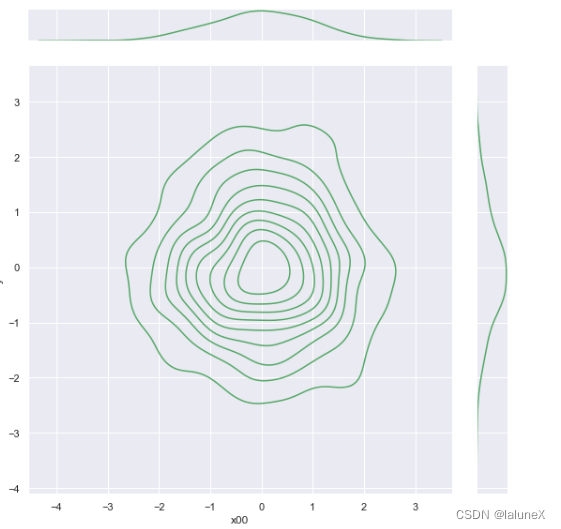
③核密度估计曲线
利用核密度估计同样可以查看二元分布,其用等高线图来表示。通过观等高线的颜色深浅,可以看出哪个范围的数值分布的最多,哪个范围的数值分布的最少
ax = sns.jointplot(x="x00", y="y", data=dataframe_obj, kind = 'kde', size = 8, color = 'g', ratio = 8, space = 0.8)
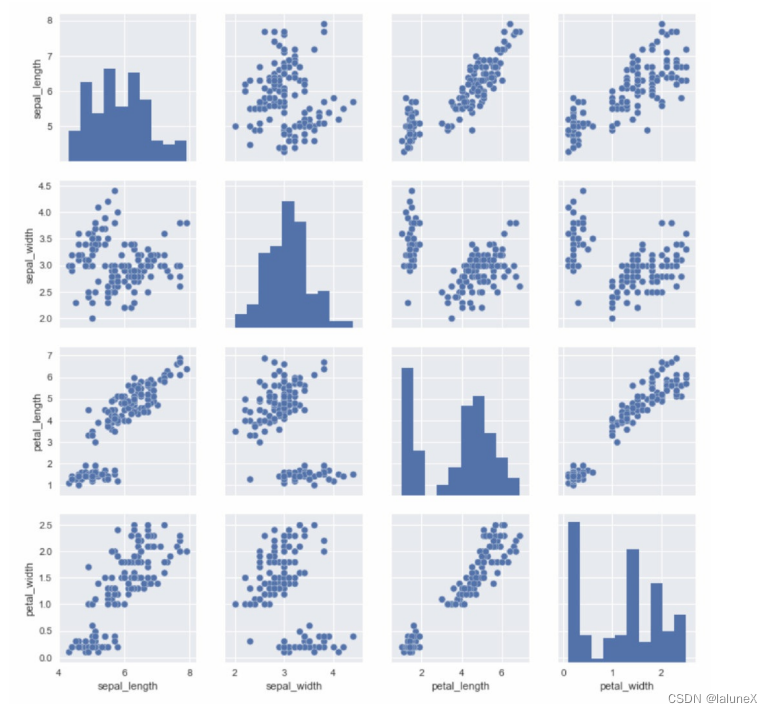
4、成对的双变量分布
要想在数据集中绘制多个成对的双变量分布,则可以使用pairplot() 函数实现,另外,pairplot()函数也可以绘制每个变量在对角轴上的单变量分布。
而默认情况下对角线上是各属性自己的直方分布图,散点图是两两关系图
dataset = sns.load_dataset("iris")
sns.pairplot(dataset)
二、分类变量绘图
数据集中的数据类型有很多种,除了连续的特征变量之外,最常见的就是类别型的数据了,比如人的性别、学历、爱好等,这些数据类型都不能用连续的变量来表示,而是用分类的数据来表示。
Seaborn针对分类数据提供了专门的可视化函数,这些函数大致可以分为如下三种:
分类数据散点图:swarmplot()与 stripplot()。
分类数据的分布图:boxplot() 与 violinplot()。
分类数据的统计估算图:barplot() 与 pointplot()。
数据集
1、散点图
seaborn.stripplot(x=None, y=None, hue=None, data=None, jitter=True)
x,y:在x或y轴展示的变量
hue:增加一个维度,它通过不同的颜色来区分
data:用于绘制的数据集。
jitter:表示抖动的程度(仅沿类別轴)。当很多数据点重叠时,可以指定抖动的数量
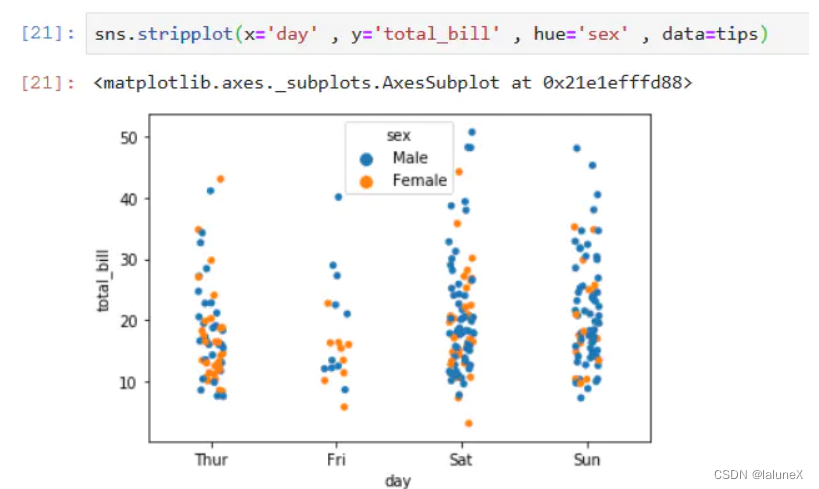
sns.stripplot(x='day' , y='total_bill' , hue='sex' , data=tips)
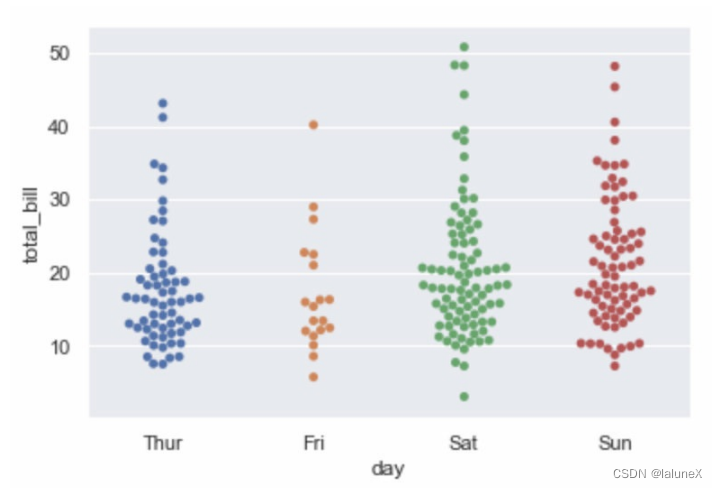
sns.swarmplot(x=“day”, y=“total_bill”, data=tips)
除此之外,还可调用 swarmplot() 函数绘制散点图,该函数的好处是所有的数据点都不会重叠,可以很清晰地观察到数据的分布情况
sns.swarmplot(x="day", y="total_bill", data=tips)
2、分布图
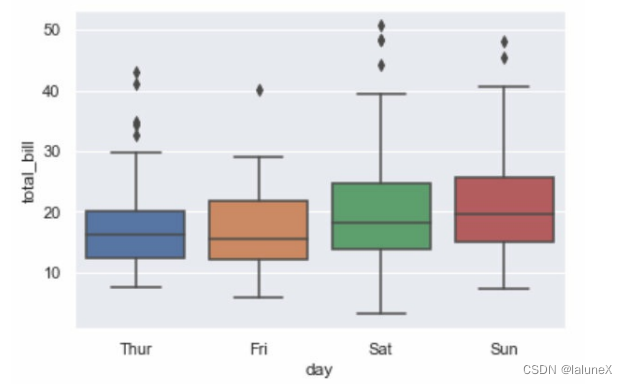
①箱线图
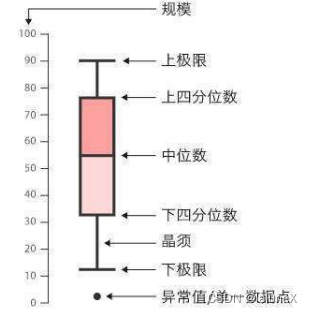
seaborn.boxplot(x=None, y=None, hue=None, data=None)
sns.boxplot(x="day", y="total_bill", data=tips)
②小提琴图
小提琴图 (Violin Plot) 用于显示数据分布及其概率密度。
这种图表结合了箱形图和密度图的特征,主要用来显示数据的分布形状。中间的黑色粗条表示四分位数范围,从其延伸的幼细黑线代表 95% 置信区间,而白点则为中位数。
箱形图在数据显示方面受到限制,简单的设计往往隐藏了有关数据分布的重要细节。例如使用箱形图时,我们不能了解数据分布。虽然小提琴图可以显示更多详情,但它们也可能包含较多干扰信息。
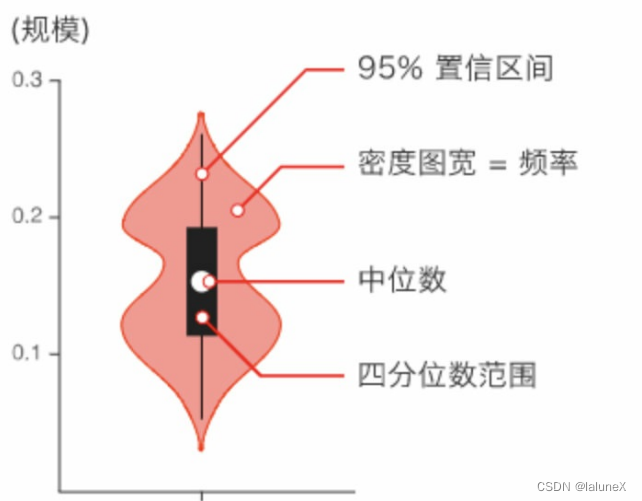
seaborn.violinplot(x=None, y=None, hue=None, data=None)
sns.violinplot(x="day", y="total_bill", data=tips)

3、统计估计图
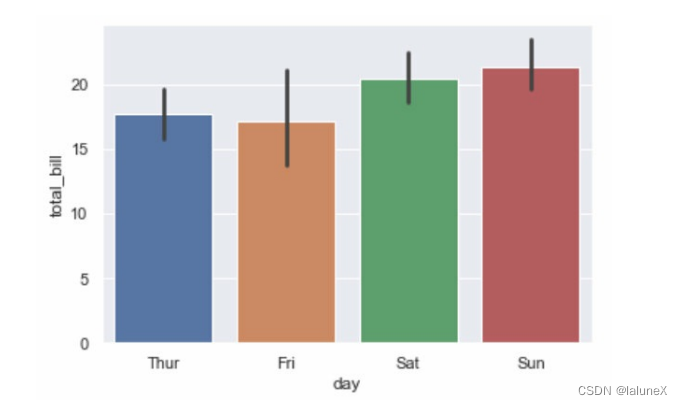
①条形图
最常用的查看集中趋势的图形就是条形图。默认情况下, barplot() 函数会在整个数据集上使用均值进行估计。
sns.barplot(x="day", y="total_bill", data=tips)
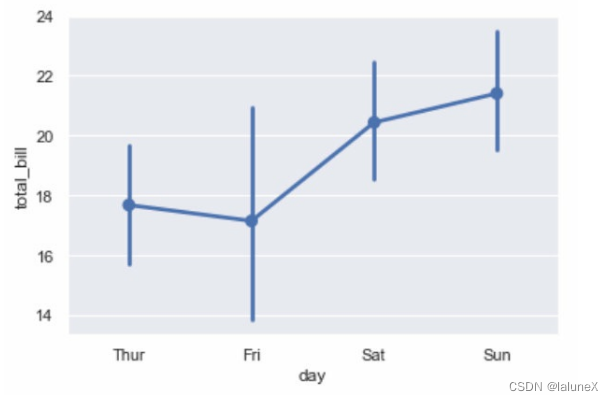
②点图
另外一种用于估计的图形是点图,而不是显示完整的条形,它只会绘制点估计和置信区间。
sns.pointplot(x="day", y="total_bill", data=tips)
本文只用于个人学习与记录,侵权立删















 3660
3660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









