







一、in-place
是指 “就地”操作,即将式子运算结果赋值给原来的变量,如add_(),sub_(),mul_()方法等等
二、广播机制
torch的广播机制同python的广播机制,只不过若某个维度缺失的话则先右对齐左边再用1补齐,然后接下来进行广播即可,最后结果的维度为每维的最大值
print(torch.rand(2, 1, 3) + torch.rand(3)) # 可以运算
print(torch.rand(2, 1, 2) + torch.rand(3)) # 不可以运算
print(torch.rand(2, 1, 3) + torch.rand(2, 3)) # 可以运算
三、协方差矩阵
协方差(Covariance)用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
协方差公式定义为: σ ( x , y ) = 1 n − 1 ∑ i = 1 n ( x i − x ‾ ) ( y i − y ‾ ) \sigma(x,y)=\frac{1}{n-1}\sum_{i=1}^n(x_i-\overline{x})(y_i-\overline{y}) σ(x,y)=n−11∑i=1n(xi−x)(yi−y)
协方差矩阵的每个元素是各个向量元素之间的协方差,是从标量随机变量到高维度随机向量的自然推广
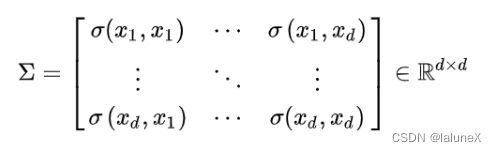
协方差矩阵的作用是描述了数据之间的均方差和相关性
四、requires_grad, grad_fn , grad区别
requires_grad:该节点是否参与反向传播图的计算,如果为True,则参与计算;如果为False则不参与。requires_grad默认为False
grad_fn:表示用于计算梯度的函数。如果该Tensor不是通过计算得到的,则grad_fn为None;如果是通过计算得到的,则返回该运算相关的对象。例如y = x*3,grad_fn记录了y由x计算的过程
grad:存储梯度值。requires_grad为False时,该属性为None;requires_grad为True且在调用过其他节点的backward后,grad保存对这个节点的梯度值,否则为None。
注意:grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零
五、反向传播
1. bacakward
torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False)
- tensors:需要计算的梯度tensor
- grad_tensors:当最终输出是标量,则默认为torch.FloatTensor(1.0);当最终输出是tensor,则需要传入参数torch.FloatTensor(input),且shape和前面的tensor一致
- retain_graph:通常在调用一次backward后,pytorch会自动把计算图销毁,所以要想对某个变量重复调用backward,则需要将该参数设置为True
- create_graph:当设置为True的时候可以用来计算更高阶的梯度
2. grad
torch.autograd.grad(outputs, inputs, grad_outputs=None, retain_graph=None, create_graph=False):该函数只可计算某个变量的梯度
- outputs:函数因变量,即需要求导的函数
- inputs:函数自变量,即输入值
- grad_outputs:同backward里面的grad_tensors
- retain_graph:同backward
- create_graph:同backward
3. 开启/禁止梯度
torch.autograd.enable_grad:启动梯度计算
torch.autograd.no_grad:禁止梯度计算
torch.autograd.set_grad_enabled(mode):设置是否需要梯度计算
六、nn库
torch.nn是专门为神经网络设计的模块化接口,它构建于autograd之上,可以用来定义和运行神经网络。
1. nn.Parameter()与self.register_parameter(name, param)
这两个都是一个东西,只是使用上有细微差别。
作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter,并将这个parameter绑定到这个module里面,相当于变成了模型的一部分,成为了模型中可以根据训练进行变化的参数。
当然我们还可以定义nn.ParameterList和nn.ParameterDict
七、其他
1. 参考链接
https://blog.csdn.net/baidu_38797690/article/details/122180655?spm=1001.2101.3001.4242.1&utm_relevant_index=3
本文只用于个人学习与记录,侵权立删














 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









