






学习完Flink不久,写点东西巩固一下
通过Python爬虫爬取数据后,并作为生产者上传kafka;Flink消费kafka数据,并做topN统计
一、数据获取:我们通过Python爬取美国的疫情数据
创建一个疫情类:
class Epi(object):
def __init__(self):
self.__country = None
self.__cumfrim= None
self.__death= None
self.__timestamp= None
def set_country(self, country):
self.country = country
def get_country(self):
return self.country
def set_cumfrim(self, cumfrim):
self.cumfrim = cumfrim
def get_cumfrim(self):
return self.cumfrim
def set_death(self, death):
self.death = death
def get_death(self):
return self.death
def set_timestamp(self, timestamp):
self.timestamp = timestamp
def get_timestamp(self):
return self.timestamp
从网页上爬取美国的疫情数据:
import json
import time
import requests
from bs4 import BeautifulSoup
from kafka import KafkaProducer
from Epi import Epi
def get_data(url):
#伪装
headers_value = {
'User-Agent': "Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/83.0.4103.61 Safari/537.36"}
try:
data = requests.get(url, headers=headers_value)
except requests.exceptions.ConnectionError as e:
print("error")
print(e)
data = None
print("OK")
return data
#对爬取的数据进行处理
def parse_data(data):
soup = BeautifulSoup(data.text)
work = soup.find_all("div", {'class': "todaydata"})[2]
work = work.find_all("div")
work = list(work)
citys = []
cums = []
deaths = []
rs_data = []
for data in work:
#美国州名
city = data.find("div", {'class': "prod tags"})
if (city != None):
city = data.find("span", {'class': "area"}).get_text()
citys.append(city)
#确诊人数
cum = data.find("div", {'class': "prod tags"})
if (cum != None):
cum = cum.find("span", {'class': "confirm"}).get_text()
cums.append(cum)
#死亡人数
death = data.find("div", {'class': "prod tags"})
if (death != None):
death = death.find("span", {'class': "dead"}).get_text()
deaths.append(death)
for i in range(len(citys)):
epi = Epi()
epi.set_country(citys[i])
if cums[i] == None:
cums[i] = 0
elif deaths[i] == None:
deaths[i] = 0
epi.set_cumfrim(cums[i])
epi.set_death(deaths[i])
#设置一个时间戳作为事件时间
epi.set_timestamp(str(round(time.time() * 1000)))
rs_data.append(epi)
return rs_data
#将数据作为kafka的生产者
topic = 'usa'
bootstrap_servers = 'localhost:9092'
def write_kafka(data):
producer = KafkaProducer(bootstrap_servers=bootstrap_servers,
key_serializer=lambda k: json.dumps(k).encode(),
value_serializer=lambda m: json.dumps(m).encode())
#将数据一条一条的流向kafka
for i in range(len(data)):
msg = str(data[i].get_country()) + "," + str(data[i].get_cumfrim()) + "," + str(data[i].get_death()) + "," + \
data[i].get_timestamp()
try:
future = producer.send(topic=topic, value=msg)
future.get(timeout=10)
except Exception as e:
print('生产者发送失败:{0}'.format(e))
else:
print(msg)
print('生产者发送成功')
if __name__ == '__main__':
print('SPIDER_USA')
url = "http://m.sinovision.net/newpneumonia.php"
while (True):
data = get_data(url)
rs_data = parse_data(data)
write_kafka(rs_data)
time.sleep(2)
二、Flink的数据获取和处理
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import java.util.Properties
object USAEpidemicAnalysis {
//由于向kafka生产数据是以字符串类型传输的,获取时最右侧的时间戳会带”符号,向Long转型时会报错,所以去掉左右侧的”符号
def deleteF_And_LCharInstr (s: String):String = {
val d_L=s.drop(1)
val rs_d_L_R = d_L.dropRight(1)
rs_d_L_R
}
def main(args: Array[String]): Unit = {
val env=StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//配置kafka
val kafkaprop=new Properties()
kafkaprop.setProperty("bootstrap.servers","localhost:9092")
//kafka的消费者的Topic
val kafkasource=new FlinkKafkaConsumer("usa",new SimpleStringSchema,kafkaprop)
kafkasource.setStartFromLatest()
kafkasource.setCommitOffsetsOnCheckpoints(true)
//kafka的消费消息转为数据流
val data_kafka_stream=env.addSource(kafkasource)
//以案列的类型存放数据,并设置提取事件时间作为窗口时间戳
val data_stream=data_kafka_stream.map(x=>{
deleteF_And_LCharInstr(x)
}).map(x=>x.split(","))
.map(x=>Epidemic(x(0),x(1).toInt,x(2).toInt,x(3).toLong))
.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner[Epidemic]{
override def extractTimestamp(t: Epidemic, l: Long): Long = t.timestamp
}))
//美国累计疫情最严重的5个州...这里我们需要上下文,必须适用全窗口函数
//由于不知道爬取一次数据需要的具体时间,但是设置了爬取的间隔时间,所以使用会话窗口
//keyby后的window的计算是分区的计算
//不keyby的数据直接进行windowAll只有一个分区,执行效率降低
//keyby后使用ProcessWindowFunction
//windowAll后使用ProcessAllWindowFunction
val data_no5=data_stream.windowAll(EventTimeSessionWindows.withGap(Time.seconds(2)))
.process(new MyProcessAllWinFunc)
data_no5.print()
env.execute()
}
}
再具体实现MyProcessAllWinFunc
import org.apache.flink.streaming.api.scala.function.ProcessAllWindowFunction
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import java.text.SimpleDateFormat
import java.util.Date
import scala.collection.mutable.ListBuffer
//总结:我们在做topN统计的时候
//processwindowfunction用于处理需要分组的数据,会以分组数作为输出(多少个分组多少次输出)
//processAllwindowfunction用于处理不需要分组的数据,所以只有一个分区(只有一个输出)
class MyProcessAllWinFunc extends ProcessAllWindowFunction[Epidemic,String,TimeWindow] {
val top_list:ListBuffer[Epidemic]=new ListBuffer[Epidemic]
override def process(context: Context, elements: Iterable[Epidemic], out: Collector[String]): Unit = {
//将一个全局窗口的所有数据放入我们的可变列表中,再对列表中的数据排序
elements.foreach(x=>{
top_list.append(x)
top_list.sortBy(x=>{
x.cum
})( Ordering.Int.reverse ).take(5)
})
val time_start=context.window.getStart
out.collect("=========================")
for(i <- 0 to 4){
out.collect("北京时间"+DateFormat(time_start)+"疫情第TOP"+(i+1)+"严重的城市"+top_list(i).country+"已经确诊"+top_list(i).cum+"人")
}
}
//时间戳转日期
def DateFormat(time:Long):String={
val sdf:SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val date:String = sdf.format(new Date((time)))
date
}
}完成了!!
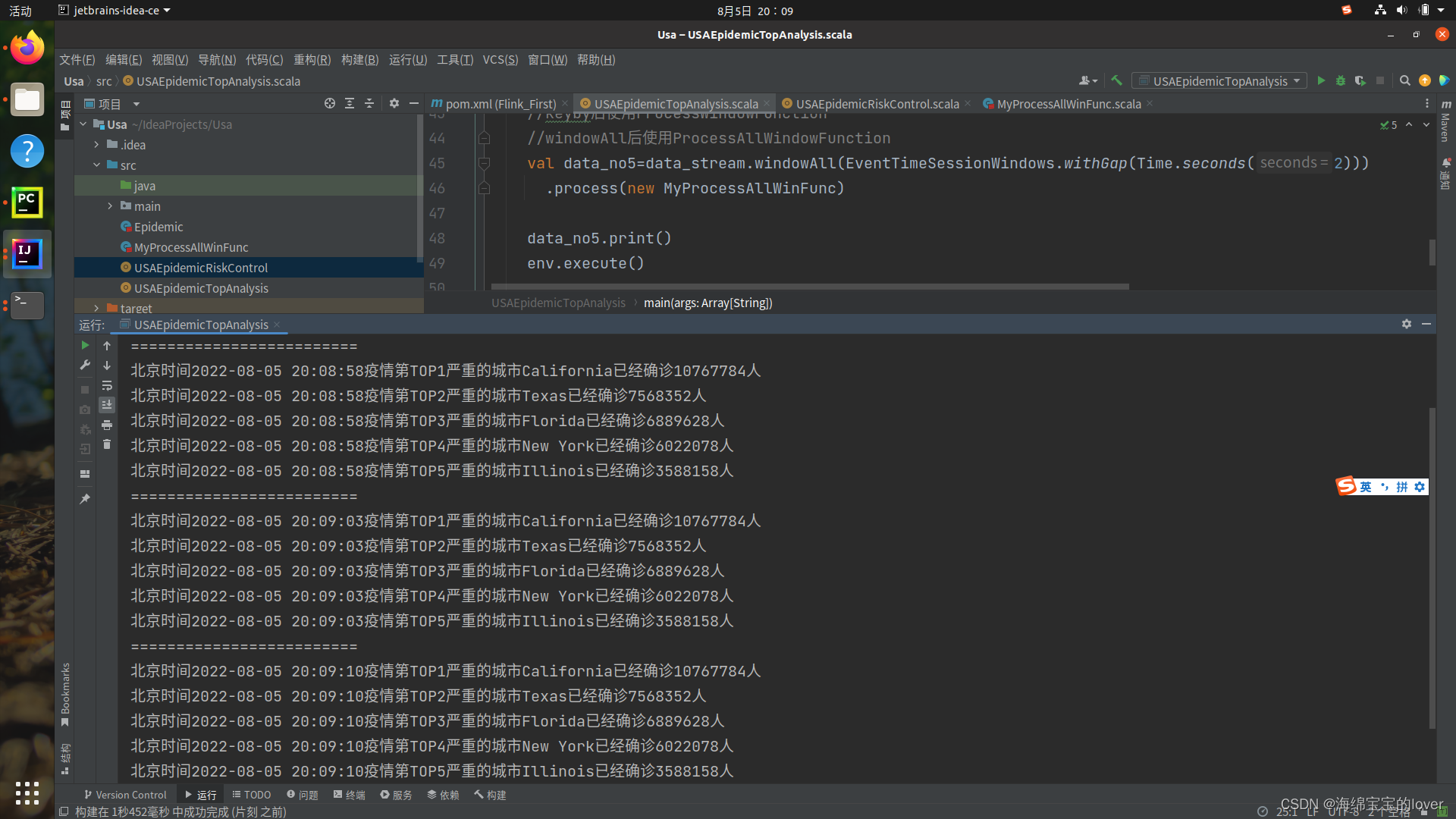
三、查看测试结果:
启动zookeeper和kafka
并设置topic后
















 1212
1212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











