







续上篇
1.处理时间序列
数据集:华盛顿特区的自行车共享系统数据集
目标:将一个平面的二维数据集转换为三维数据集
1.1 增加时间维度+按时间段调整数据
##处理时间序列 将一个每一行都是单独时间数据的源数据改变其数据组织方式
bikes_numpy = np.loadtxt(
'D:\\DeepLearning data\\data\\p1ch4\\bike-sharing-dataset\\hour-fixed.csv',
dtype = np.float32,
delimiter = ",",
skiprows =1,
converters={1: lambda x: float(x[8:10])})### 将日期字符串转换为与第一列中月、日对应的数字。后续会另写一篇博客对loadtxt()进行介绍
bikes = torch.from_numpy(bikes_numpy)
print(bikes,bikes.shape,bikes.stride())
###使用view()按时间段调整数据
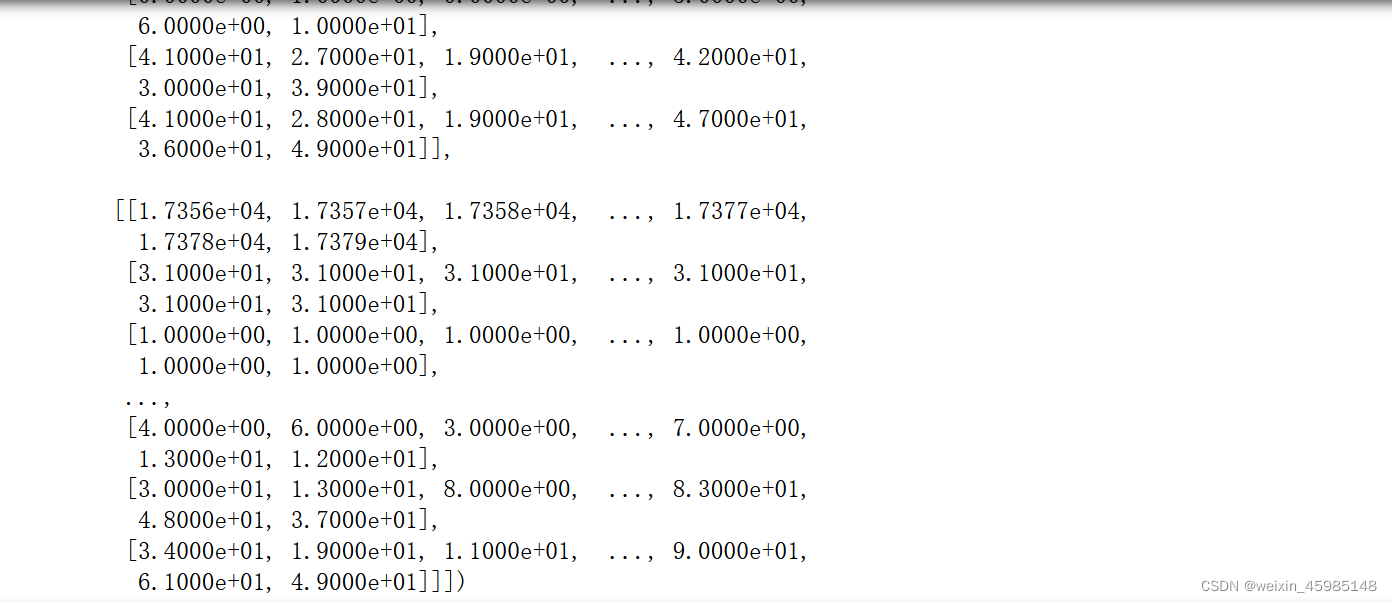
daily_bikes = bikes.view(-1, 24, bikes.shape[1])
print(daily_bikes,daily_bikes.shape,daily_bikes.stride())
###调整为NxCxL次序
daily_bikes = daily_bikes.transpose(1,2)
print(f'调整通道次序后的shape:',daily_bikes.shape,daily_bikes.stride())
print(daily_bikes)
torch.save(daily_bikes, 'D:\\DeepLearning data\\data\\p1ch4\\bike-sharing-dataset\\hour-fixed111.txt')输出:

1.2 准备训练
为了简便,只关注第一天的数据
first_day = bikes[:24].long()
print(first_day[:,9])
###将其one_hot编码
import torch.nn.functional as F
weather_onehot = F.one_hot(first_day[:,9].long()-1,num_classes = 4)###减1是因为天气状况为1-4,而索引从0开始 num_classes=4指定列数,也就是tf中的depth
print(first_day[:,9].long()-1)
print(weather_onehot)输出:

使用cat()函数将矩阵连接到原始数据集中:
###使用cat()函数将矩阵连接到原始数据集中
torch.cat((bikes[:24],weather_onehot),1)[:1] ###圆括号里的1表示沿着列方向拼接。[:1]取第一列输出:

cat()和one_hot应用于daily_bikes:
###cat()和one_hot应用于daily_bikes
daily_weather_onehot = F.one_hot(daily_bikes[:,9,:].long()-1, num_classes = 4)
print(daily_weather_onehot,daily_weather_onehot.shape)
daily_weather_onehot = daily_weather_onehot.transpose(1,2)
print(daily_weather_onehot,daily_weather_onehot.shape)
###沿着C维拼接
daily_bikes = torch.cat((daily_bikes, daily_weather_onehot),dim=1)
print(daily_bikes)输出:

 对数据进行调整 数据调整至[0,1]以及[-1.0,1.0]:
对数据进行调整 数据调整至[0,1]以及[-1.0,1.0]:
####对变量进行调整
####将数据调整至[0,1]
temp = daily_bikes[:,10,:]
temp1 = daily_bikes[:,10,:]
temp_min = torch.min(temp)
temp_max = torch.max(temp)
daily_bikes[:,10,:] = ((daily_bikes[:,10,:] - temp_min)/(temp_max - temp_min))
print(daily_bikes[:,10,:])
####将数据调整至[-1.0,1.0]
temp1 = (temp1 - torch.mean(temp1)/(torch.std(temp1)))
print(temp1)输出:

显示全是-2.几,怎么感觉不在[-1,1]之间,写进CSV看一下
np.savetxt('D:\\DeepLearning data\\data\\p1ch4\\bike-sharing-dataset\\temp1.csv',temp1,delimiter=',')
##好像真是。。。
from PIL import Image
img = Image.open("D:\\DeepLearning data\\data\\p1ch4\\bike-sharing-dataset\\temp1.jpg")
img 
检查了一遍,原来是石乐志,没加括号。。。先算了后边的除法
正确代码:
###重新读数据再试一次
bikes_numpy = np.loadtxt(
'D:\\DeepLearning data\\data\\p1ch4\\bike-sharing-dataset\\hour-fixed.csv',
dtype = np.float32,
delimiter = ",",
skiprows =1,
converters={1: lambda x: float(x[8:10])})### 将日期字符串转换为与第一列中月、日对应的数字。后续会另写一篇博客对loadtxt()进行介绍
bikes = torch.from_numpy(bikes_numpy)
print(bikes,bikes.shape,bikes.stride())
###使用view()按时间段调整数据
daily_bikes = bikes.view(-1, 24, bikes.shape[1])
print(daily_bikes,daily_bikes.shape,daily_bikes.stride())
###调整为NxCxL次序
daily_bikes = daily_bikes.transpose(1,2)
print(f'调整通道次序后的shape:',daily_bikes.shape,daily_bikes.stride())
print(daily_bikes)
daily_bikes[:,10,:] = (daily_bikes[:,10,:] - torch.mean(daily_bikes[:,10,:]))/torch.std(daily_bikes[:,10,:])
print(daily_bikes[:,10,:])
对劲了
2.表示文本
2.1 将文本转化为数字
下载并读取《傲慢与偏见》
###4.5 表示文本
##本节目标是将文本转化为神经网络可以处理的内容——数字张量
##下载并读取《傲慢与偏见》
with open('D:\\DeepLearning data\\data\\p1ch4\\jane-austen\\1342-0.txt',encoding='utf-8') as f:
text = f.read()
text输出:

2.2 独热编码字符
##解析文本中的字符,并为每个字符提供独热编码
lines = text.split('\n')
line = lines[200]
print(line)
##创建一个张量,用于保存每行字符的独热编码
letter_t = torch.zeros(len(lines),128)##128是ASCII编码限制的
print(letter_t.shape)
for i, letter in enumerate(line.lower().strip()): ###。lower()转化为小写,.strip()用于移除字符串头尾指定的字符(默认为空格)
letter_index = ord(letter) if ord(letter) < 128 else 0###ord()以一个字符(长度为1的字符串)作为参数,返回对应的ASCII或者Unicode值
letter_t[i][letter_index] = 1
print(letter_t)输出:

2.3 独热编码整个词
###定义一个函数,作用:接收文本并以小写字符形式返回,同时去掉标点符号
def clean_words(input_str):
punctuation = '.,;:"!?”“_-'
word_list = input_str.lower().replace('\n',' ').split()
word_list = [word.strip(punctuation) for word in word_list]
return word_list
words_in_line = clean_words(line) ###传入line
print(line,words_in_line)
line2 = "Hello, my name is Lebron!"##小栗子
words_in_line2 = clean_words(line2)
print(line2,words_in_line2)输出:
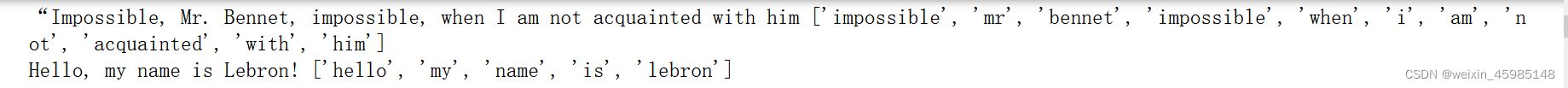
建立一个单词到索引的映射:
###建立一个单词到索引的映射
word_list = sorted(set(clean_words(text)))
word2index_dict = {word:i for(i,word) in enumerate(word_list)}
print(len(word2index_dict),word2index_dict['impossible'])
print(word2index_dict)输出:

为句子中的单词分配一个独热编码的值 :
###为句子中的单词分配一个独热编码的值
word_t = torch.zeros(len(words_in_line),len(word2index_dict))
for i, word in enumerate(words_in_line):
word_index = word2index_dict[word]
word_t[i][word_index] = 1
print('{:2} {:4} {}'.format(i, word_index, word))
print(word_t.shape)输出:

独热编码是一种在张量中表示分类数据非常有用的技术
然而碰到大数据量的语料库时,独热编码就显得无能为力,因此使用文本嵌入是一种有效的解决方式。
3 练习题
3.1 加载纯色图像并将其转换为张量,使用mean()函数并识别。(图片在百度获取)
import imageio
blue_arr = imageio.imread('D:\\DeepLearning data\\data\\p1ch4\\blue.jpg')
print(blue_arr)
print(blue.shape)
##报错报错:
ValueError: Could not find a format to read the specified file in mode 'i'
于是换了一种读取图片的方式:
一开始,简单读取了图片,也没进行统一的剪裁处理,数据很乱,后来仿照之前的代码剪裁了图片:
###换一种读取方式
from PIL import Image
from torchvision import transforms
blue_img = Image.open('D:\\DeepLearning data\\data\\p1ch4\\blue.jpg')
green_img = Image.open('D:\\DeepLearning data\\data\\p1ch4\\green.jpg')
red_img = Image.open('D:\\DeepLearning data\\data\\p1ch4\\red.jpg')
####剪裁一下图片
preprocess = transforms.Compose([
transforms.Resize(256),###将输入图像缩放到256x256个像素
transforms.CenterCrop(224),###围绕中心将图片裁剪为224x224个像素
transforms.ToTensor()])###转换为张量
blue_img = preprocess(blue_img)
green_img = preprocess(green_img)
red_img = preprocess(red_img)
print(blue_img.shape)
print(green_img.shape)
print(red_img.shape)
##验证一下转换后的数据类型
print(type(red_img))###没毛病!
###array-->tensor函数
# def get_tensor(input_array):
# tensor = torch.from_numpy(input_array).float() ###转换为float型,否则torch.mean()运算会报错
###使用mean()函数
blue_mean = torch.mean(blue_tensor,dim=1)
print(blue_mean)
# green_mean = torch.mean(green_tensor,dim=1)
# print(green_mean)
# red_mean = torch.mean(red_tensor,dim=1)
# print(red_mean)输出:

3.2 文本处理
选择一个包含python源代码的相对较大的文件
a.为源文件的所有单词建立一个索引
b.与之前《傲慢与偏见》的索引相比较
c.为源文件创建独热编码
d.丢失信息如何
1.读取文件
with open('D:\\DeepLearning data\\data\\p1ch4\\env.txt',encoding='utf-8') as f:
text = f.read()
text
###独热编码字符
##解析文本中的字符,并为每个字符提供独热编码
lines = text.split('\n')
line = lines[15]
print(line)
##创建一个张量,用于保存每行字符的独热编码
letter_t = torch.zeros(len(lines),128)##128是ASCII编码限制的
print(letter_t.shape)
for i, letter in enumerate(line.lower().strip()): ###。lower()转化为小写,.strip()用于移除字符串头尾指定的字符(默认为空格)
letter_index = ord(letter) if ord(letter) < 128 else 0###ord()以一个字符(长度为1的字符串)作为参数,返回对应的ASCII或者Unicode值
letter_t[i][letter_index] = 1
print(letter_t) 
词划分时使用空格代替换行:
###定义一个函数,作用:接收文本并以小写字符形式返回,同时去掉标点符号 空格划分
def clean_words(input_str):
punctuation = '.,;:"!?”“_-*#@%{}|[]+-=()'
word_list = input_str.lower().replace('\n'," ").split()
word_list = [word.strip(punctuation) for word in word_list]
return word_list
words_in_line = clean_words(line) ###传入line
print(line,words_in_line)
###建立一个单词到索引的映射
word_list = sorted(set(clean_words(text)))
word2index_dict = {word:i for(i,word) in enumerate(word_list)}
print(len(word2index_dict),word2index_dict['import'])
print(word2index_dict)
用空格替换r"[a-zA-Z0-9_]+":
###定义一个函数,作用:接收文本并以小写字符形式返回,同时去掉标点符号 空格替换r"[a-zA-Z0-9_]+"
def clean_words(input_str):
punctuation = '.,;:"!?”“_-*#@%{}|[]+-=()'
word_list = input_str.lower().replace(r"[a-zA-Z0-9_]+"," ").split()
word_list = [word.strip(punctuation) for word in word_list]
return word_list
words_in_line = clean_words(line) ###传入line
print(line,words_in_line)
###建立一个单词到索引的映射
word_list = sorted(set(clean_words(text)))
word2index_dict = {word:i for(i,word) in enumerate(word_list)}
print(len(word2index_dict),word2index_dict['import'])
print(word2index_dict)
信息丢失还是蛮严重的。
顺带提一下[a-zA-Z0-9_]+:
方括号表示字符集,[a-zA-Z0-9]匹配大小写字母和数字其中一个字符
+号表示重复1到多次,匹配由多个数字大小字母组成的字符串
看完记得点个赞哦~磕头辣















 4083
4083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









