






我使用的工具是jupyter Notebook,可以在上面直接下载例如:

这里我使用的是清华的镜像,这样比较快:# !pip install transformers -i https://pypi.tuna.tsinghua.edu.cn/simple
我的源代码如下: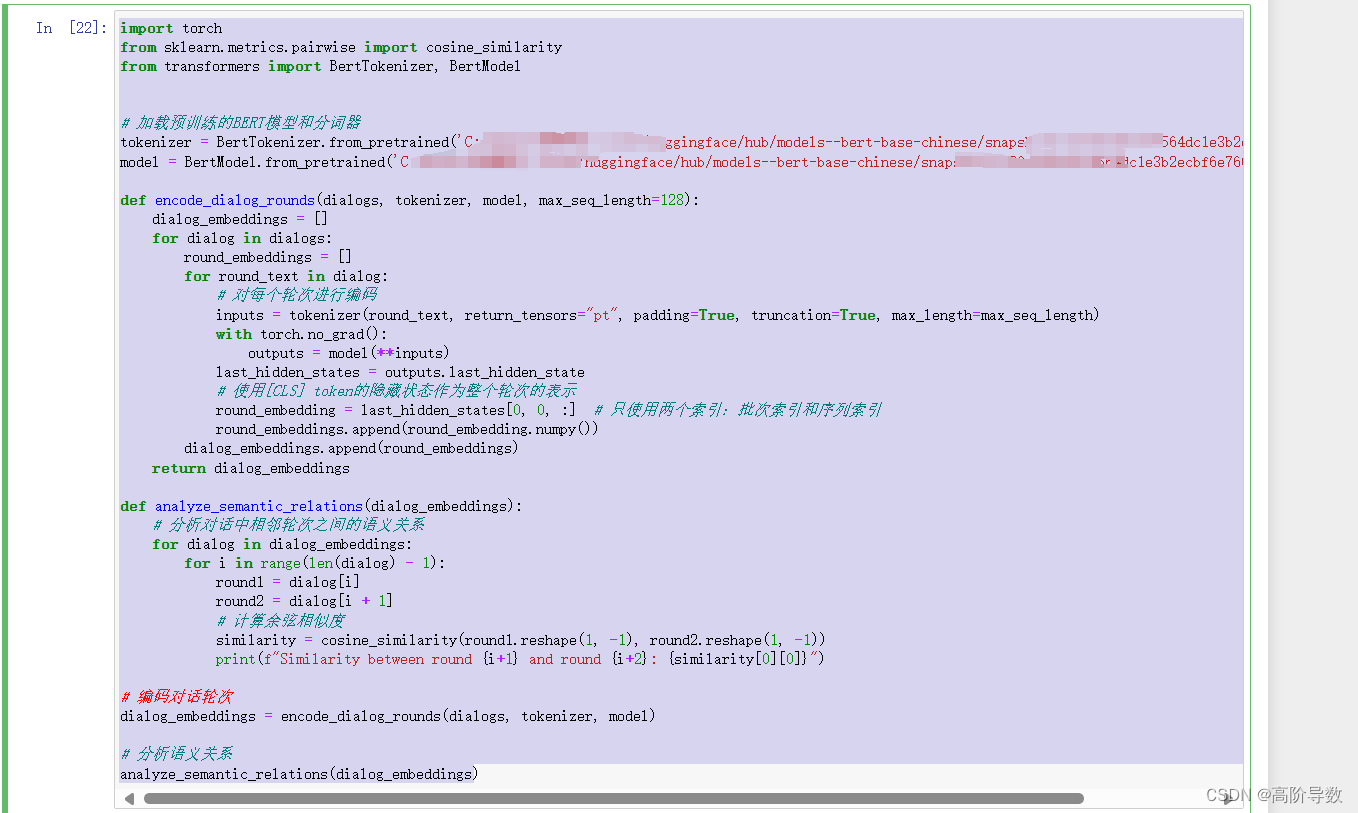
然后就算下载了transformers,运行还是会报错OSError: Can't load tokenizer for 'bert-base-chinese'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwise, make sure 'bert-base-chinese' is the correct path to a directory containing all relevant files for a BertTokenizer tokenizer.
这个错误OSError: Can't load tokenizer for 'bert-base-chinese'通常意味着在尝试加载名为bert-base-chinese的BERT模型的tokenizer时出现了问题。错误提示还建议检查本地是否有同名的目录,因为这可能会干扰从Hugging Face的模型仓库加载模型。
第一:我检查了我的本地目录然而并没有bert-base-chinese,所以不是这个问题。
第二:因为模型文件是从互联网上下载的,所以需要确保你的设备可以正常访问Hugging Face(但是由于 Hugging Face的模型仓库网站(https://huggingface.co/models)的模型仓库需要用到外网。这个网站我访问不了,没有翻墙的VPN,感觉太麻烦了)我直接找了一个国内的镜像例如:
这个网站可以下载HuggingFace 家的全家桶,使用方法如下:
使用 huggingface 官方提供的 huggingface-cli 命令行工具。
1. 安装相关依赖
pip install -U huggingface_hub可以选择命令行或者power shell都行(我使用power shell)

2.设置环境变量(直接在power shell上写上如下代码)
$env:HF_ENDPOINT = "https://hf-mirror.com"
一般在用户的目录下有cache文件夹
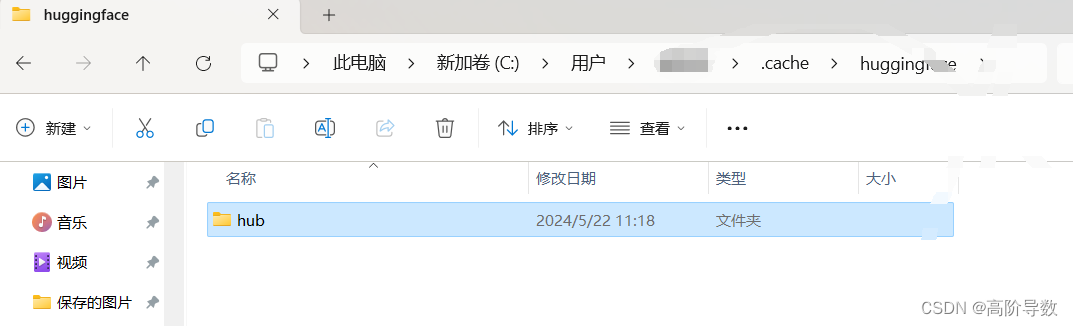
进入cd C:\Users\xxx\.cache\huggingface\hub这个目录后,下载 huggingface-cli download bert-base-chinese,这个过程需要的时间可能有点久,耐心等待。
最后下载好后,在jupyter Notebook 上把下载好的路径放进去就可以引用了。

🆗,以上是我遇到的问题解决方法。

















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









