







PPT 截取有用信息。 课程网站做习题。总体 MOOC 过一遍
- 1、视频 + 学堂在线 习题
- 2、相应章节 过电子书 复习
- 3、总体 MOOC 过一遍
学堂在线 课程页面链接
中国大学MOOC 课程页面链接
B 站 视频链接
PPT和书籍下载网址: 【github链接】
onedrive链接:
【书】
【课程PPT】
通过 例子 介绍 强化学习 的基本概念
基于 马尔可夫决策过程 介绍
状态 State:
s
1
,
s
2
,
.
.
.
,
s
9
s_1, s_2, ..., s_9
s1,s2,...,s9
状态空间 State space :
S
=
{
s
i
}
i
=
1
9
\mathcal{S} = \{s_i\}_{i = 1}^9
S={si}i=19
行动 Action:
a
1
,
.
.
.
,
a
5
a_1,..., a_5
a1,...,a5
行动空间 Action space:
A
(
s
i
)
=
{
a
i
}
i
=
1
5
\mathcal{A}(s_i) = \{a_i\}_{i = 1}^5
A(si)={ai}i=15
状态转移 state transition: s 1 → a 2 s 2 s_1\xrightarrow{a_2} s_2 s1a2s2
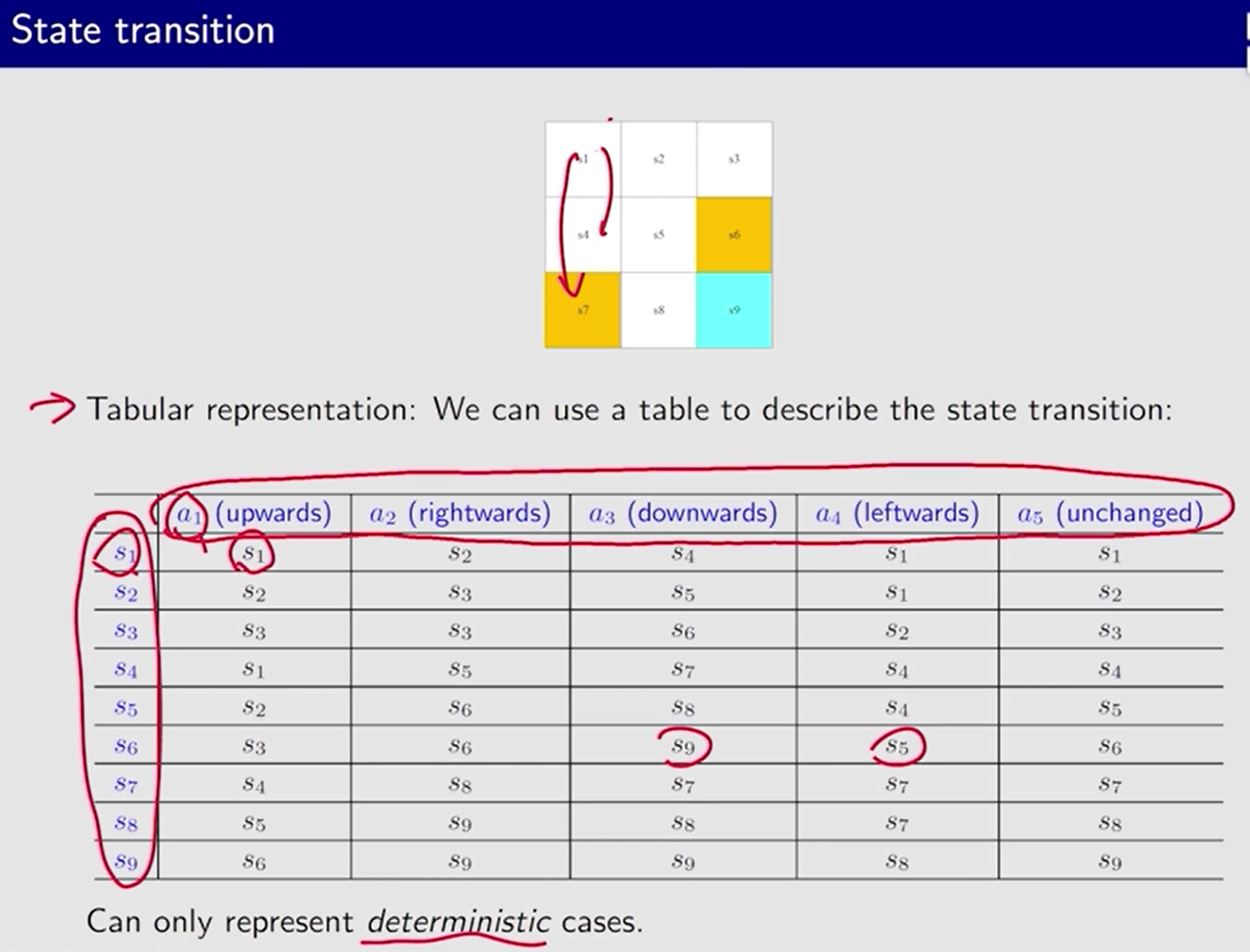
只能表示确定的情况,无法表示 状态转移多种可能的情况
状态转移概率 State transition probability:
- 既可描述 确定性情况,也可描述具有 随机性的情况。
p ( s 2 ∣ s 1 , a 2 ) = 1 p(s_2|s_1,a_2) = 1 p(s2∣s1,a2)=1
p ( s i ∣ s 1 , a 2 ) = 0 , ∀ i ≠ 2 p(s_i|s_1, a_2)=0, \forall ~ i\neq 2 p(si∣s1,a2)=0,∀ i=2
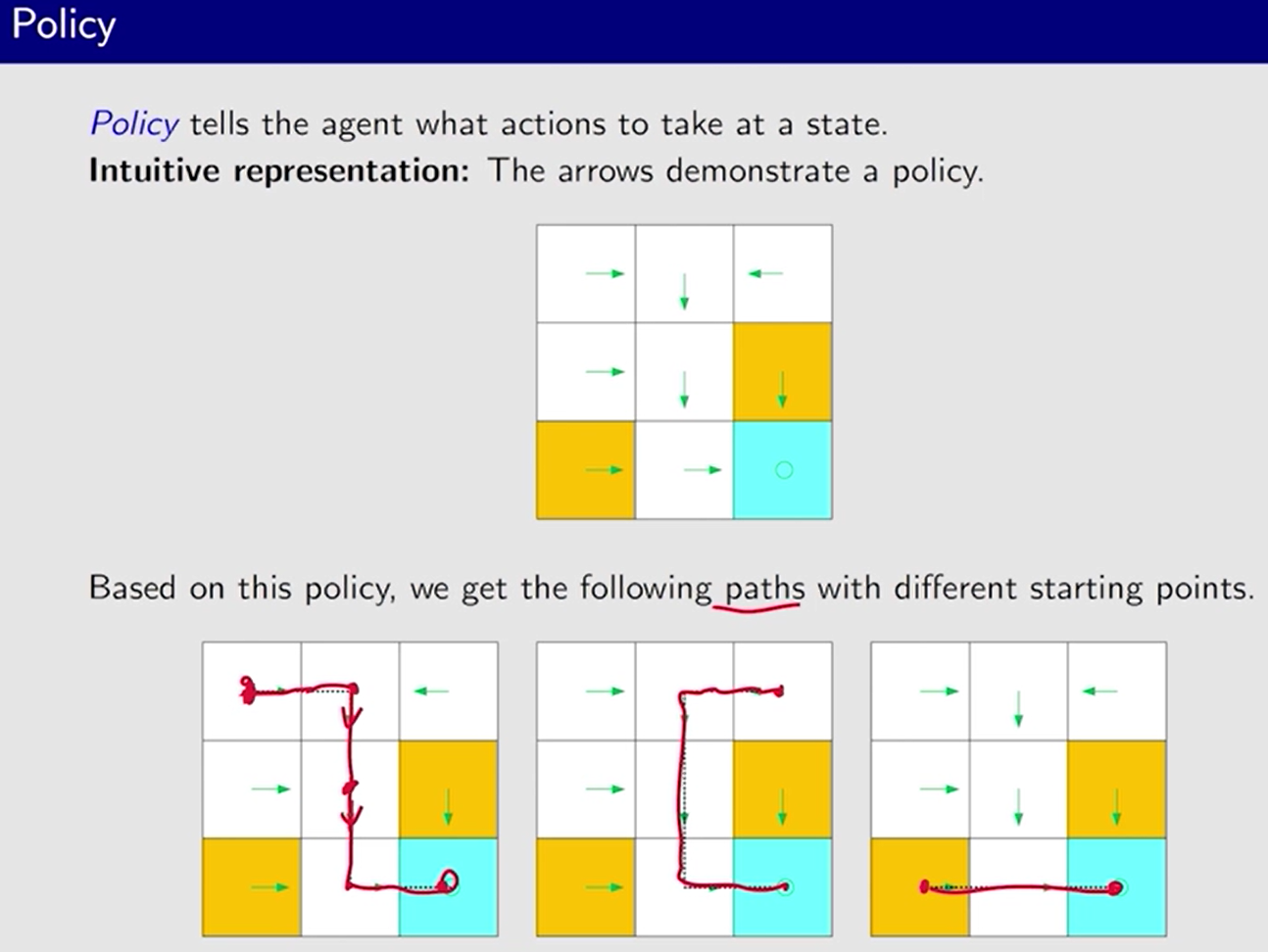
策略 Policy
策略 告诉 agent 在每个状态下 要采取 哪些行动。
三种表示方法:
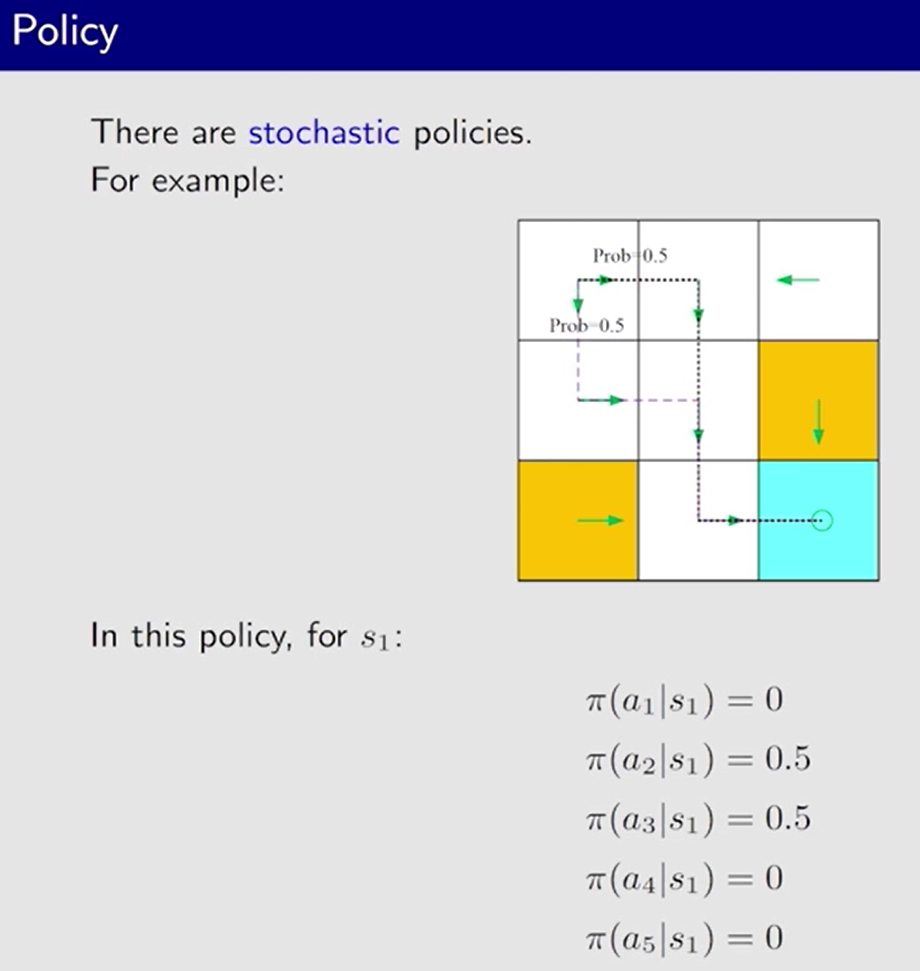
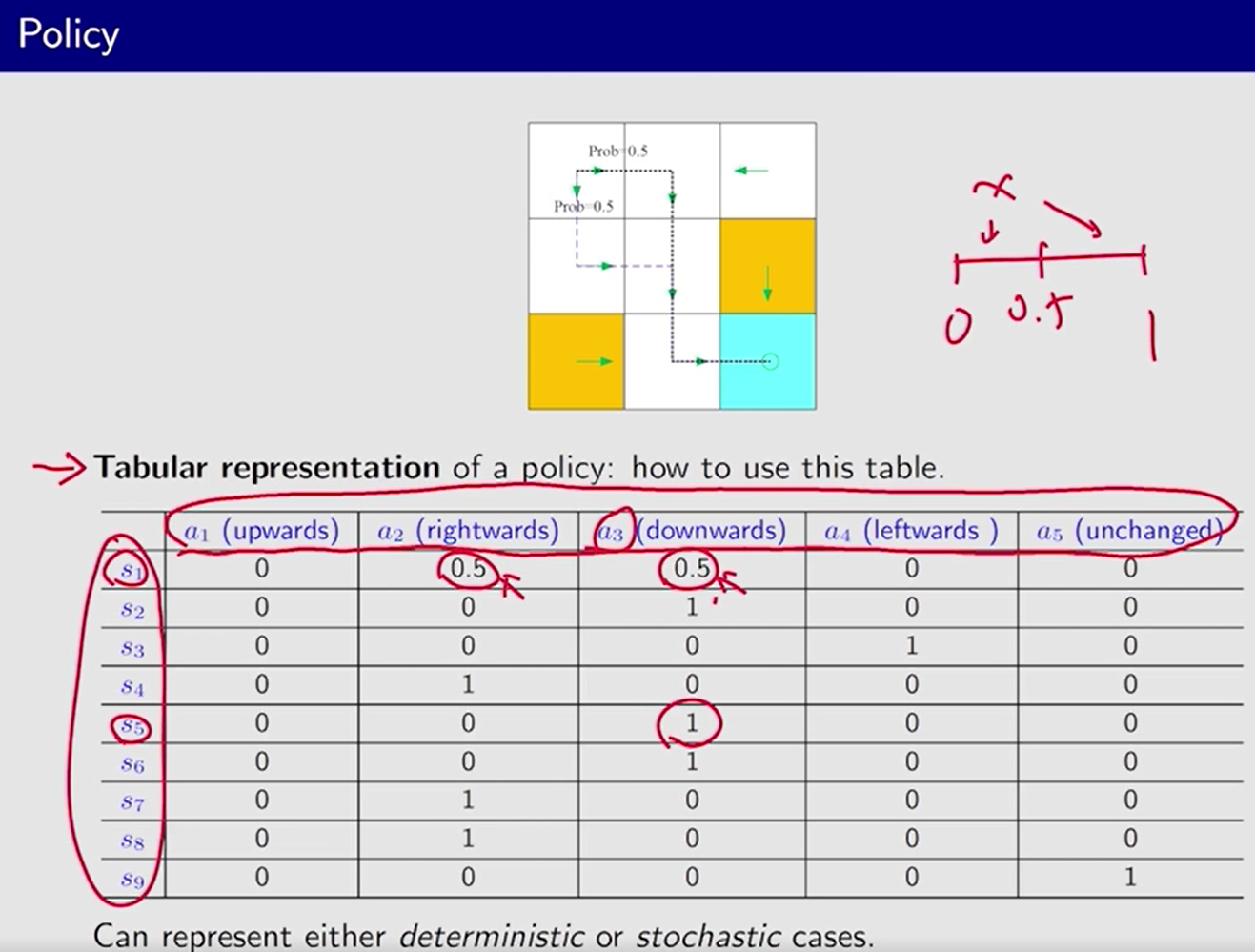
数学表示:
π
\pi
π: 条件概率,任何一个状态下, 任何一个 action 的概率

——————
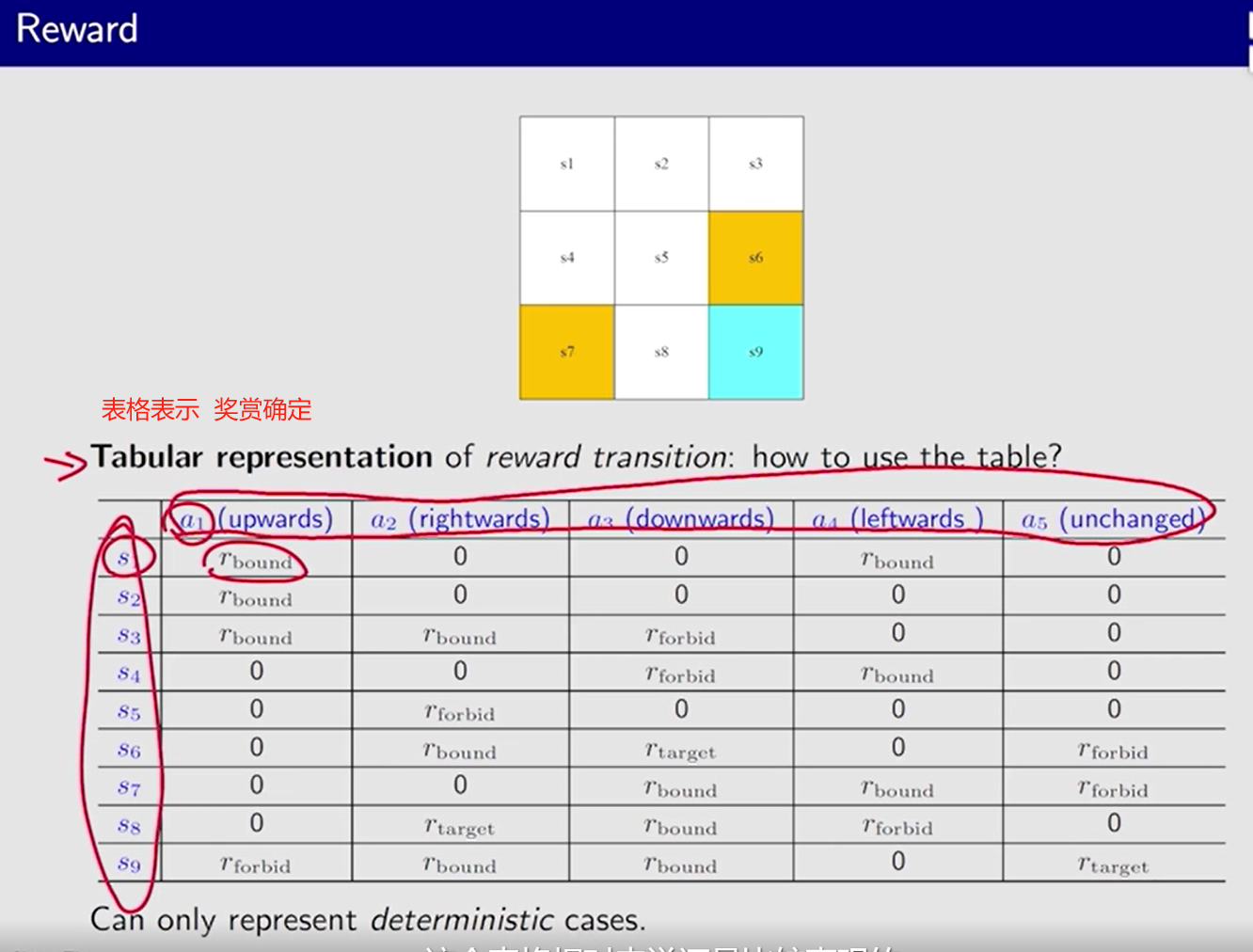
奖励 Reward: 实数、标量。人机交互的手段
r ( s , a ) r(s, a) r(s,a)
一般
正: 鼓励
负: 惩罚
即时奖励 大 并不意味着 能获得 最大的总体奖励。

轨迹 Trajectory: 状态-动作-奖励 链
回报 return:沿轨迹 获得的所有奖励的总和
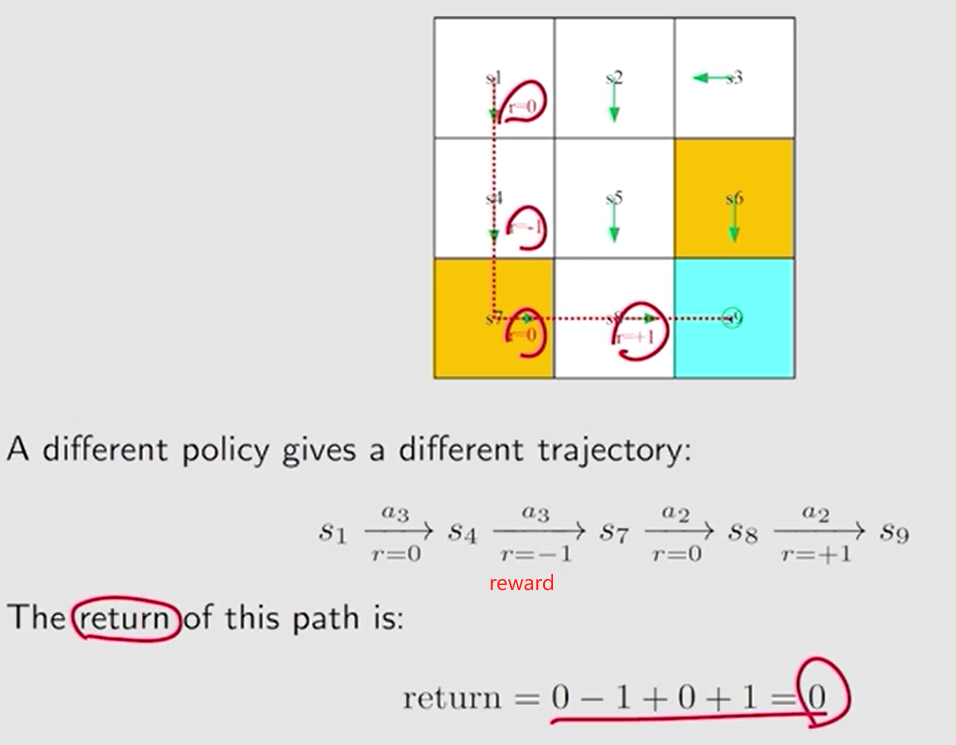
return 越大, 策略越好。
Discounted return 折扣回报
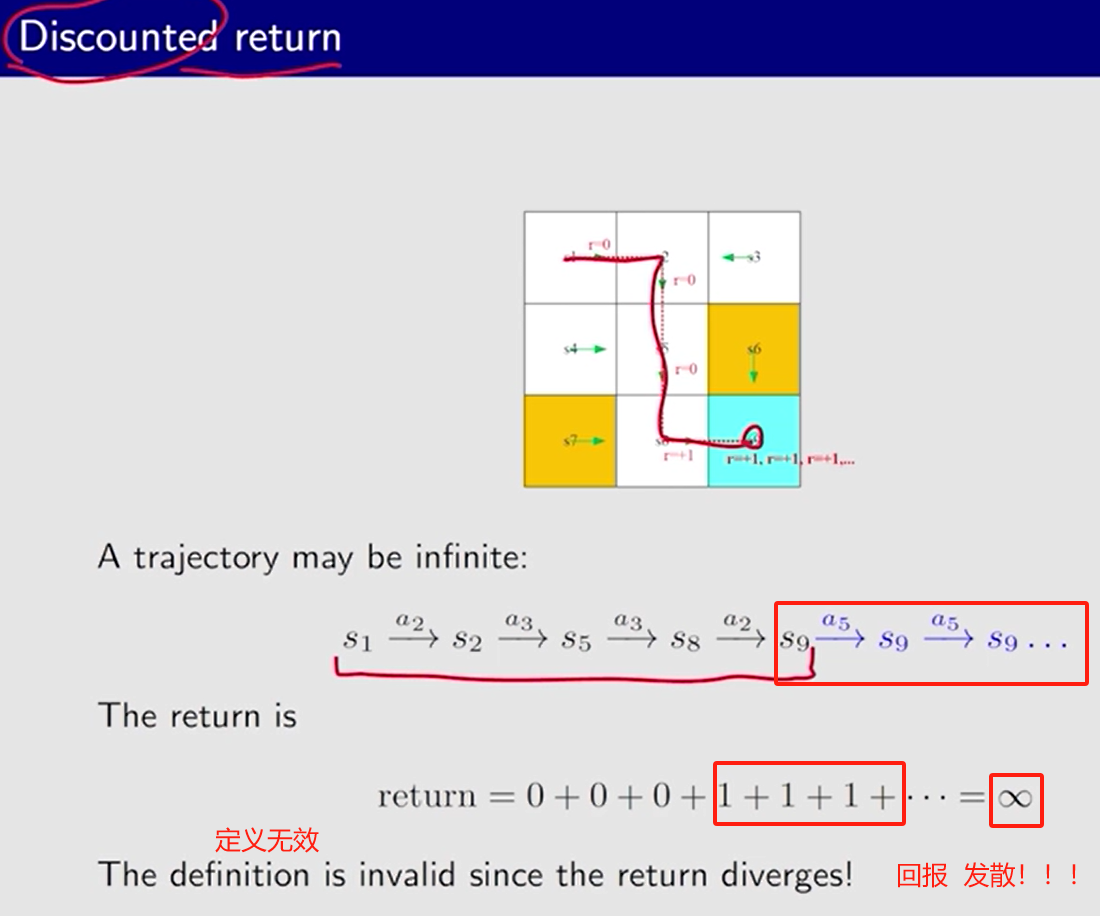
折扣率 discount rate γ \gamma γ

每多进行 一个 动作, 前面的 参数多乘上一个
γ
\gamma
γ
作用:
1、和 不再发散。
2、平衡 更近未来 得到的 reward 和 更远未来 得到的 reward。
减小
γ
\gamma
γ, 近视,更加注重最近的 reward。
增大
γ
\gamma
γ, 远视,更加注重长远的 reward。
回合 Episode: 试了一次。有限步
episodic tasks: 最终停在某处的 任务
continuing tasks:agent 和 环境的交互会永远持续
将 episodic tasks 转成 continuing tasks, 统一处理
方法一: 将 目标状态 视为 特殊的 吸收状态 (absorbing state)。一旦 agent 到达 一个 吸收状态, 就不会再离开。之后的奖励 都为 0.
方法二: 将目标状态 视为 带策略的普通状态。耗费更多的搜索,更一般化。【本课程 选择这种】
- 通过 折扣率 计算折扣回报 避免 发散。
马尔科夫决策过程 (Markov decision process,MDP)
MDP 的关键要素:
集合:
状态集合 State
S
\mathcal{S}
S
动作集合 Action
A
(
s
)
\mathcal{A(s)}
A(s), 其中
s
∈
S
s \in \mathcal{S}
s∈S
奖励集合 Reward
R
(
s
,
a
)
\mathcal{R(s, a)}
R(s,a)
概率分布:
状态转移概率 State transition probability
- 状态 s \mathcal{s} s ,进行动作 a \mathcal{a} a,转移到 状态 s ′ \mathcal{s}^{\prime} s′ 的概率为 p ( s ′ ∣ ( s , a ) ) p(\mathcal{s}^{\prime}|(s, a)) p(s′∣(s,a))
奖励概率 Reward probability
- 状态 s \mathcal{s} s ,进行动作 a \mathcal{a} a,获得奖励 r \mathcal{r} r 的概率为 p ( r ∣ ( s , a ) ) p(r|(s, a)) p(r∣(s,a))
策略 Policy: 状态为
s
\mathcal{s}
s, 进行动作
a
\mathcal{a}
a 的概率为
π
(
a
∣
s
)
\pi(a|s)
π(a∣s)
Markov 特性: 无记忆性,下一刻 t + 1 t + 1 t+1 的 状态 和 奖励 仅和当前时刻 t t t 的 状态 有关。
p
(
s
t
+
1
∣
a
t
+
1
,
s
t
,
.
.
.
,
a
1
,
s
0
)
=
p
(
s
t
+
1
∣
a
t
+
1
,
s
t
)
p(s_{t + 1}|a_{t + 1}, s_t,...,a_1,s_0)=p(s_{t + 1}|a_{t + 1}, s_t)
p(st+1∣at+1,st,...,a1,s0)=p(st+1∣at+1,st)
p
(
r
t
+
1
∣
a
t
+
1
,
s
t
,
.
.
.
,
a
1
,
s
0
)
=
p
(
r
t
+
1
∣
a
t
+
1
,
s
t
)
p(r_{t + 1}|a_{t + 1}, s_t,...,a_1,s_0)=p(r_{t + 1}|a_{t + 1}, s_t)
p(rt+1∣at+1,st,...,a1,s0)=p(rt+1∣at+1,st)
马尔科夫决策过程 + 确定的策略 ——> 马尔科夫过程
回报 和 下一状态
s
′
s^\prime
s′ 有关。
p
(
r
∣
s
,
a
)
=
∑
s
′
p
(
r
∣
s
,
a
,
s
′
)
p
(
s
′
∣
s
,
a
)
p(r|s, a)=\sum\limits_{s^\prime}p(r|s,a,s^{\prime})p(s^\prime|s,a)
p(r∣s,a)=s′∑p(r∣s,a,s′)p(s′∣s,a)
习题笔记:
-
每一个状态最优的动作是能得到 长期回报 均值最大 的那个,而不是得到立即奖励最大的那个。
-
MDP是和策略有关系的,其中 decision 对应的就是 policy。















 649
649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









