






前言
原文地址: https://arxiv.org/pdf/1406.2661v1.pdf
这是一篇2014年发表在NIPS上的论文,这是一篇十分经典的论文,被称作为生成对抗神经网络开山之作,首次提出了生成器(G)和判别器(D),这种网络十分接近于我们的现实生活,该网络的生成对抗模型与我们的生活关联很大,因此也受到了无数人的追捧。
在GAN提出之后,人们又在GAN的基础之上进行了很多的改进和修改,也导致了现在有各种各样的GAN的变种,下面我给出一个在github上比较火的GAN-zoo的地址,上面集中统计了市面上绝大多数的GAN,还是比较有趣,每个GAN都可以解决不同问题。
GAN-zoo链接: https://github.com/hindupuravinash/the-gan-zoo

正文
一、什么是GAN
产生GAN的灵感来自于博弈论之中的零和博弈(zero-sum game),又称零和游戏。
与非零和博弈相对,是博弈论的一个概念,属非合作博弈。它是指参与博弈的各方,在严格竞争下,一方的收益必然意味着另一方的损失,博弈各方的收益和损失相加总和永远为“零”,故双方不存在合作的可能。
零和博弈在生活中是有很多例子:
比如打麻将,一天打下来,总是有人赢钱有人输钱,但是将赢得和输得钱加在一起正好为零,也就是说别人赢得肯定是其他人输得,其中不存在任何合作。其中有一句话说的比较能体现零和博弈:彼之所得必为我之所失。

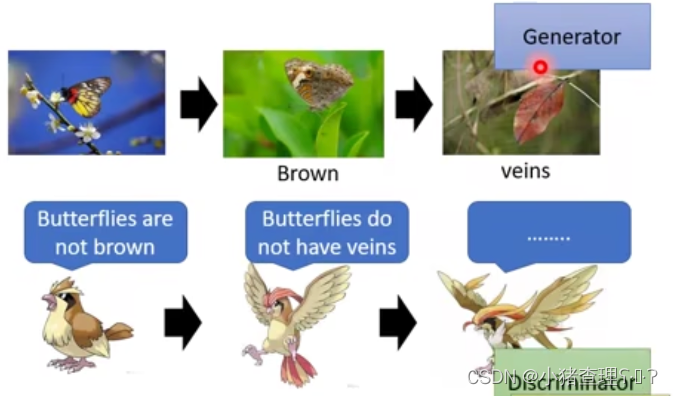
这里引用李宏毅老师的一张图片,并引用李宏毅老师的枯叶蝶的例子。图片上的蝴蝶可以看做是生成器,图上的鸟可以看做是判别器,在自然界中鸟去捕食蝴蝶,蝴蝶为了避免被鸟吃掉,就会一点点进化,首先先变成了棕色,这时候鸟就已经无法判断有没有棕色的蝴蝶了。然后随着鸟的进化,就可以继续捕食棕色的蝴蝶,蝴蝶则会继续进化,最终成为枯叶蝶,这时候鸟又无法区分蝴蝶和叶子了。
蝴蝶和鸟就是在这种相对对抗的过程中进行了进化,就与GAN中的生成器和判别器一样。值得注意的是:蝴蝶并不是为了去变成叶子的模样,而是为了逃避鸟的追捕,慢慢进化成了可以骗过鸟的模样。
二、GAN的应用
GAN的应用就十分的广泛,在各种领域中,比如医学领域中,在做病例分析和CT图判断时,由于样本过少,或者是某种病人过少,所以参考的样本比较少。为了解决这个问题,就可以使用GAN来生成人们所需要的样本模型,来帮助人类对病情进行分析。
在其他领域中,可以使用GAN来生成相关的图片,用来丰富数据集。

如下图,是通过GAN来生成的人脸图像,这些人脸是现实生活中所不存在的,通过生成这些人脸,可以用来训练人脸识别模型,增强人脸识别的准确度。
这些是世界上不存在的人脸,也可以通过生成这些人脸图片,用来做海报和广告,不用担心肖像权的问题。

三、GAN的网络模型
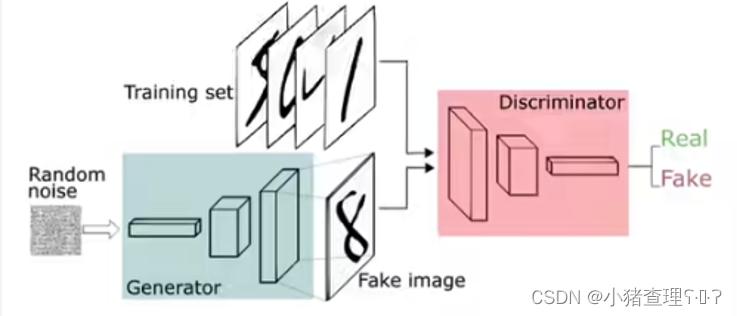
下图是常见的GAN的网络模型图,本文通过GAN实现的MNIST数据集就是通过下面这种流程完成的。
图中可以看到,在生成器中输入噪声,然后产生假图片,在将假图片和真图片都传入判别器中,来进行判定图片的真假。
下图是GAN的核心公式,可以看做是固定G或者D来训练对应的生成器和判别器。
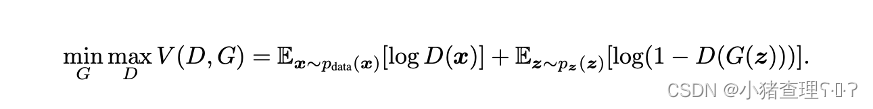
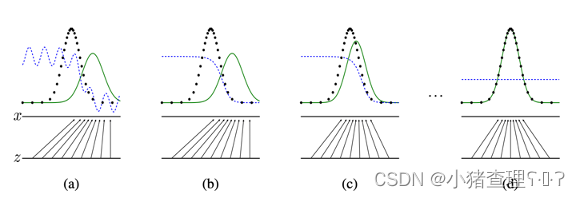
下图中x:图像空间,z:噪声空间,蓝色的线:判别器预测成功的概率,黑色的线:真实图像的分布,绿色的线:生成器生成的图片分布。a->b: 是通过训练判别器,其中可以看出判别器的判定准确率变好了,b->c:训练生成器,可以看出生成图片的分布更契合真实图像的分布, c->d:是通过多次这种反复训练得到的结果。
对抗生成手写数字
一、引入必要的库
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
一、引入必要的库
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
二、进行准备工作
使用MNIST数据集,并进行数组增强等前期工作。
## 对数据做归一化 (-1 1)
transform = transforms.Compose([
transforms.ToTensor(), # 0-1 : channel,high ,witch
transforms.Normalize(0.5,0.5)
])
train_ds = torchvision.datasets.MNIST('data',train=True,
transform=transform,
download=True)
dataloader = torch.utils.data.DataLoader(train_ds,batch_size=64,shuffle=True)
三、定义生成器和判别器模型
# 生成器 使用噪声来进行输入
# 输入为长度为100的 噪声 (正态分布随机数) 生成器输出为(1,28,28)的图片
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.Linear(100,256),nn.ReLU(),
nn.Linear(256,512),nn.ReLU(),
nn.Linear(512,28*28),nn.Tanh()
)
def forward(self,x): # x 表示为长度为100 的噪声
img = self.main(x)
img = img.view(-1,28,28)
return img
# 判别器的实现 输入为一张(1,28,28)图片 输出为二分类的概率值,输出使用sigmoid激活 0-1#
# 是用BCELoss损失函数
# 判别器一般使用 LeakyReLu 激活函数
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Linear(28*28,512),nn.LeakyReLU(),
nn.Linear(512,256),nn.LeakyReLU(),
nn.Linear(256,1),nn.Sigmoid()
)
def forward(self,x): # x 为一张图片
x = x.view(-1,28*28)
x = self.main(x)
return x
四、设置损失函数和优化器,以及进行部分初始化和绘图函数
epochs = 100
lr = 0.0001
# 初始化模型
device = 'cuda' if torch.cuda.is_available() else 'cpu'
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# 优化器(梯度下降)
g_optim = torch.optim.Adam(generator.parameters(),lr=lr)
d_optim = torch.optim.Adam(discriminator.parameters(),lr=lr)
loss_fn = torch.nn.BCELoss()
# 绘图函数
def gen_img_plot(model,test_input):
prediction = np.squeeze(model(test_input).detach().cpu().numpy())
fig = plt.figure(figsize=(4,4))
for i in range(16):
plt.subplot(4,4,i+1)
plt.imshow((prediction[i] + 1 )/2)
plt.axis('off')
plt.show()
test_input = torch.randn(16,100,device=device)
五、进行训练
# GAN训练
D_loss = list()
G_loss = list()
for epoch in range(epochs):
d_epoch_loss = 0
g_epoch_loss = 0
count = len(dataloader)
for step , (img,_) in enumerate(dataloader):
img = img.to(device)
size = img.size(0)
random_noise = torch.randn(size,100,device=device)
# 真实图片上的损失
d_optim.zero_grad()
real_output = discriminator(img) # 对判别器输入真实的图片,real_output 对真实图片预测的结果
# 判别器在真实图像上的损失
d_real_loss = loss_fn(real_output,torch.ones_like(real_output))
d_real_loss.backward()
# 生成图片上的损失
gen_img = generator(random_noise)
fake_output = discriminator(gen_img.detach()) # 判别器输入生成的图片,对生成图片的预测
# 得到判别器在生成图像上的损失
d_fake_loss = loss_fn(fake_output,torch.zeros_like(fake_output))
d_fake_loss.backward()
d_loss = d_real_loss + d_fake_loss
d_optim.step()
# 生成器
g_optim.zero_grad()
fake_output = discriminator(gen_img)
# 生成器的损失
g_loss = loss_fn(fake_output,torch.ones_like(fake_output))
g_loss.backward()
g_optim.step()
with torch.no_grad():
d_epoch_loss += d_loss
g_epoch_loss += g_loss
with torch.no_grad():
d_epoch_loss /= count
g_epoch_loss /= count
D_loss.append(d_epoch_loss)
G_loss.append(g_epoch_loss)
print('Epoch:',epoch)
gen_img_plot(generator,test_input)
print('D_loss:',d_epoch_loss)
print('G_loss:',g_epoch_loss)
六、成果展示
下面三个图分别是Epoch为0,34和94所产生的效果图,可以很清楚的看到,从一团噪声慢慢生成了比较清晰的手写数字。
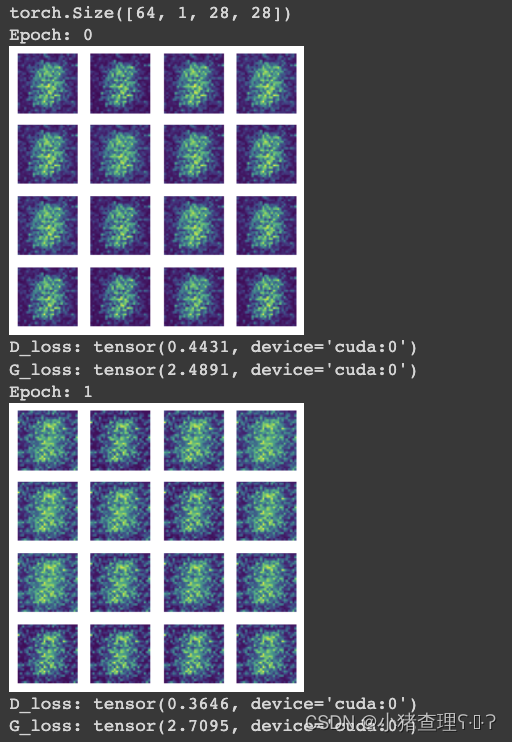


总结
一、创新
相比较传统的模型,存在两个不同的网络,训练方式为对抗式训练,G的度信息来自于判别器D,而不是样本数据。相比于其他的生成模型,GAN只利用了反向传播,而且可以生成更清晰真实的样本。GAN可以用到很多场景上,比如图片风格迁移、超分辨率、图像补全等等。
二、局限
1、多样性不足。
2、模式崩溃问题。
如下图为训练了100个Epoch后的结果,从中可以看出很多都是1,却没有0,5,6,8这种相对比较复杂的数字,这也就是模式崩溃的问题,生成器只想着去骗过判别器,而没有去产生更多样性的数字,生成器训练到后面发现1是很好生成,并且很容易骗过判别器,所以就会产生很多1,而不去训练其他数字,这就导致了多样性比较差并且是模式崩溃。
















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









