






一、监督学习
监督学习可以认为是从给定的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入输出,也可以说是特征和目标。
1.回归问题
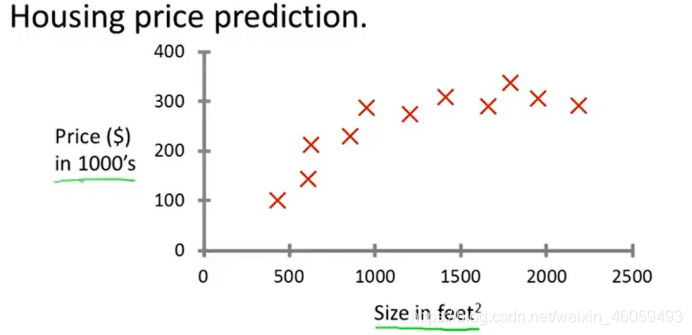
例如上图描述了房屋价格与房屋大小的关系。假设你的朋友希望你通过该数据集对他的房屋售价进行预测。那么,房屋的大小就是输入量,而房屋的价格就是输出量。
我们可以尝试使用一条直线去描述两者之间的关系,也可以尝试使用多项式去描述两者的关系。如果房屋的价格与房屋的大小存在某种特定的函数关系,那么随着样本的数量增加,这种特定的函数关系也就会愈发明显。咱们就可以认为那些点向着这条特定的数式进行运动。解决像这样的问题,如预测房价、未来的天气情况等等。通过建立模型,分析变量之间的关系,我们叫做回归问题。
2.分类问题

图片中横坐标是肿瘤的大小,纵坐标是患者的年龄。o是良性肿瘤,x是恶性肿瘤。这时我们希望通过年龄和肿瘤来对患者进行良性肿瘤与恶性肿瘤的分类。因此将这样的问题按照回归问题显然是不合适的,我们的目标是将样本分到正确的类别而已。而这样的任务也就是分类任务。
就输出值而言,两者也都存在区别。回归问题的输出是离散的,而分类问题的输出是连续的。
二、无监督学习
无监督学习与监督学习的不同之处在于输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行分类试图使类内差距最小化,类间差距最大化。例如通过对新闻内容的采集,实现对每天几十万条新闻进行分类。又或者通过对滴滴打车位置的记录实现对城区中人口密集地区的分类。
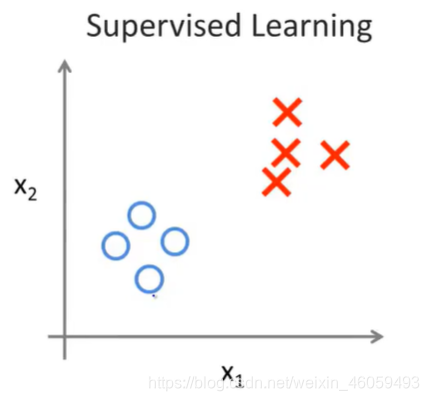
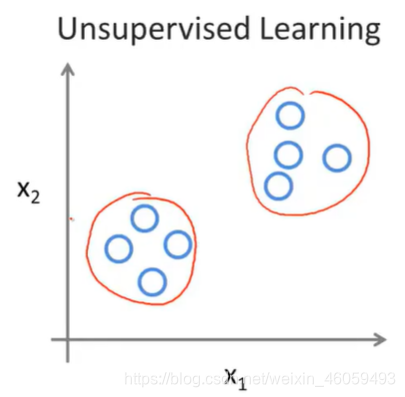
第一张图中,样本分别用o与x进行区分。而第二张图中的样本没有。因此非监督学习目标不是告诉计算机怎么做,而是让它(计算机)自己去学习怎样做事情。因此监督学习通常完成的任务是识别物品,并且贴上标签。而无监督学习实现的是找到其中的规律。如果发现数据集呈现某种聚集性,则可按自然的聚集性分类,但不予以某种预先分类标签对上号为目的。
笔记对应课程:吴恩达机器学习系列课程















 159
159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









