







文章目录
一,第一范式
如果某个域中元素被认为是不可分的,则这个域称为是原子的
- 非原子域的例子:
---- 复合属性:名字集合
---- 多值属性:电话号码
---- 复合数据类型:面向对象的
如果关系模式R中的所有属性的域是原子的,则R称为属于第一范式(1NF)
非原子值存储复杂并易导致数据冗余
- 我们假定所有关系都属于第一范式
如何处理非原子值
- 对于组合属性:让每个子属性本身称为一个属性
- 对于多值属性:为多值集合中的每个项创建一条元组
原子性实际上是由域元素在数据库中被使用决定的
- 例,字符串通常是被认为是不可分割的
- 假设学生被分配这样的标识号:CS0012或EE1127,如果前两个数字表示系所,后四位表示学生在该系所内的唯一号码,则这样的标识号不是原子的
- 当采用这种标识号时,是可取的。因为这需要额外的编程,而且信息是在应用程序中,而不是在数据库中编码。
二,关系数据库设计中易犯的错误
关系数据库设计要求我们找到一个“好的”关系模式集合。一个坏的设计可能导致:
- 数据冗余
- 插入、删除、修改异常
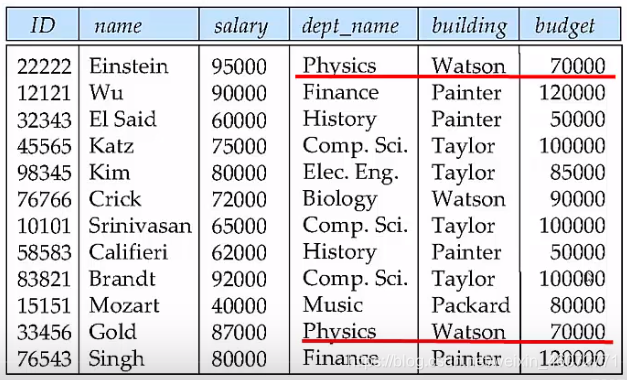
假设我们用以下模式代替instructor模式和department模式:
inst_dept(ID, name, salary, dept_name, building, budget)
2.1 数据冗余
每个系的dept_name,building,budget数据都要重复一次
缺点:浪费空间,可能会导致不一致问题
2.2 插入、删除、修改异常
更新异常
- 更新复杂,容易导致不问题。
- 例修改
dept_name,很多相关元组都需要修改。
插入/删除异常
- 使用空值
null:存储一个不知道所在系所的教师信息,可以使用空值表示dept_name,building,budget数据,但是空值难以处理。
三,模式分解(I)
例,可以将关系模式(A,B,C,D)分解为:(A,B)和(B,C,D),或(A,C,D)和(A,B,D),或(A,B),(B,C)和(C,D)等等…
例,将关系模式inst_dept分解为:
instructor(ID, name, dept_name, salary)department(dept_name, building, budget)
原模式(R)的所有属性都必须出现在分解后的(R1,R2)中:R = R1 ∪ R2
无损连接分解
- 对关系模式R上的所有可能的关系r
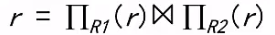
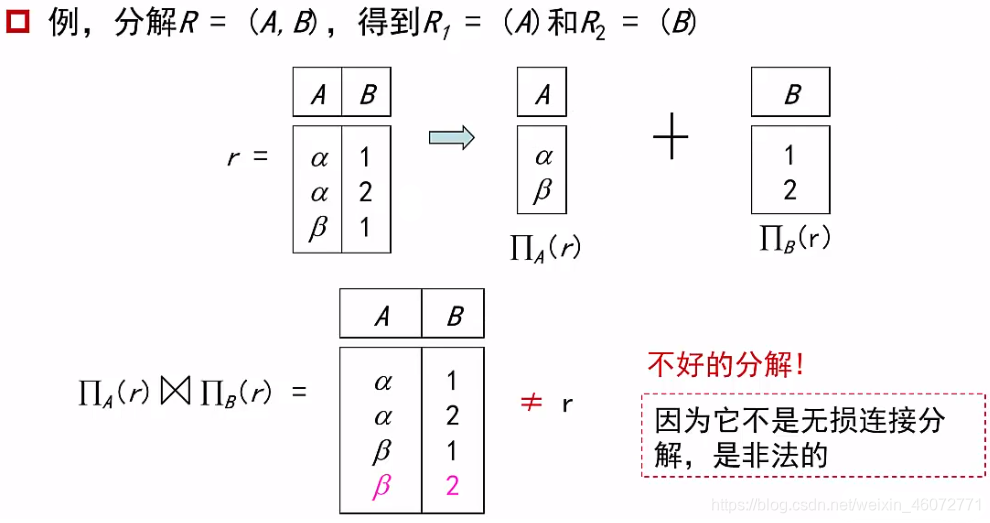
目标:设计一个理论
- 以判断关系模式R是否为“好的”形式(不冗余)
- 当R不是“好的”形式时,将
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2212
2212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









