






首先指出问题:现有的描述符学习框架通常需要用于训练的特征点之间的地面真实对应关系,但是获取大规模这样的数据是困难的,作者提出了一种基于从图像之间的相对相机姿态学习特征描述符,利用极线约束来约束网络学习方向。
代码过程讲解可以看Learning Feature Descriptors using Camera Pose Supervision阅读笔记(代码版)-CSDN博客
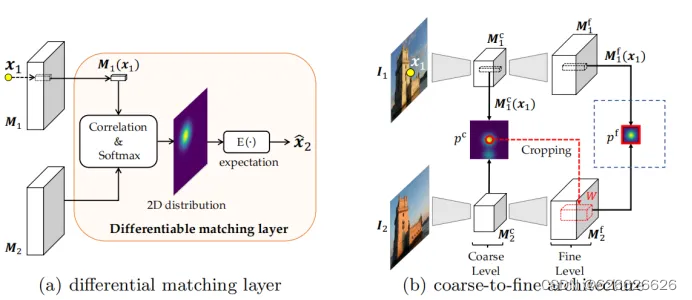
网络模型
作者使用的是ResNet50网络的前三个模块,输入图像x(480*640)batchsize=5,x1是经过网络第一个模块输出的,首先经过初始的卷积和池化,分辨率降到原来的1/4,然后经过第一层x1为(5,256,120,160),x2为第二个模块输出,x2为(5,512,60,80),然后经过第三个模块为x3,x3为(5,1024,30,40),共享网络到此结束,下面是输出粗级别图和细级别图。
x3经过一个1*1的卷积核的卷积层,输入通道为1024,输出通道为128,然后经过一个bn层和激活层得到粗级别图为xc(5,128,30,40)。
细级别图,x3经过一个上采样过程使用插值方法,变为(5,1024,60,80)在经过一个卷积核为3*3的卷积层添加Padding输入通道为1024,输出为512,变为(5,512,60,80),这个时候再与x2进行通道维度的拼接变为(5,1024,60,80),再通过一个3*3卷积核的卷积层,添加padding,输入通道1024,输出通道为512变为(5,512,60,80),然后再经过一个上采样过程使用插值方法,变为(5,512,120,160)在经过一个卷积核为3*3的卷积层添加Padding输入通道为512,输出为256,变为(5,256,120,160),这个时候再与x1进行通道维度的拼接变为(5,512,120,160),再通过一个3*3卷积核的卷积层,添加padding,输入通道512,输出通道为256变为(5,256,120,160),最后再经过一个1*1卷积核的卷积层,输入通道为256输出通道为128,变为xf(5,128,120,160)。
xc为粗级别图,分辨率为原图大小的1/16,xf是细级别图分辨率为原图大小的1/4。

至此粗级别图分辨率是(30,40)原图边长的1/16,细级别图是(120,160)原图边长的1/4。其中粗级别图上面已经介绍怎么出来的,就是经过ResNet50网络的前三个模块后再经过一个卷积bn和池化,而细级别图是经过上采样跳跃连接卷积等操作。
损失函数:
极线距离约束,其中h1->2(x1)是第一张图特征点x1对应第二张图的期望点x2,表示x2距离极线Fx1的距离,其中基础矩阵Fx1就是x2的极线。
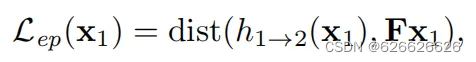
但是只有这样不太行,他只会使网络朝着靠近极线去而不会靠近对应的点,所以需要一个反投影操作,仅使用极线损失只会鼓励预测的匹配点位于极线上,而不是靠近地面真实对应位置(该位置位于极线上的未知位置)。为了提供额外的监督,我们额外引入了循环一致性损失。这种损失鼓励点的前向-后向映射在空间上接近自身。
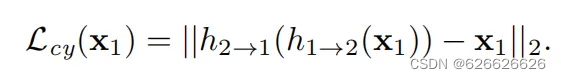
h2->(h1->2(x1))是将网络输出的第二张图对应的期望点再计算对应第一张图的点,然后将计算出的点与真实选中的特征点计算欧氏距离
所以损失函数又变为
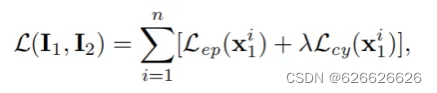
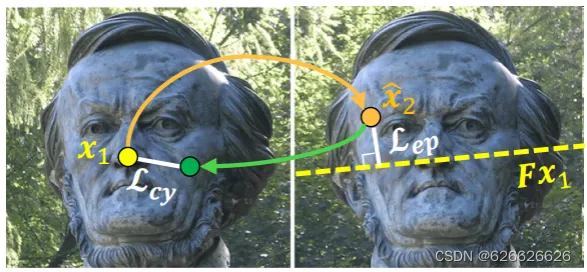
这个图就详细说明了上面的损失函数的计算过程。
计算对应点的方式是,在第一张图提取特征点可以使用随机也可以使用SIFT,但是在实际用于训练的点会经过一些检测剔除操作。
首先把提取的特征点坐标归一化到[-1,1],然后在粗级别图上(30,40,128)进行采样描述子,使用双线性插值。与第二张图的粗级别图进行相关性操作(内积),并且进行softmax操作,接着使用每个点的坐标乘上每个点的概率,得到最终的期望点。

其中M1是第一张图中特征点描述符,M2是第二张图描述符。
上面的x2=h1->2(x1)就是这样计算的
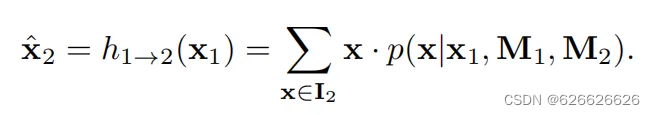

因为如果分布比较集中的话他的标准差就小,如果分布不集中们就证明概率不是在一个区域出现大值,说明就置信度不高,所以加上方差置信度最终损失函数。

求倒数,因为标准差大的表示预测不准确,标准差小的表示预测准确,标准差较小的样本可能对模型的训练贡献更大,因为它们代表着相对“容易”预测的情况。相反,标准差较大的样本可能对模型的训练贡献较小,因为它们代表着相对“困难”预测的情况。
本文为了减少计算量,提出了一种由粗到细的匹配方法,先在粗级别图上匹配得到一个期望点,然后根据这个期望点在细级别图上开辟一个窗口(细级别图边长的1/8)进行匹配.上面那个损失函数在粗和细级别都会训练反向传播。
这篇论文阅读感想:
1.展示了仅使用相机姿态就足以学习到良好的描述符
2.设计了新的损失函数极线约束和反投影计算点之间的欧氏距离,仅需要相机相对姿态就可以训练。
3.使用了从粗到细降低计算成本。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









