






本文提出了一个使用注意力机制进行特征融合的方法,通常情况下,特征融合通过简单的操作实现,例如求和或拼接,但这可能不是最佳选择,这仅仅提供了特征图的固定线性聚合,并且完全不知道这种组合是否适用于特定对象。
特征融合应用:ResNet跳跃连接,多分支并行特征融合(不同感受野),长跳连连接(例如金字塔不同尺度融合)
由于之前的注意力机制例如SENet,直接进行空间维度的池化操作,这种操作只聚焦于图像中的大目标,因为大目标占据的像素多,而小目标可能就会被忽略,为了缓解由尺度变化和小对象引起的问题,作者提倡这样一种想法,即注意力模块应该也应该从不同的感受野中聚合上下文信息,以适应不同尺度对象的特征不一致性。尺度不仅仅是空间注意力的问题,通道注意力也可以具有不同于全局的尺度,通过变化空间池化大小。
首先提出了一个新的注意力机制模块名为MS-CAM
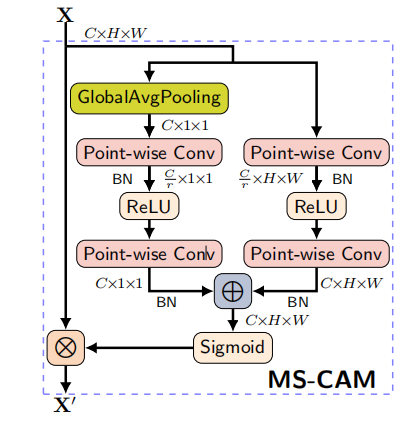
这是一个两分支的注意力机制模块,一个分支就是类似于SEnet,直接在空间维度进行最大池化,这是代表全局信息。另一个分支是不进行降维,直接在原始输入上进行逐点卷积,这个是局部感受野的分支,代表局部信息。第一个分支是全局分支进行通道维度交互,第二个是通道局部维度交互,第一个分支得到的维度是B*C*1*1,第二个分支得到的是和输入一样的形状B*C*H*W
不同特征融合结合这个注意力机制框架如下
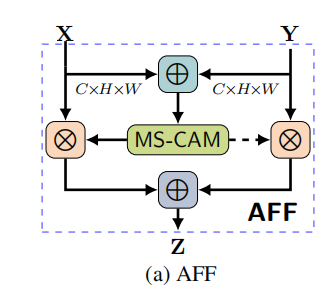
X和Y是不同的特征(例如X是3*3卷积得到的特征,Y是7*7卷积得到的特征,X和Y是并行分支),把X和Y相加传入到MS-CAM注意力模块中,输出为一个张量M为B*C*H*W,则X与M逐点相乘,Y与(1-M)逐点相乘,最后相加。
公式可以表示为
![]()
其中
![]()
表示如何整合X和Y,通常是直接相加。
但是除了注意力模块的设计之外,作为其输入的初始集成方法也对融合权重的质量产生很大影响。考虑到特征可能在尺度和语义水平上存在很大的不一致性,忽视这个问题的不成熟的初始集成策略可能成为一个瓶颈。(通俗的说就是如何初始整合X和Y不好的话,那么注意力机制模块可能也效果不太好),所以只需将现有的特征融合操作替换为所提出的AFF模块。此外,AFF框架支持逐步改进初始集成,即融合权重生成器的输入,通过迭代地将接收到的特征与另一个AFF模块集成,我们将其称为迭代注意力特征融合(iAFF)。
框架图如下:
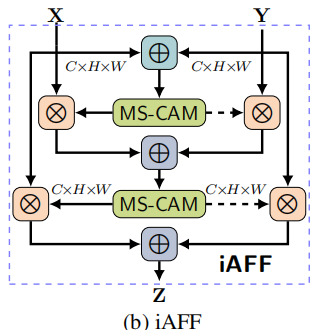
先将X和Y经过一次上述的AFF操作,得到的初始整合特征,再将整合后的特征再次输入到AFF中。
代码如下,自定义X1,X2测试
import torch.nn as nn
import torch
class DAF(nn.Module):
'''
直接相加 DirectAddFuse
'''
def __init__(self):
super(DAF, self).__init__()
def forward(self, x, residual):
return x + residual
class iAFF(nn.Module):
'''
多特征融合 iAFF
'''
def __init__(self, channels=64, r=4):
super(iAFF, self).__init__()
inter_channels = int(channels // r)
# 本地注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 第二次本地注意力
self.local_att2 = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 第二次全局注意力
self.global_att2 = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = xl + xg
wei = self.sigmoid(xlg)
xi = x * wei + residual * (1 - wei)
xl2 = self.local_att2(xi)
xg2 = self.global_att(xi)
xlg2 = xl2 + xg2
wei2 = self.sigmoid(xlg2)
xo = x * wei2 + residual * (1 - wei2)
return xo
class AFF(nn.Module):
'''
多特征融合 AFF
'''
def __init__(self, channels=64, r=4):
super(AFF, self).__init__()
inter_channels = int(channels // r)
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = xl + xg
wei = self.sigmoid(xlg)
xo = 2 * x * wei + 2 * residual * (1 - wei)
return xo
class MS_CAM(nn.Module):
'''
单特征 进行通道加权,作用类似SE模块
'''
def __init__(self, channels=64, r=4):
super(MS_CAM, self).__init__()
inter_channels = int(channels // r)
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
xl = self.local_att(x)
xg = self.global_att(x)
xlg = xl + xg
wei = self.sigmoid(xlg)
return x * wei
# 创建输入张量 x1 和 x2
x1 = torch.randn(2, 64, 120, 160)
x2 = torch.randn(2, 64, 120, 160)
# 实例化模型
daf_model = DAF()
aff_model = AFF(channels=64, r=4)
iaff_model = iAFF(channels=64, r=4)
ms_cam_model = MS_CAM(channels=64, r=4)
# 计算输出
daf_output = daf_model(x1, x2)
aff_output = aff_model(x1, x2)
iaff_output = iaff_model(x1, x2)
ms_cam_output = ms_cam_model(x1) # 注意,MS_CAM 只需要一个输入
# 打印输出形状
print('DAF output shape:', daf_output.shape)
print('AFF output shape:', aff_output.shape)
print('iAFF output shape:', iaff_output.shape)
print('MS_CAM output shape:', ms_cam_output.shape)
















 3247
3247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









