






论文主要提出了:
1.提出了一个可微分的关键点检测模块,并引入了重投影损失和离散度峰值损失,用于准确和可重复的关键点训练。
2.采用了NRE 损失来训练估计的密集描述符图,使得模型的收敛性比使用三元损失更稳定
3.设计了一个轻量级网络,汇聚了分层特征,用于高效的关键点检测和描述符提取
网络结构

输入图像I(H,W,3),网络首先估计出一个得分图S(H,W)和一个描述符图D(H,W,dim),然后使用(DKD) Differentiable Keypoint Detection从分数图中检测亚像素关键点p=[u,v]T,并从D中采样其对应的描述符d(dim)。
其中上图(a)是特征编码器,他包含了四个模块,第一个模块是conv(3*3)+relu+conv(3*3)+relu,后三个模块包含一个max-pooling+的基本ResNet块(3*3),第二个模块下采样率为1/2,,后两个是1/4.
(b)阶段是特征聚合模块,对每一个模块的输出都上采样到H*W的分辨率大小,然后分别使用一个1*1的conv来调整通道数,调整完通道数把他们拼接到一起成为(H,W,dim)。
(c)把b阶段拼接到的(H,W,dim)经过一个1*1的conv把通道数调整为dim+1,其中前dim个通道经过L2归一化得到D描述符图(H,W,dim),然后最后一个维度经过sigmoid激活函数输出成为(H,W,1)分数图S
(d)把S输入到DKD模块检测亚像素关键点,然后从密集描述符图 D 中对它们进行采样。
Differentiable keypoint detection module(DKD)
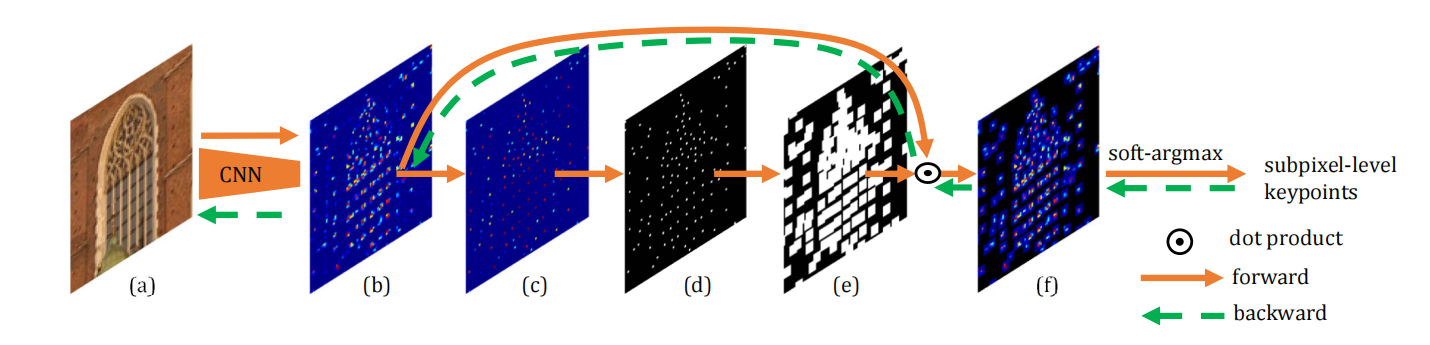
因为只在区域内进行NMS是不可微的,所以文中提出使用softargmax来从局部窗口中提取可微分的关键点,
(a)是原始输入图像,(b)是得分图S,接着使用NMS在图像中N*N的局部窗口中选择出关键点得到(c),然后在得到的(c)图上应用阈值th过滤掉低响应分数得到(d),其中(d)中得到的点被存储为[u,v]T(NMS),然后将这些点作为中心点在(c)图中提取N*N大小的局部窗口(e),对窗口中的分数进行softmax归一化:
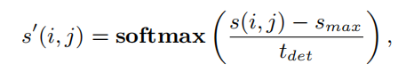
(f)局部窗口中的得分
其中tdet是温度参数。
然后经过积分回归

得到偏移量。
(因为窗口是以[u,v]T(NMS)为中心,窗口中心点坐标为(0,0),所以这个积分回归就得到了相对于[u,v]T(NMS)的偏移量)
现在,输出的亚像素级关键点给出如下:
![]()
Learning accurate keypoints
准确的关键点应该精确地位于可重复的位置,所以在这个阶段文中提出了重投影损失和分散性峰值损失。重投影损失直接优化关键点的位置,而分散性峰值损失确保分数在关键点位置处最大化,从而产生准确的关键点。
重投影损失
对于两个图像IA和IB,网络估计他们的分数图为SA和SB,DKD模块提取的关键点为PA和PB,将PA投影到图像IB上PAB=warp(PA),其中warp可以是单应性投影、三维透视投影等。
损失:对于一个经过变换的点PAB,在距离一个阈值thgt像素距离内找到其最近的检测到的关键点PB作为其对应的关键点,然后PAB和PB的重投影距离定义为:
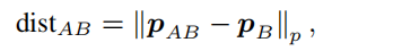
所以最终的重投影损失被定义为:
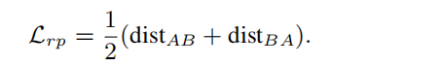
它隐含地提供了关键点的可重复性,因为在不可重复的区域中的关键点会导致较大的重投影误差。
分散性峰值损失
这个提出的原因是因为得分图中关键点应该具有高得分,周围应该具有低分数,之前的工作中都是通过最大值和平均值之间的差异进行规范化的,但是这只是对分数块的统计特性进行规范化,忽略了分数的空间分布。
考虑一个N*N大小的分数块,计算其中每个像素点[i,j]到软检测到的关键点
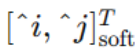
(相对于中心点的偏移)的距离

然后这个N*N分数块的分散性峰值损失定义为:
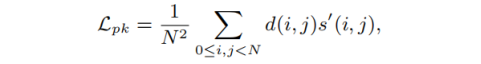
其中,肯定是原点(i,j)的得分最大,d(i,j)如果距离原点越近,那么损失=距离*得分肯定就越小,而偏移越小就证明这个经过NMS和阈值抑制得到的关键点得分要远高于周围,这个损失函数考虑了整个图像块中的空间得分分布
Learning discriminative descriptor
描述符区分性训练一般是通过三元组损失进行训练,但是三元组损失只优化从关键点采样的稀疏描述符,因此密集描述符图不能被完全约束,三元组损失仅使用图中的两个点的描述符:对应点 pAB 的描述符和最难的负例点的描述符。
为了解决这个问题,本文采用了 NRE 损失来与密集描述符图进行训练。它最小化了密集投影概率图与密集匹配概率图之间的交叉熵差异,从而为密集描述符图提供全面的约束,以及稳定的训练过程。
密集投影概率图
对于图像A中的关键点pA及其在图像B中的重新投影关键点pAB,重新投影概率图由pAB通过双线性插值定义:

每一个点对应一个密集投影概率图,PB代表图像中每一个像素点,每一个像素点都会通过双线性插值得出一个投影概率。
如果PA投影不到图像B的图像上,那么这个点PA对应的投影概率图则每个点全部为1(异常值)
最终得到密集投影概率图qr
密集匹配概率图
对于关键点PA的描述符dPA(dim)和密集描述符DB(H,W,dim),他们的相似度映射为

再次还添加了一个异常类别out来处理当描述符dPA在描述符DB中没有对应描述符的情况

其中CdPA,DB中包含H*W+1个元素,然后对CdPA,DB进行softmax归一化

得到qm就是密集匹配概率图
NRE损失通过交叉熵(CE)最小化了再投影概率图和匹配概率图之间的差异。


所以上面那个损失就是在计算-qr*ln(qm),当他们大值位置比较接近的时候这个损失函数就小

Learning reliable keypoint
再投影和散度峰值损失提供了准确且可重复的关键点。然而,描述符图的空间特性没有被考虑进去,可能关键点采集的位置位于低纹理区域,为了解决这个问题引入了一个新的损失。
通过匹配概率图qm,对qm进行双线性采样,采样的位置是PAB(A到B的投影)
因为这个匹配概率图是描述符之间的匹配概率,从这个图中可以看出描述符的相似性,如果一块区域匹配概率都较高而不是单独高,那么证明这个点附近像素比较相似,所以描述符也比较相似,那么可能就是天空这样的区域,不利于匹配。
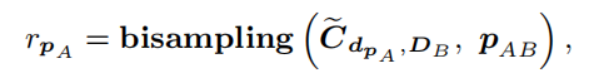
直观的说rPA评估了PA的匹配质量,如果PA处于不可靠的低纹理或者重复区域,那么该区域的整体相似度更高,所以采样得到的rPA会比较小,表明PA不可靠。
因为采样的时候,靠近点的位置权重高,越远则权重越低。
损失函数为:
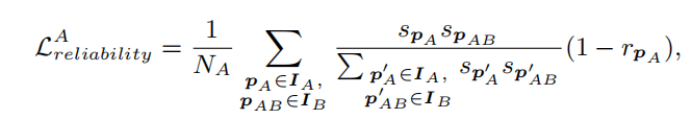
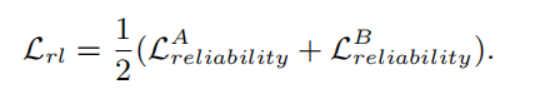
最终的总体损失函数为
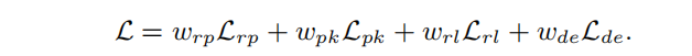
当rPA低的时候,为了使损失降低,那么就会使得这两个点的得分降低.
wrp = 1,wpk = 1,wrl = 1,wde = 5。
总结
在本文中,提出了ALIKE,一种端到端的准确且轻量级的关键点检测和描述符提取网络。它使用可微分的关键点检测模块来检测准确的亚像素关键点。然后利用提出的重投影损失和分散性峰值损失来训练关键点。除了关键点外,还使用NRE损失来训练具有辨别性的描述符,并提出了可靠性损失来强制关键点的可靠性。















 4090
4090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









