







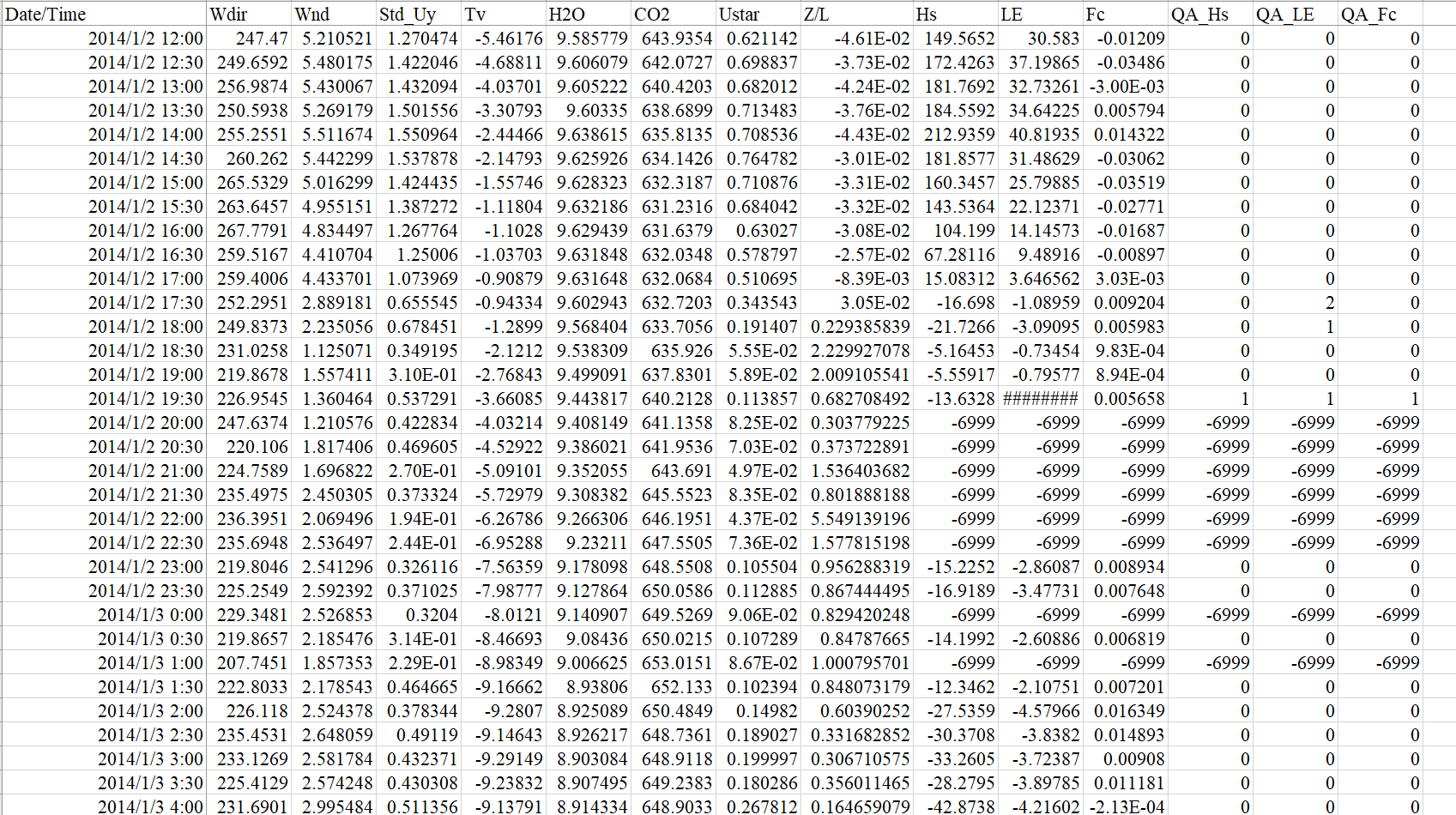
目标:将数据中某时刻的缺失值用前后4天相同时刻值的平均值进行填充
日平均变化法插值
变量的日变化是有规律性的,相邻天的变量量级水平都是一样的(特殊天除外),所以,当某天某一时刻的数据缺失时,可以用相邻几天的有观测数据的平均值来代替。这个时间窗口一般取7-14天,不同的变量时间窗口宽度可以不一样。根据算法的不同,该方法又可分为“独立”窗口和“滑动”窗口。
独立窗口和滑动窗口(图源朱治林老师)
参考
(2条消息) 用python从日期中获取年、月、日、星期等30种信息_python技巧(数据分析及可视化)的博客-CSDN博客_python年月日,(2条消息) Python时间序列--滑动窗口(三)_猫小咪编程的博客-CSDN博客_python 图像时间序列滑动时间窗,(2条消息) Python对时间数据进行运算_佐佑思维的博客-CSDN博客_python 时间运算,(2条消息) 【吃饱没事干Python】列表中空值nan的苦恼(已解决)_AI_Clay的博客-CSDN博客_python输出nan怎么解决
代码
# -*- coding: utf-8 -*-
"""
利用平均日变化方法——滑动窗口——9天的窗口——前后4天——进行数据插补
这里填充的是LE
YMJ, 20230119, 10:25
"""
import numpy as np
from numpy import *
import pandas as pd
import os
import datetime
from datetime import datetime, date, timedelta
from pandas import DataFrame, Series
from itertools import chain
file = 'D:\\YMJ_file\\test\\fluxdata_process\\2014年四道桥超级站通量气象30分钟数据.xlsx'
data = pd.read_excel(file)
# 获取'LE' = -6999的所有数据行
data1 = data.loc[(data['LE'] == -6999)]
# 遍历DataFrame中的“Date/Time”列,产生每一数据行前4天、后4天的时间戳,相当于有了索引
for index, row in data1.iterrows():
time = row["Date/Time"]
time1 = time - timedelta(days=4)
time2 = time - timedelta(days=3)
time3 = time - timedelta(days=2)
time4 = time - timedelta(days=1)
time6 = time + timedelta(days=1)
time7 = time + timedelta(days=2)
time8 = time + timedelta(days=3)
time9 = time + timedelta(days=4)
# 根据产生的时间戳,提取那一时刻的LE值,数据格式是series,先转为list
LE1 = data[(data.Date == time1)]["LE"]
LE1 = Series.tolist(LE1)
LE2 = data[(data.Date == time2)]["LE"]
LE2 = Series.tolist(LE2)
LE3 = data[(data.Date == time3)]["LE"]
LE3 = Series.tolist(LE3)
LE4 = data[(data.Date == time4)]["LE"]
LE4 = Series.tolist(LE4)
LE6 = data[(data.Date == time6)]["LE"]
LE6 = Series.tolist(LE6)
LE7 = data[(data.Date == time7)]["LE"]
LE7 = Series.tolist(LE7)
LE8 = data[(data.Date == time8)]["LE"]
LE8 = Series.tolist(LE8)
LE9 = data[(data.Date == time9)]["LE"]
LE9 = Series.tolist(LE9)
# 将产生的数据都存放进一个空列表,并且是迭代一次清空一次列表
LE = []
LE.append(LE1)
LE.append(LE2)
LE.append(LE3)
LE.append(LE4)
LE.append(LE6)
LE.append(LE7)
LE.append(LE8)
LE.append(LE9)
# 将大列表中的小列表都提取出来,最终变成一个列表
LE = list(chain.from_iterable(LE))
# 对列表中的元素进行判断,产生一个不包含-6999值的列表,计算平均值
LE_new = [item for item in LE if item != -6999]
LE5 = mean(LE_new) # LE5是numpy.float64
# 将插补的数据填补进DataFrame中
data.loc[data.Date == time,"LE"] = LE5
LE = []
# 插值后的数据写进文件
data.to_excel(file)
















 2195
2195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









