







分享一款开源的中文文本加噪的数据增强工具,此处链接。
该工具主要实现以下功能:
- 分别实现了四种加噪方法,即冗余、缺失、选词、词序,并实现了一种综合加噪方法,即随机选择以上四种加噪方法进行加噪。
- 分别从字词粒度进行加噪,并非单一地选择字/词,从而使得文本更加细粒度。
- 实现了一种复制累加机制,即首先将源端数据进行复制,对前四份分别加上不同类型的错误,对最后一份数据加上所有类型的错误。针对每份语料,首先进行词粒度噪声化,然后进行字粒度噪声化,将这两个数据增强步骤统称为双重噪声化。最后,将这五份噪声化后的语料进行叠加,得到最终的加噪语料。
该数据增强方法十分实用,在文本生成任务上均可以使用,如机器翻译、文本摘要、语法纠错等,目前在机器翻译和语法纠错上做过实验,取得不错的效果。
用法
- 配置相应环境,此处不赘述,具体参考链接下的README.md。
- 简单使用方法
bash noise.sh
具体使用方法python add_noise/add_noise.py --input input_file_path --redundant_probability 0.2 --selection_probability 0.2 --missing_probability 0.2 --ordering_probability 0.2 --comprehensive_error_probability 0.2
结果
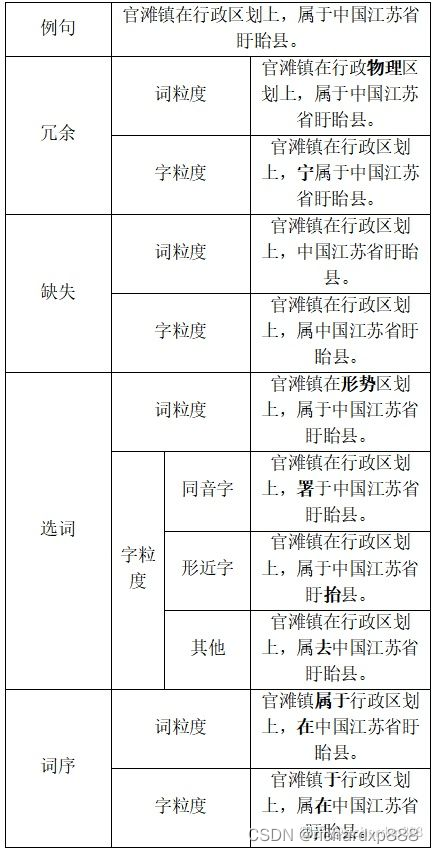
生成的加噪文本如上图所示,分别从字词粒度实现了四种加噪方式。
并且在NLPCC2018数据集上利用该工具进行了中文语法纠错的实验,实验结果以 F 0.5 F_{0.5} F0.5计算,模型选择的是Vaswani et al. (2017)提出的Transformer model,这里选择的base配置。
| Model | Scores |
|---|---|
| baseline | 33.17 |
| baseline+noise | 35.55 |
引用
@misc{Xia2022,
author = {Peng Xia},
title = {Chinese-Noisy-Text},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/Richard88888/Chinese-Noisy-Text}},
commit = {602a630730ce8b61ea8882251e5516ad1930fa43}
}
@inproceedings{tang2021基于字词粒度噪声数据增强的中文语法纠错,
title={基于字词粒度噪声数据增强的中文语法纠错 (Chinese Grammatical Error Correction enhanced by Data Augmentation from Word and Character Levels)},
author={Tang, Zecheng and Ji, Yixin and Zhao, Yibo and Li, Junhui},
booktitle={Proceedings of the 20th Chinese National Conference on Computational Linguistics},
pages={813--824},
year={2021}
}
















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











